







目录
数据集实战:收集、读取、预处理数据集,并且完成模型的搭建、训练工作。
Pokemon数据集


▪ 链接: https://pan.baidu.com/s/1V_ZJ7ufjUUFZwD2NHSNMFw
▪ 提取码:dsxl
总体的百分之60作train,百分之20作validation,百分之20作test。
Load data
inherit form torch.utils,data.Dataset,Dataset提供了一些通用的功能。
我们需要自己实现两个函数:_len_是数据集样本的数量,返回一个整型数字,接口_getitem_返回一个指定的x样本。
两大步骤,第一个我们需要实现怎么读取具体的样本,第二个是获取样本的数量。
Custom Dataset
class NumberDataset(Dataset):
def __init__(self,training=True):
if training:
self.samples=list(range(1,1001))
else:
self.samples=list(range(1001,1501))
def _len_(self):
return len(self.samples)
def _getitem_(self,idx):
return self.samples[idx]
首先要继承Dataset这个基本母类,然后完成两个函数_len_和_getitem_。
在初始化中,先把数据存储起来,创建一个1到1001的list,并且把它保存到类的成员变量self.samples上。
train时,就读取1到1001,test时读取1001到1501。
预处理preprocessing
网络的输入大小往往是固定的
- Image Resize
224×224 for ResNet18
当图片大小不符合要求时,需要Resize到固定的尺寸。
- Data Argumentation
Rotae
Crop
- Normalize
mean,std
把数据规范到0的附近,更有利于train
- ToTensor
转换成tensor类型。
root:首先我们需要找到数据集的位置。
resize:不同是网络输入的图片大小不一样,resize参数是针对所有网络而设置的。
mode:我们需要作train,validation和test,需要三种结构。
然后对数据集的每一个类进行一个映射,我们需要人为的把label编码好。
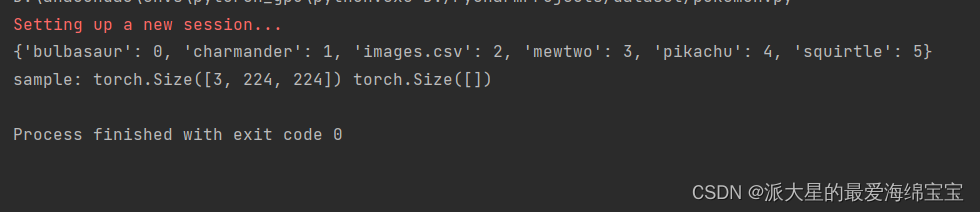
首先我们需要创建一个空字典,根据类名进行映射,例如把妙蛙种子映射为0。当我们遍历目录得到五种文件名,进行随机编码,先进来的是0,1,编码后固定。
首先遍历root目录下的文件,把目录名字过滤掉。
listdir()返回的顺序是不固定的,所以我们把它排序,排序后顺序固定。
name2label字典里有几个元素数,当前键的值就是几。

我们希望拿到文件后,数据对:image path+image label,因为一次性加载所有图片可能会爆内存。
遍历精灵类别后,使用glob.glob同时获取所有的匹配路径。并把当前文件内所有png、jpg、jpeg和gif格式的图片合并到images中。

我们的label信息根据路径得到,把所有信息保存在images.csv,里面是所有图片的地址和标签。
如果不存在,则先创建并保存在csv,接下来再进行读取。我们进行读取时,把每张图片的路径和label分别保存在images和labels中。
接下载进行类型的分类。
__getitem__函数:
我们需要使用transform和PIL方法根据路径把图片加载进来。
在transform中,我们先使用Image.open方法把图片加载,再convert成一个可以处理的类型RGB。
我们完成了三个大步骤,首先完成初始化工作,将图片信息进行储存,先人为的对标签进行编码也就是排序,再通过load_csv函数生成images和labels的信息。再根据mode把images和labels进行裁剪。然后完成len函数获得长度。最后完成getitem函数,通过索引得到图片地址信息和标签信息,然后再通过tramsform方法加载图片,并把图片和标签转换成可处理的tensor类型,返回。
先在终端查看是否已经安装visdom,然后 python -m visdom.server运行。
接下来进行可视化
viz.images(x,win='sample_x',opts=dict(title='sample_x'))
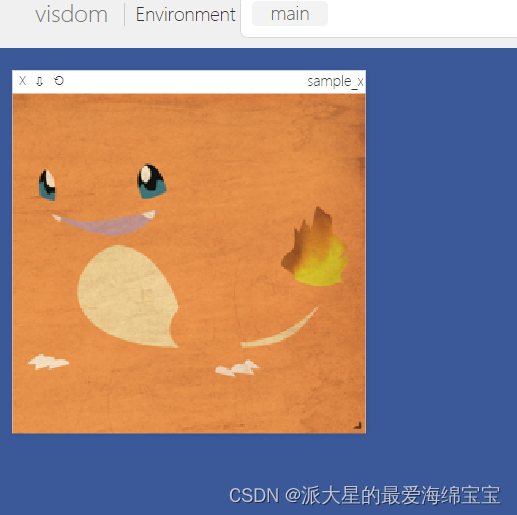

