







Redis 的缓存一致性
Redis 的缓存一致性是指在使用 Redis 作为缓存层时,保证缓存中的数据与数据库中的数据保持一致的状态。在分布式系统中,数据一致性是一个重要的问题,因为可能存在多个客户端同时读写同一数据,或者数据在不同节点间需要同步更新。
在涉及缓存的场景中,保持缓存一致性面临以下挑战:
数据更新:当数据库中的数据被修改后,相关联的缓存数据需要被相应地更新或失效,以避免返回陈旧的数据。
数据失效:当缓存的数据被认定为过时(可以是时间过期,或者因为底层数据有变更)时,必须从缓存中移除,以确保下次读取会从后端数据库加载最新数据。
数据同步:在分布式缓存环境中,相同的数据可能会存储在多个缓存节点上。这就要求所有的节点在数据变化时保持同步,从而确保数据的一致性。
为了处理这些挑战,你可以采取以下几种常见的方法保证缓存一致性:
强一致性
确保缓存和数据库的写入操作是原子的,即任何时刻,所有客户端看到的数据总是最新的。在实践中,这通常需要使用分布式锁或事务来实现,但可能会带来性能上的开销。
弱一致性
接受在短时间内缓存数据可能不同步的情况,但确保在一定时间后能够达到一致性。例如,可以通过设置缓存的过期时间来自动让旧数据失效。
缓存更新策略
比如采用“写入时更新”(Write-through)、“写入后更新”(Write-behind)等策略,这些策略定义了不同的数据同步时机和方式。
维护缓存和数据库的一致性可能会很复杂,需要在数据的实时性(一致性)和系统的性能之间做权衡。正确的缓存策略和实现细节取决于具体的应用场景和对数据一致性的需求。
缓存一致性
首先,我们首先明确什么是缓存一致性:
- 缓存中有数据,那么,缓存的数据值需要和数据库中的值相同;
- 缓存中本身没有数据,那么,数据库中的值必须是最新值。
缓存同步策略
- 先更新缓存,再更新数据库;
- 先更新数据库,再更新缓存;
- 先删除缓存,再更新数据库;
- 先更新数据库,再删除缓存;
- 先删除缓存,再更新数据库,延迟一会后,再删除缓存(延迟双删);
代码实现
用一个HashMap模拟数据库存储
package com.single.conherence;
import java.util.HashMap;
import java.util.Map;
/**
* @program: RedisDemo
* @description:
* @author: fudingwei
* @create: 2024-05-28 11:39
**/
public class DataBaseConstant {
public static final Map<String,String> DATA_MAP = new HashMap<String,String>();
}
1、先更新缓存,再更新数据库
package com.single.conherence;
import org.redisson.Redisson;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.redisson.config.Config;
import java.util.Date;
import java.util.concurrent.TimeUnit;
import static com.single.conherence.DataBaseConstant.DATA_MAP;
/**
* @program: RedisDemo
* @description: 先更新缓存,再更新数据库,A,B两个线程
* @author: fudingwei
* @create: 2024-05-28 11:12
**/
public class RedisTest1 {
public static void main(String[] args) throws InterruptedException {
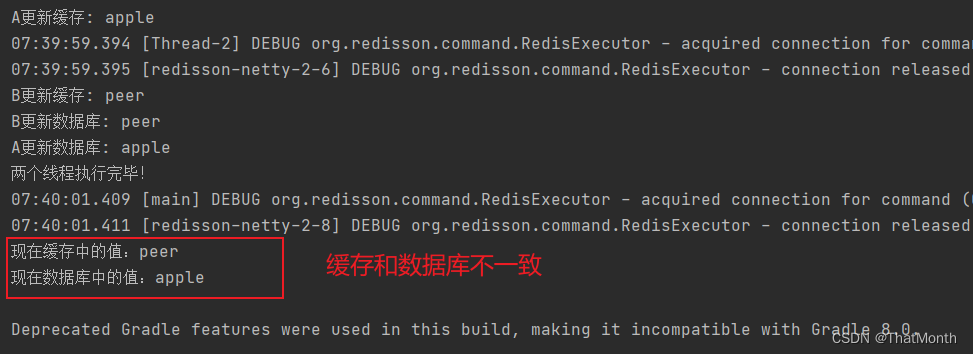
//1、A更新缓存为 apple,然后出现网络延迟,A暂停
//2、B过来更新缓存 peer,更新数据库 peer
//3、A继续更新数据库 apple,就会导致数据不一致问题
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
StringCodec stringCodec = new StringCodec();
config.setCodec(stringCodec);
RedissonClient redisson = Redisson.create(config);
RBucket<Object> fdw = redisson.getBucket("fdw");
//线程A
Thread t1 = new Thread(()->{
fdw.set("apple");
System.out.println("A更新缓存: "+"apple");
try {
//由于网络延迟,暂停3秒
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
DATA_MAP.put("fdw","apple");
System.out.println("A更新数据库: "+"apple");
