






 文章介绍了lightgbm.Dataset的使用,包括data、label、feature_name、categorical_feature等关键参数。Dataset是构建lightgbm模型所需的数据结构,categorical_feature用于指定分类特征,对于处理分类数据至关重要。此外,还提到了训练流程和参数设置示例。
文章介绍了lightgbm.Dataset的使用,包括data、label、feature_name、categorical_feature等关键参数。Dataset是构建lightgbm模型所需的数据结构,categorical_feature用于指定分类特征,对于处理分类数据至关重要。此外,还提到了训练流程和参数设置示例。
'''
lightgbm.Dataset(data, label=None, reference=None, weight=None, group=None, init_score=None, feature_name='auto', categorical_feature='auto', params=None, free_raw_data=True)
'''
'''
返回适用于lightgbm模型的数据结构。好像是二进制啥的
其中:
data: np数组或df
label: np数组或df
reference 官方解释:如果这是用于验证的数据集,则应使用训练数据作为参考。
不知道啥意思,我看人们都不管
group: list:指定分组的个数,如[10,20,30],则前10个为一组,11-30个为一组,
31-60个为一组
但是只在learning-to-rank任务中用到,一般的分类和回归不用这个参数。
init_score 关于算法中的初始得分,自定义损失函数时可以用到,具体怎么用(算)忘记了。
一般用不到
feature_name 指定特征名称,一般是自动的,
但你如果非要对特征命名,要用list of str,且长度和列数一样才行
categorical_feature 指定分类特征的名称,默认自动,且对分类特征采用无序规则:
即如果分类特征是'高中'、'大学'、'小学',lgbm不会按照递进关系对分类字段进行编码。
且:分类特征在输入前需要先转换成整型。因该是为了后面的自动独热编码吧。
而且,一般特征集中有分类特征时,都要用到这个。且在lgb.Dataset与lgb.trian中都指定,
这是最好的。
'''