得到一张大小是224,标签为1的图片。
我们还需要完成一些预处理工作,把resize的尺寸变大.
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25)),interpolation=InterpolationMode.BICUBIC),
再做随机旋转,注意旋转角度过大时可能会造成网络不收敛的情况。
transforms.RandomRotation(15),
旋转后图片空白处会自动添黑,这是我们不希望有的,所以需要进行裁剪。
transforms.CenterCrop(self.resize),
最后还需要做normalize,把数据统一到0和1附近,范围变为-1到1。
transforms.Normalize(mean=mean,std=std)
visdom接受的范围是0到1,但是normalize后,数据范围是-1到1。因此我们需要denormalize。
在denormalize中,x_hat是我们normalize后的,normalize的原理是x_hot=(x-mean)/std,当我们需要原来的x时,只需要x=x_hot*std+mean。我们的mean和std是长度为3的标量,我们需要把它变成3维的,因此先成为tensor类型,在进行unsqueeze。
def denormalize(self,x_hat):
mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225]
#x_hot=(x-mean)/std
#x=x_hot*std+mean
#x:[c,h,w]
#mean:[3]=>[3,1,1]
mean=torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std=torch.tensor(std).unsqueeze(1).unsqueeze(1)
x=x_hat*std+mean
return x
我们需要加载大量图片,采用Dataloader进行实现。


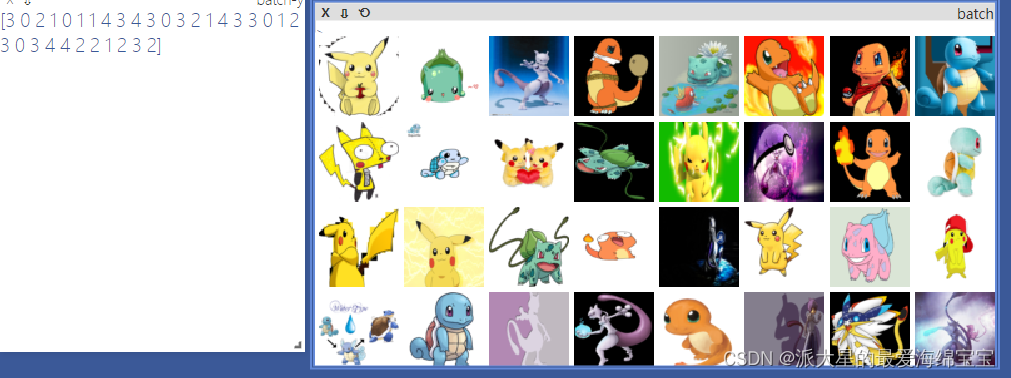
这是一个batch的图片,每10s更新一个batch。
如果你的文件夹名字对应的所有图片都在该文件夹内,这种类型的数据,可以使用Dafaloader中ImageFolder,一行可以解决。但是这种不是通用的,仅仅适应于该种类型。
import torchvision
viz=visdom.Visdom()
tf = transforms.Compose([
transforms.Resize((64,64)),
transforms.ToTensor(),
])
db=torchvision.datasets.ImageFolder(root='pokemon',transform=tf)
loader=DataLoader(db,batch_size=32,shuffle=True)
Build model
23的Resnet18
Train and Test
对于train的每个epoch,train后,进行validation,保存下最好的acc和epoch,再使用这个最好状态下的信息进行test。一般不需要对val和test数据集进行shuffle,需要全部进行测试。然后把模型放在cuda上,优化器一般优先选择Adam。计算loss采用CrossEntropyLoss,这个接收的参数就是logits,是不需要经过softmax的。
optimizer=optim.Adam(model.parameters(),lr=lr)
criteon=nn.CrossEntropyLoss()
在evaluate函数中,不需要做反向传播,所以放在torch.no_grad下。correct的值是通过前向传播计算出来的预测值pred,然后将pred和真实值y进行比较。
def evaluate(model,loader):
for x,y in loader:
correct=0
total=len(loader.dataset)
x,y=x.to(device),y.to(device)
with torch.no_grad():
logits=model(x)
pred=logits.argmax(dim=1)
correct=torch.eq(pred,y).sum().float().item()
return correct/total
对于最好的状态,除了保存best_acc,best_epoch,还要进行torch.save(model.state_dict(),‘best.mdl’),把当前信息存储在best.mdl,后缀名随意。
