






在进行特征工程时,我们经常对表格类数据进行.groupby操作,但其实我对.groupby后的数据到底是长什么样的了解不全面,下面以几个例子。深入理解一下。
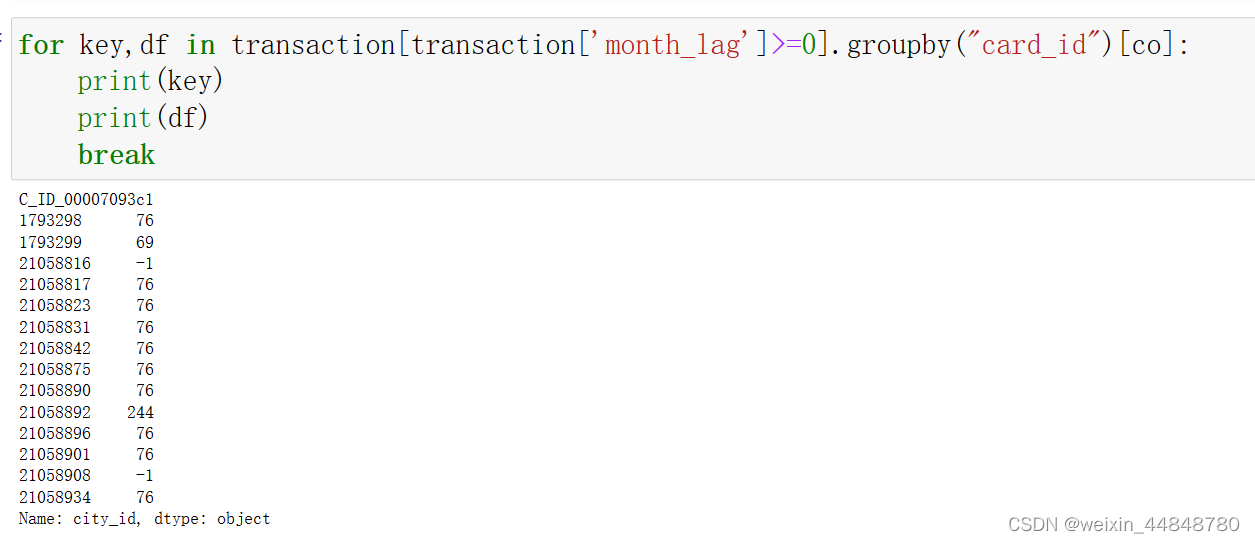
上图中,我们以card_id为分组,来一个个处理特征,现在处理的是city_id特征。
一般我们通过遍历就能知道各组里的具体内容。但现在来看我们对其存储形式的理解还差一点。
具体如下:

按照先前的理解,在进行.apply(list)后,应该返回上图的结果:实际如下:
 可以看到,一组里面的city_id被分到一个列表里,是以card_id为单位进行整体的list。
可以看到,一组里面的city_id被分到一个列表里,是以card_id为单位进行整体的list。
结论:我们知道apply方法作用于df时是按照行,一行行作用的。
所以可以理解为按card_id进行groupby后的单列特征city_id是card_id的一行,是他们的键。而所有的city_id是他们的值,存储为['76','69'.....],所以list他们时不会变成[‘7’,‘6’ ,‘6‘,‘9’......]















 1555
1555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









