






这篇文章主要讲述了爬取北京市公交线路信息的整个过程,对于小白还是极为友好的,细节解释的比较详细,话不多说,开始探索知识吧。
一、Xpath插件
1、文件夹格式插件安装
1.首先用户点击谷歌浏览器右上角的自定义及控制按钮,在下拉框中选择设置。
2.在打开的谷歌浏览器的扩展管理器最左侧选择扩展程序。
3.勾选开发者模式,点击加载已解压的扩展程序,将文件夹选择即可安装插件。
2、使用方式
(1)打开方式快捷键
Ctrl+Shift+X,如果打不开,就重新加载一下
(2)取元素的XPath
按住Shift键,将鼠标移到需要定位的元素上,该元素会以黄色底纹高亮。左边的XPath编辑框内会显示该元素的XPath路径,右边的节点文本显示框会显示该元素的文本内容。
(3)检验XPath路径
在编辑框内输入自己事先写好的XPath路径,检查书写是否有误。
二、爬取第一页所有的导航链接
以爬取数字1开头的公交线路为例,一级网页:beijing.8684.cn/,二级网页:beijing.8684.cn/list1,就多了一个/list1,所以就要在一级网页中找到/list1,在一级网页基础上加上即可,其余以此类推。那么如何准确找到以1开头的公交线路的/list1呢,用xpath。
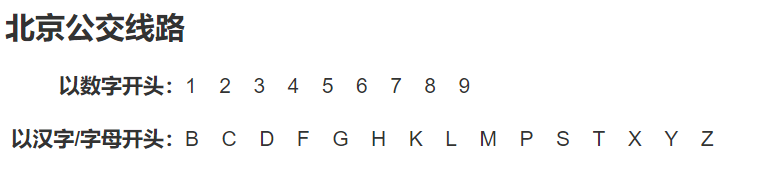


代码解读为://div[@class=“bus-layer depth w120”]表示要获取class="bus-layer depth w120"下面的值,/div[1]表示获取class="bus-layer depth w120"下面第一个div的值,/div/a/@href表示获取div下a中herf的值,也就是/list1,可以找到lint1-9共9个结果,分别对应1-9开头的公交车。总之就是从上到下,层层递进,找到你唯一想找到的东东,可以通过/div[@]直接取值,也可以通过div[1]索引取值。
#爬取第一页所有的导航链接
def parse_navigation():
url = 'https://beijing.8684.cn/'
req = requests.get(url, headers=headers)
#解析内容,获取所有的导航链接
tree=etree.HTML(req.text)
#查找以数字开头的所有链接
number_herf_list=tree.xpath('//div[@class="bus-layer depth w120"]/div[1]/div/a/@href')
#查找以字母开头的所有链接
char_herf_list=tree.xpath('//div[@class="bus-layer depth w120"]/div[2]/div/a/@href')
#将所有爬取到的链接返回
return number_herf_list+char_herf_list
# return number_herf_list运行结果:

三、爬取二级页面,需要找到以1开头的所有路线的url
思路与上面一致,先看看该网页与上级网页网址有什么区别,一级网页:beijing.8684.cn/,三级页面:https://beijing.8684.cn/x_322e21c5,现在的目标就是爬取以1开头所有公交车的值,为请求三级页面打基础。
遍历上面的列表,依次发送请求,解析内容,获取每一个页面所有公交线路的url,先进入二级网页,再解析二级网页的内容。
二级页面:

def parse_erji(navi_list):
# 遍历上面的列表,依次发送请求,解析内容,获取每一个页面所有公交线路的url
for first_url in navi_list:
first_url='https://beijing.8684.cn'+first_url
print("开始爬取%s所有公交信息" % first_url)
r=requests.get(first_url,headers=headers)
#解析内容,获取每一路公交的详细url
parse_erji_route(r.text) #解析一下r的内容
print("结束爬取%s所有公交信息" % first_url)
xpath的获取方式与一级页面一致,见上图。
def parse_erji_route(content):
tree=etree.HTML(content)
#写xpath,获取每一个线路
route_list=tree.xpath('//div[@class="cc-content"]/div[2]/a/@href')
route_name = tree.xpath('//div[@class="cc-content"]/div[2]/a/text()')
i=0
#遍历上面这个列表
for route in route_list:
print("开始爬取%s线路" % route_name[i])
route='https://beijing.8684.cn'+route
r=requests.get(route,headers=headers)
# 解析内容,获取每一路公交的详细信息
parse_sanji_route(r.text)
print("结束爬取%s线路" % route_name[i])
i+=1四、进入三级页面,爬取需要的东东
第三步已经找到了进入三级页面的url了,这个适时候我们就应该享受胜利的果实了。立即推=进入三级页面,爬取我们需要的东东。话不多说,先看看三级页面的样子吧。