Transfer Learning
在A上train好一个分类器,再transfer到B上。对于B来说,其所含有的样本可能最好训练的结果也不及使用上述分类器刚开始训练结果,效果类似于站在巨人肩膀上vs从0开始。
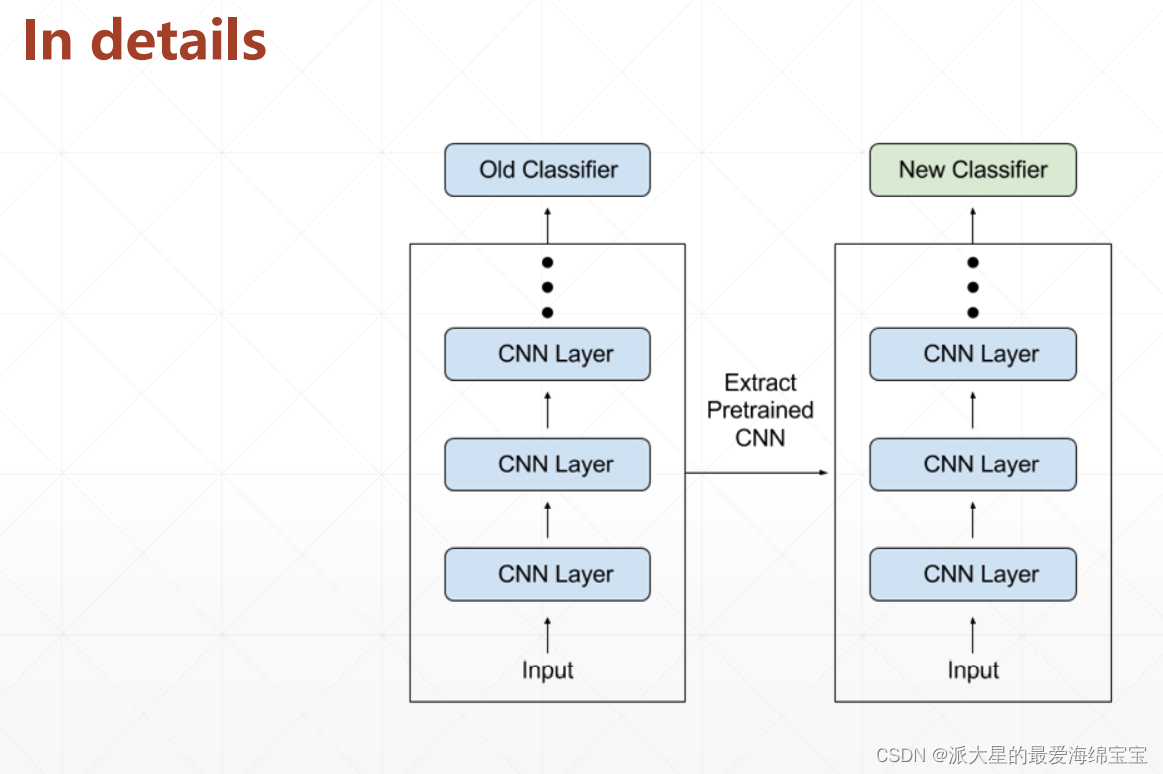
左面是已经train好的,把最后一层去掉,new classifier是随机初始化的,我们可以train这部分或者全部,效果会远远好于之前。
我们使用torchvision中带的resnet18,可以得到训练好的模型,体现在参数是非常好的状态。然后我们需要获取这些参数,假设只有18层,我们把前17层取出来,最后一层是我们需要重新学习的知识。Transfer Learning体现在这两行代码中:
trained_model=resnet18(pretrained=True)
model=nn.Sequential(*list(trained_model.children())[:-1],#输出为[b,512,1,1]
Flatten(),#[b,512,1,1]=>[b,512]
nn.Linear(512,5)
)
完整代码
load data
import torch
import os,glob
import random,csv
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
from PIL import Image
from torchvision.transforms import InterpolationMode
class Pokemon(Dataset):
def __init__(self,root,resize,mode):
super(Pokemon, self).__init__()
self.root=root
self.resize=resize
self.name2label={} #"sq..." :0
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.join(os.path.join(root,name)):
continue
self.name2label[name]=len(self.name2label.keys())
print(self.name2label)
self.images,self.labels=self.load_csv('images.csv')
if mode=='train': #60%
self.images=self.images[:int(0.6*len(self.images))]
self.labels=self.labels[:int(0.6*len(self.labels))]
elif mode=='val': #60%=>80%
self.images = self.images[int(0.6 * len(self.images)):int(0.8 * len(self.images))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: #80%=>100%
self.images = self.images[int(0.8 * len(self.images)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self,filename):
if not os.path.exists(os.path.join(self.root,filename)):
images=[]
for name in self.name2label.keys():
# 'pokemon\\mewto\\00001.png'
images+=glob.glob(os.path.join(self.root,name,'*.png'))
images+=glob.glob(os.path.join(self.root,name,'*jpg'))
images += glob.glob(os.path.join(self.root, name, '*jpeg'))
images += glob.glob(os.path.join(self.root, name, '*gif'))
print(len(images),images)
random.shuffle(images)
with open(os.path.join(self.root,filename),mode='w',newline='') as f:
writer=csv.writer(f)