});
//线程B
Thread t2 = new Thread(()->{
fdw.set("peer");
System.out.println("B更新缓存: "+"peer");
DATA_MAP.put("fdw","peer");
System.out.println("B更新数据库: "+"peer");
});
//启动两个线程
t1.start();
try {
//暂停1秒,B在A之后启动,
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
//等待两个线程执行
t1.join();
t2.join();
System.out.println("两个线程执行完毕!");
System.out.println("现在缓存中的值:"+fdw.get());
System.out.println("现在数据库中的值:"+DATA_MAP.get("fdw"));
System.exit(0);
}
}
测试结果:
2、先更新数据库,再更新缓存
package com.single.conherence;
import org.redisson.Redisson;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
import static com.single.conherence.DataBaseConstant.DATA_MAP;
/**
* @program: RedisDemo
* @description: 先更新数据库,再更新缓存,A,B两个线程
* @author: fudingwei
* @create: 2024-05-28 11:12
**/
public class RedisTest2 {
public static void main(String[] args) throws InterruptedException {
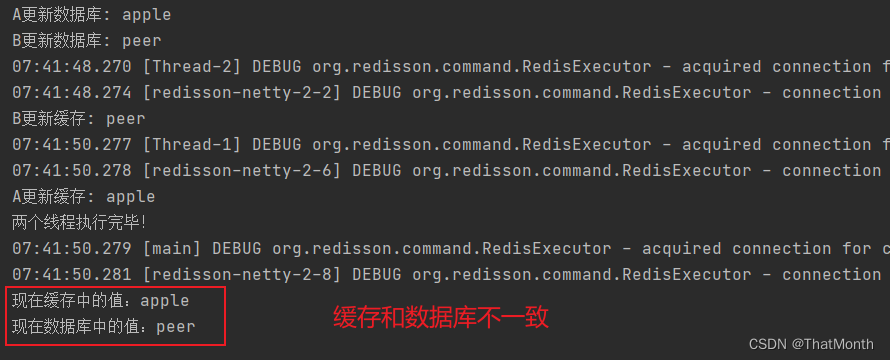
//1、A更新数据库为 apple,然后出现网络延迟,A暂停
//2、B过来更新数据库为 peer,更新缓存为 peer
//3、A继续更新缓存为 apple,就会导致数据不一致问题
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
StringCodec stringCodec = new StringCodec();
config.setCodec(stringCodec);
RedissonClient redisson = Redisson.create(config);
RBucket<Object> fdw = redisson.getBucket("fdw");
//线程A
Thread t1 = new Thread(()->{
DATA_MAP.put("fdw","apple");
System.out.println("A更新数据库: "+"apple");
try {
//由于网络延迟,暂停3秒
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
fdw.set("apple");
System.out.println("A更新缓存: "+"apple");
});
//线程B
Thread t2 = new Thread(()->{
DATA_MAP.put("fdw","peer");
System.out.println("B更新数据库: "+"peer");
fdw.set("peer");
System.out.println("B更新缓存: "+"peer");
});
//启动两个线程
t1.start();
try {
//暂停1秒,B在A之后启动,
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
//等待两个线程执行
t1.join();
t2.join();
System.out.println("两个线程执行完毕!");
System.out.println("现在缓存中的值:"+fdw.get());
System.out.println("现在数据库中的值:"+DATA_MAP.get("fdw"));
System.exit(0);
}
}
测试结果:
3、先删除缓存,再更新数据库
package com.single.conherence;
import org.redisson.Redisson;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
import static com.single.conherence.DataBaseConstant.DATA_MAP;
/**
* @program: RedisDemo
* @description: A先删除缓存,再更新数据库,B查询缓存,没有查到就查数据库,再更新到缓存
* (因为两个线程都是删除缓存话不存在缓存不一致的问题,没有研究价值,这里测试一删一查的情况)
* @author: fudingwei
