parameter_space = {
"n_estimators": [80],
"min_samples_leaf": [30],
"min_samples_split": [2],
"max_depth": [9],
"max_features": ["auto", 80]
}
clf = RandomForestRegressor(
criterion="mse",
min_weight_fraction_leaf=0.,
max_leaf_nodes=None,
min_impurity_decrease=0.,
min_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=4,
random_state=2020,
verbose=0,
warm_start=False)
grid = GridSearchCV(clf, parameter_space, cv=2, scoring="neg_mean_squared_error")
grid.fit(train[features].values, train['target'].values)
'''
RandomForestRegressor参数说明
n_estimators:决策树个数
min_samples_leaf:叶节点所需的最小样本数。如果过小,可能导致过拟合
min_samples_split:分裂内部节点所需的最小样本数
max_depth:树的最大深度,越深越拟合
max_features:构建决策树最优模型时考虑的最大特征数。默认是"auto",表示最大特征数是N的平方根;
注意:
首先增大n_estimators,提高模型的拟合能力,当模型的拟合能力没有明显提升的时候,则在增大
max_features,提高每个子模型的拟合能力,则相应的提高了模型的拟合能力。
criterion:计算选择节点后,分裂得分的函数。如基尼指标,信息增益等。“squared_error”。
min_weight_fraction_leaf: (default=0) 叶子节点所需要的最小权值
max_leaf_nodes: (default=None)叶子树的最大样本数。
min_impurity_decrease:(default=0.0)如果分裂导致杂质减少大于或等于该值,则节点将被分裂。
有计算公式
min_impurity_split=None :不知道
bootstrap(default=True)构建树时是否使用引导样本。
如果为 False,则使用整个数据集来构建每棵树。袋外样本误差是测试数据集误差的无偏估计,
所以推荐设置True。
oob_score :默认为False,True表示用袋外数据来测试模型。
可以通过oob_score_来查看模型的准取度。
warm_start:当设置为 True 时,重用先前调用的解决方案来拟合并向集合中添加更多估计器,
否则,只需拟合一个全新的森林
'''
'''
说明:
0.z最后使用model = grid.best_estimator_来得到带有最佳超参数的模型。再进行model.fit、predict等操作
1.parameter_space 中包含的是需要确定的参数值,形式为字典,值以列表的形式给出。
网格搜索会将各个参数的列表中的值进行排列组合,最后输出一个带有最佳超参数的模型
2.parameter_space中参数的名称,由模型确定,模型中的参数是什么名字,space里就用什么名字
3.clf中也要写参数,是已经确定的参数,clf中的参数和parameter_space的参数结合起来,才是模型
中的所有参数。
4.CV是交叉验证折数
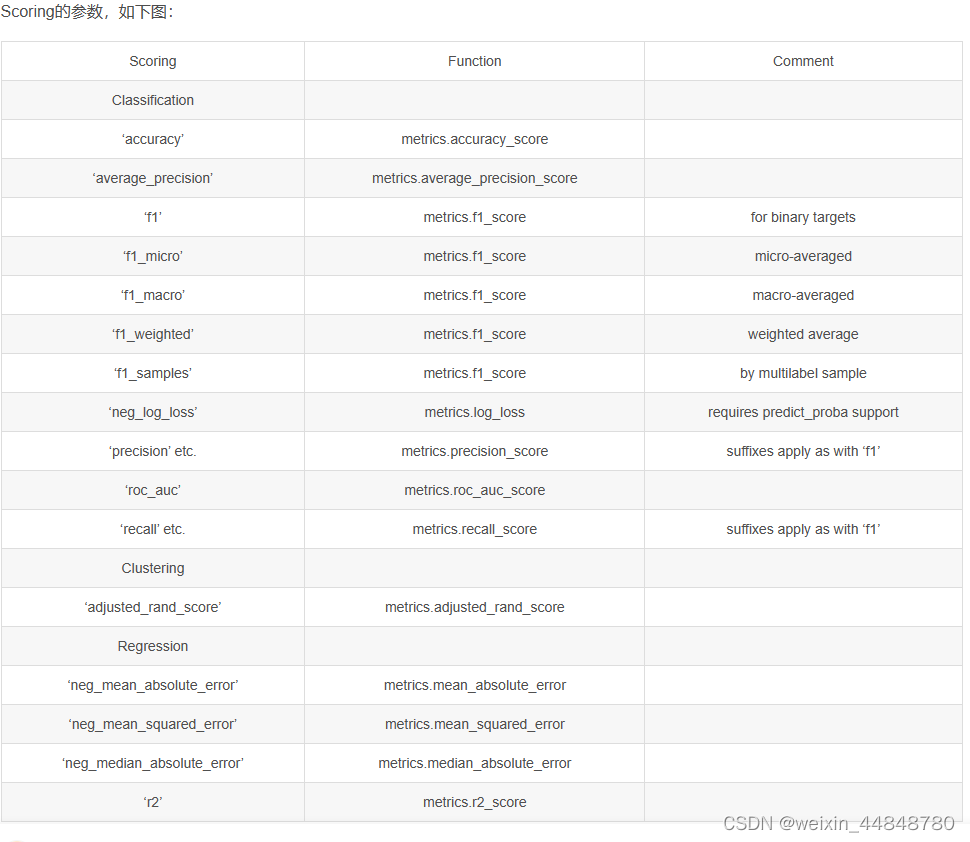
5.scoring是计算验证集得分的损失函数,具体如下图
'''






















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