for img in images:# 'pokemon\\mewto\\00001.png'
name=img.split(os.sep)[-2]
label=self.name2label[name]
# 'pokemon\\mewto\\00001.png',2
writer.writerow([img,label])
print('writen into csv file:',filename)
images,labels=[],[]
with open(os.path.join(self.root,filename)) as f:
reader=csv.reader(f)
for row in reader:
img,label=row
label=int(label)
images.append(img)
labels.append(label)
assert len(images)==len(labels)
return images,labels
def __len__(self):
return len(self.images) #此处不是1168,因为已经裁剪过
def denormalize(self,x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
#x_hot=(x-mean)/std
#x=x_hot*std+mean
#x:[c,h,w]
#mean:[3]=>[3,1,1]
mean=torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std=torch.tensor(std).unsqueeze(1).unsqueeze(1)
x=x_hat*std+mean
return x
def __getitem__(self, idx):
#idx:[0~len(self.images)]
#self.images,self.labels
#img:'pokemon\\mewto\\00001.png'
#label:0/1/2/3/4
img,label=self.images[idx],self.labels[idx]
tf=transforms.Compose([
lambda x:Image.open(x).convert('RGB'), #string path=>image data
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25)),interpolation=InterpolationMode.BICUBIC),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])
])
img=tf(img)
label=torch.tensor(label)
return img,label
def main():
import visdom
import time
import torchvision
viz=visdom.Visdom()
# tf = transforms.Compose([
# transforms.Resize((64,64)),
# transforms.ToTensor(),
# ])
# db=torchvision.datasets.ImageFolder(root='pokemon',transform=tf)
# loader=DataLoader(db,batch_size=32,shuffle=True)
#
# print(db.class_to_idx)
#
# for x,y in loader:
#
# viz.images(x,nrow=8,win='batch',opts=dict(title='batch'))
# viz.text(str(y.numpy()),win='label',opts=dict(title='batch-y'))
#
# time.sleep(10)
db=Pokemon('pokemon',224,'train')
x,y=next(iter(db))
print('sample:',x.shape,y.shape,y)
viz.images(db.denormalize(x),win='sample_x',opts=dict(title='sample_x'))
loader=DataLoader(db,batch_size=32,shuffle=True,num_workers=8)
for x,y in loader: #x,y是一个batch