* @create: 2024-05-28 11:12
**/
public class RedisTest3 {
public static void main(String[] args) throws InterruptedException {
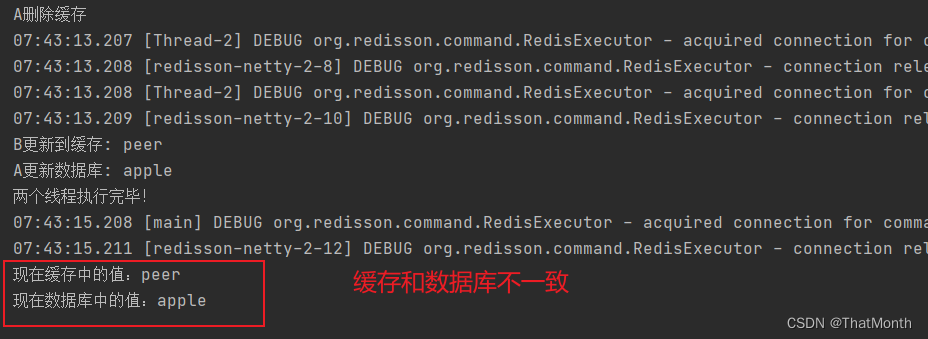
//1、A先删除缓存,然后出现网络延迟,A暂停
//2、B过来查询缓存为空,然后查询数据库为peer,更新缓存为peer
//3、A继续更新数据库为 apple,就会导致数据不一致问题
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
StringCodec stringCodec = new StringCodec();
config.setCodec(stringCodec);
RedissonClient redisson = Redisson.create(config);
RBucket<Object> fdw = redisson.getBucket("fdw");
DATA_MAP.put("fdw","peer");
fdw.set("peer");
//线程A
Thread t1 = new Thread(()->{
fdw.delete();
System.out.println("A删除缓存");
try {
//由于网络延迟,暂停3秒
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
DATA_MAP.put("fdw","apple");
System.out.println("A更新数据库: "+"apple");
});
//线程B
Thread t2 = new Thread(()->{
Object o = fdw.get();
if(null==o){
//查询数据库
String fdwData = DATA_MAP.get("fdw");
//更新到缓存
fdw.set(fdwData);
System.out.println("B更新到缓存: "+fdwData);
}
});
//启动两个线程
t1.start();
try {
//暂停1秒,B在A之后启动,
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
//等待两个线程执行
t1.join();
t2.join();
System.out.println("两个线程执行完毕!");
System.out.println("现在缓存中的值:"+fdw.get());
System.out.println("现在数据库中的值:"+DATA_MAP.get("fdw"));
System.exit(0);
}
}
测试结果:
4、先更新数据库,再删除缓存(推荐方式)
package com.single.conherence;
import org.redisson.Redisson;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
import static com.single.conherence.DataBaseConstant.DATA_MAP;
/**
* @program: RedisDemo
* @description: A先更新数据库,再删除缓存(推荐方式),B查询缓存,没有就查数据库,再更新到缓存
* (因为两个线程都是删除缓存话不存在缓存不一致的问题,没有研究价值,这里测试一删一查的情况)
* @author: fudingwei
* @create: 2024-05-28 11:12
**/
public class RedisTest4 {
public static void main(String[] args) throws InterruptedException {
//1、A更新数据库为 apple,然后出现网络延迟,A暂停
//2、B过来查询缓存为 peer,可能会出现短暂的数据不一致现象
//3、A继续删除缓存,最终数据是一致的
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
StringCodec stringCodec = new StringCodec();
config.setCodec(stringCodec);
RedissonClient redisson = Redisson.create(config);
RBucket<Object> fdw = redisson.getBucket("fdw");
DATA_MAP.put("fdw","peer");
fdw.set("peer");
//线程A
Thread t1 = new Thread(()->{
DATA_MAP.put("fdw","apple");
System.out.println("A更新数据库: "+"apple");
try {
//由于网络延迟,暂停3秒
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
//这边需要有删除失败,重试的机制!!!