#重要参数:data、label、feature_name、categorical_feature
#有时还有个silent参数:silent 默认选择True,选择False会输出很多建模中的细节,作用不大还刷屏简单的使用流程:
1.定义数据集和标签,这里定义为二分类问题,注意feature和label的类型,并不要求同类型。满足库的要求即可。
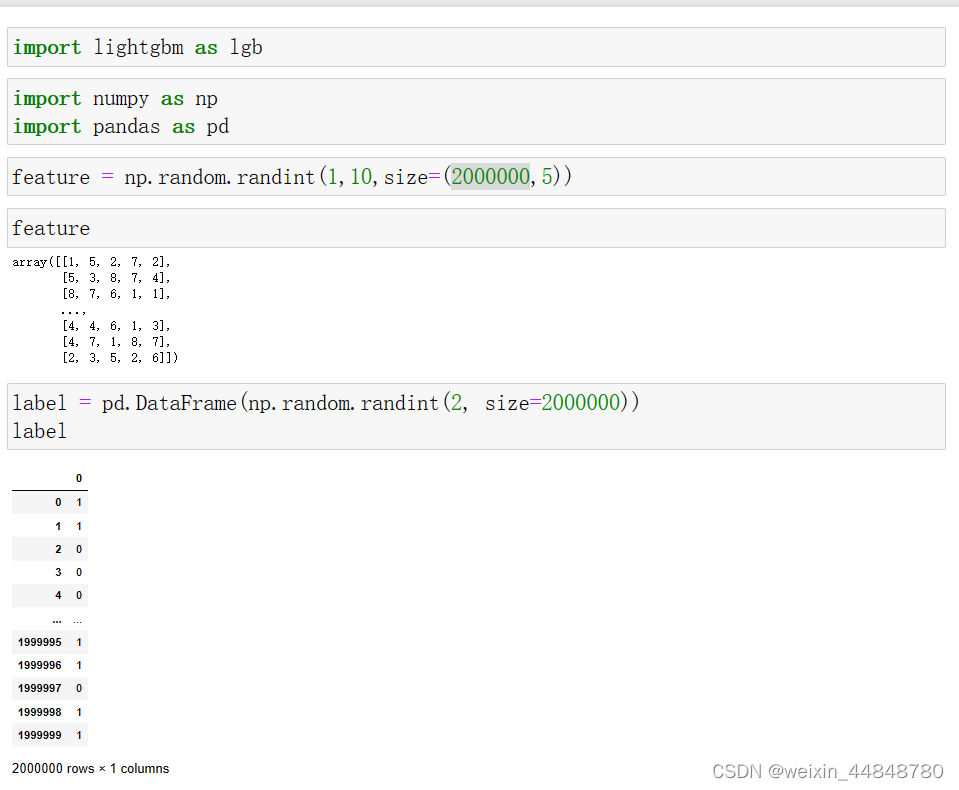
虽然feature是array数组,但是也可以指定特征名称。这里指定第五例特征是分类特征。
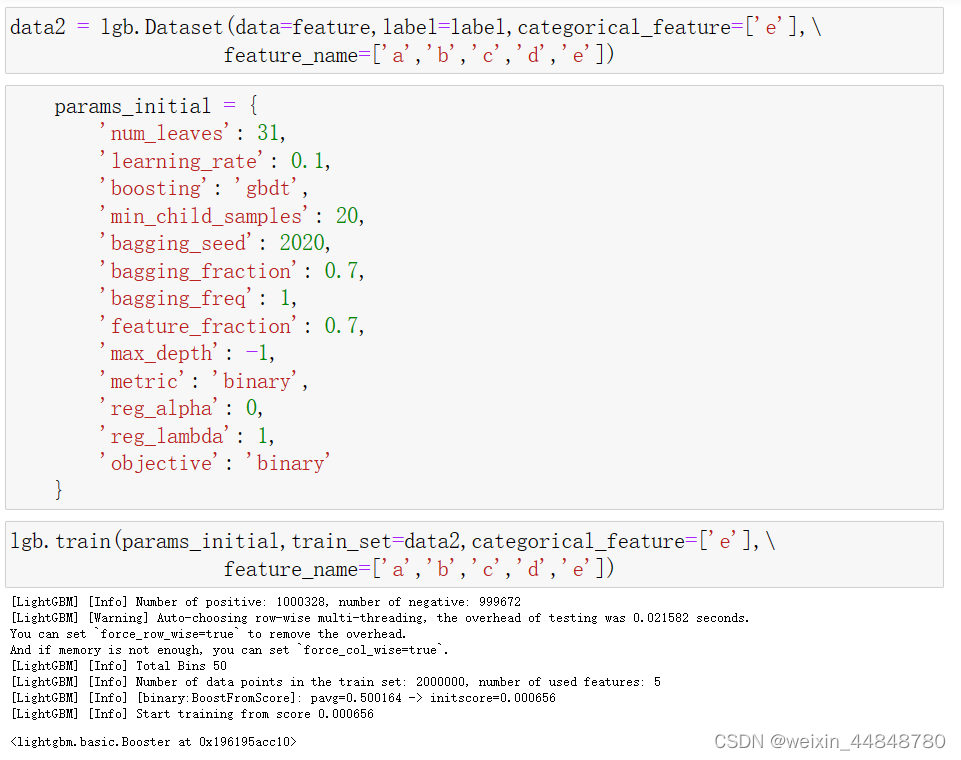
#lgb.Dataset和lgb.train其中一个指定分类特征也行
lgb.train的参数明天再补 cout<<"睡觉"<<endl;
bst = lgb.train(params_initial, train_part, num_boost_round=NBR,
valid_sets=[train_part, eval],
valid_names=['train', 'valid'],
early_stopping_rounds=ESR, verbose_eval=VBE)
'''
一般这样就够用了,参数含义顾名思义。
params_initial参数初始设置:具体大概如下
params_initial = {
'num_leaves': 31,
'learning_rate': 0.1,
'boosting': 'gbdt',
'min_child_samples': 20,
'bagging_seed': 2020,
'bagging_fraction': 0.7,
'bagging_freq': 1,
'feature_fraction': 0.7,
'max_depth': -1,
'metric': 'rmse',
'reg_alpha': 0,
'reg_lambda': 1,
'objective': 'regression'
}
train_part lgb.Dataset后的结果
verbose_eval是指多少轮迭代输出一次训练信息
num_boost_round 迭代提升次数,也相当于评估器个数。
一般设置大的数,然后使用early_stopping_rounds。避免过拟合。
'''

















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