viz.images(db.denormalize(x),nrow=8,win='batch',opts=dict(title='batch'))
viz.text(str(y.numpy()),win='label',opts=dict(title='batch-y'))
time.sleep(10) #每次加载完休息10s
if __name__ == '__main__':
main()
train and test
import torch
from torch import nn,optim
import torchvision,visdom
from torch.utils.data import DataLoader
from pokemon import Pokemon
from resnet import ResNet18
batchsz=32
lr=1e-3
epochs=10
device=torch.device('cuda')
torch.manual_seed(1234)
train_db=Pokemon('pokemon',224,mode='train')
val_db=Pokemon('pokemon',224,mode='val')
test_db=Pokemon('pokemon',224,mode='test')
train_loader=DataLoader(train_db,batch_size=batchsz,shuffle=True,num_workers=4)
val_loader=DataLoader(val_db,batch_size=batchsz,num_workers=2)
test_loader=DataLoader(test_db,batch_size=batchsz,num_workers=2)
viz=visdom.Visdom()
def evaluate(model,loader):
for x,y in loader:
correct=0
total=len(loader.dataset)
x,y=x.to(device),y.to(device)
with torch.no_grad():
logits=model(x)
pred=logits.argmax(dim=1)
correct=torch.eq(pred,y).sum().float().item()
return correct/total
def main():
model=ResNet18(5).to(device)
optimizer=optim.Adam(model.parameters(),lr=lr)
criteon=nn.CrossEntropyLoss()
best_acc,best_epoch=0,0
global_step=0
viz.line([0],[-1],win='loss',opts=dict(title='loss'))
viz.line([0],[-1],win='val_acc',opts=dict('val_acc'))
for epoch in epochs:
for step,(x,y) in enumerate(train_loader):
#x:[b,3,224,224],y:[b]
x,y=x.to(device),y.to(device)
logits=model(x)
loss=criteon(logits,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step+=1
if epoch%2==0:
val_acc=evaluate(model,val_loader)
if val_acc>best_acc:
best_epoch=epoch
best_acc=val_acc
torch.save(model.state_dict(),'best.mdl')
viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:',best_acc,'best epoch:',best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded form ckpt!')
test_acc=evaluate(model,test_loader)
print('test acc:',test_acc)
if __name__ == '__main__':
main()















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