找到需要爬取内容的源码,这个xpath怎么写都行,只要能找到唯一对应的那个东东就中,比如我们需要线路运行时间,代码如下:
run_time=tree.xpath('//ul[@class="bus-desc"]/li[1]/text()')[0][5:]
//ul[@class=“bus-desc”]/li[1]是追踪到那个目录下,/text()是获取到里面内容:运行时间:老山公交场站5:00-23:00|四惠枢纽站5:00-23:00;tree.xpath(’//ul[@class=“bus-desc”]/li[1]/text()’)返回的是一个列表,[0][5:]是获取里面第一个值,第一个值中从第5个字符以后的内容,也就是:老山公交场站5:00-23:00|四惠枢纽站5:00-23:00。
代码:
def parse_sanji_route(content):
tree=etree.HTML(content)
#获取公交线路信息
bus_num=tree.xpath('//h1[@class="title"]/text()')[0]
#获取公交运行时间
run_time=tree.xpath('//ul[@class="bus-desc"]/li[1]/text()')[0][5:]
#获取票价信息
ticket_info=tree.xpath('//ul[@class="bus-desc"]/li[2]/text()')[0][5:]
#获取更新时间
gxsj=tree.xpath('//ul[@class="bus-desc"]/li[4]/text()')[0][5:]
# 获取起始站点
start_finsh = tree.xpath('//div[@class="layout-left"]/div[@class="bus-excerpt mb15"][1]/div/div[2]/text()')[0]
num=tree.xpath('//div[@class="bus-excerpt mb15"]')
if len(num)==2:
#获取上行总站数
up_total=tree.xpath('//div[@class="bus-excerpt mb15"][1]/div[2]/div/text()')[0]
#获取上行所有站名
up_site_list=tree.xpath('//div[@class="layout-left"]/div[@class="bus-lzlist mb15"][1]/ol/li/a/text()')
# 获取下行总站数
down_total = tree.xpath('//div[@class="bus-excerpt mb15"][2]/div[2]/div/text()')[0]
# 获取下行所有站名
down_site_liet = tree.xpath('//div[@class="layout-left"]/div[@class="bus-lzlist mb15"][2]/ol/li/a/text()')
#将每一条公交线路信息放到字典中
item={
"线路名":bus_num,
"运行时间": run_time,
"票价信息": ticket_info,
"更新时间": gxsj,
"上行站数": up_total,
# "上行站点": up_site_list,
"下行站数": down_total,
# "下行站点": down_site_liet,
"起始站点": start_finsh
}
else:
# 获取环形所有站名
circle_site_list = tree.xpath('//div[@class="layout-left"]/div[@class="bus-lzlist mb15"]/ol/li/a/text()')
# 获取环形总站数
circle_total = tree.xpath('//div[@class="bus-excerpt mb15"]/div[2]/div/text()')[0]
item = {
"线路名":bus_num,
"运行时间":run_time,
"票价信息":ticket_info,
"更新时间":gxsj,
"上行站数":circle_total,
"下行站数": "无",
"起始站点": start_finsh
# "环形站点":circle_site_list,
}
items.append(item)到此为止,我们所需要的东东就爬出来了,接下来,我们就要把它放到excle表格中去。
五、把内容导入excle
在这说明一下,这块一直没有找到特别固定的导入方式,因为偷懒用了个这,欢迎大家批评指正。
# 1.创建 Workbook
wb = xlwt.Workbook()
# 2.创建 worksheet
ws = wb.add_sheet('test_sheet')
# 3.写入第一行内容 ws.write(a, b, c) a:行,b:列,c:内容
ws.write(0, 0, '线路名')
ws.write(0, 1, '运行时间')
ws.write(0, 2, '票价信息')
ws.write(0, 3, '更新时间')
ws.write(0, 4, '上行站数')
ws.write(0, 5, '下行站数')
ws.write(0, 6, '起始站点')
# 保存文件
wb.save('北京公交详细信息.xls')
def main():
# with open('北京公交.txt', 'w', encoding='utf-8') as file:
try:
#爬取第一页所有的导航链接
navi_list=parse_navigation()
#爬取二级页面,需要找到以1开头的所有路线
parse_erji(navi_list)
# fp=open('郑州公交.text','w',encoding='utf8')
#爬取完毕
for i, item in enumerate(items):
ws.write(i + 1, 0, item['线路名'])
ws.write(i + 1, 1, item['运行时间'])
ws.write(i + 1, 2, item['票价信息'])
ws.write(i + 1, 3, item['更新时间'])
ws.write(i + 1, 4, item['上行站数'])
ws.write(i + 1, 5, item['下行站数'])
ws.write(i + 1, 6, item['起始站点'])
wb.save('北京公交详细信息.xls')
except requests.exceptions.ConnectionError:
print('Handle Exception')
except AttributeError as e:
print('Handle Exception')六、总结
最后,再简单的总结一下爬取多级页面的思路,请求访问一级网址—解析网站的内容—在一级网页的源码中找到二级网页的入口—请求访问二级网址—解析网站的内容—在二级网页的源码中找到三级网页的入口—往复循环—直到找到你要爬取内容的地方进行收割你想要的东东。欢迎大家批评指正。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