fdw.delete();
System.out.println("A删除缓存");
});
//线程B
Thread t2 = new Thread(()->{
Object o = fdw.get();
if(null == o){
//缓存没有就查数据库
String fdwData = DATA_MAP.get("fdw");
//更新缓存
fdw.set(fdwData);
}else {
System.out.println("B查询到的值:"+o);
}
});
//启动两个线程
t1.start();
try {
//暂停1秒,B在A之后启动,
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
//等待两个线程执行
t1.join();
t2.join();
System.out.println("两个线程执行完毕!");
System.out.println("现在缓存中的值:"+fdw.get());
System.out.println("现在数据库中的值:"+DATA_MAP.get("fdw"));
System.exit(0);
}
}
测试结果:
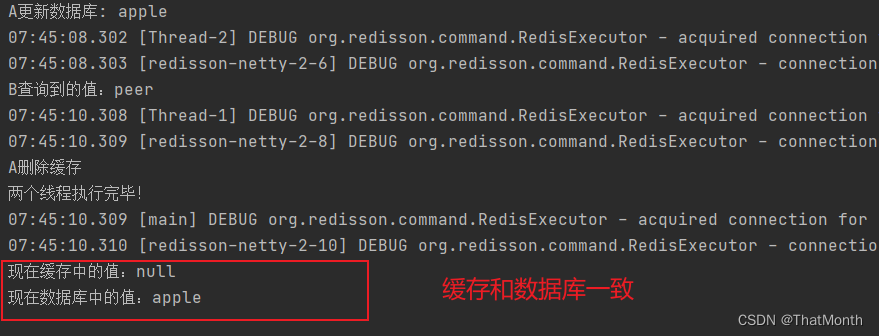
注意:这样虽然可能有短暂的数据不一致现象,但保证了最终一致性,要注意第二步可能有删除缓存失败的问题,所以需要有删除重试机制。
5、先删除缓存,再更新数据库,延迟一会后,再删除缓存(延迟双删)
package com.single.conherence;
import org.redisson.Redisson;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
import static com.single.conherence.DataBaseConstant.DATA_MAP;
/**
* @program: RedisDemo
* @description: A先删除缓存,再更新数据库,B查询缓存,没有查到就查数据库,再更新到缓存,A等待一段时间后(等B更新完缓存),删除缓存
* (延迟双删策略)
* @author: fudingwei
* @create: 2024-05-28 11:12
**/
public class RedisTest5 {
public static void main(String[] args) throws InterruptedException {
//1、A先删除缓存,然后出现网络延迟,A暂停
//2、B过来查询缓存为空,然后查询数据库为peer,更新缓存为peer
//3、A继续更新数据库为 apple,就会导致数据不一致问题
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
StringCodec stringCodec = new StringCodec();
config.setCodec(stringCodec);
RedissonClient redisson = Redisson.create(config);
RBucket<Object> fdw = redisson.getBucket("fdw");
DATA_MAP.put("fdw","peer");
fdw.set("peer");
//线程A
Thread t1 = new Thread(()->{
fdw.delete();
System.out.println("A删除缓存");
try {
//由于网络延迟,暂停3秒
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
DATA_MAP.put("fdw","apple");
System.out.println("A更新数据库: "+"apple");
try {
//故意延迟2秒,再删除缓存
TimeUnit.SECONDS.sleep(2);
fdw.delete();
System.out.println("A延迟删除缓存");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//线程B
Thread t2 = new Thread(()->{
Object o = fdw.get();
if(null==o){
//查询数据库
String fdwData = DATA_MAP.get("fdw");
//更新到缓存
fdw.set(fdwData);
System.out.println("B更新到缓存: "+fdwData);
}
});
//启动两个线程
t1.start();
try {
//暂停1秒,B在A之后启动,
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
//等待两个线程执行
t1.join();
t2.join();
System.out.println("两个线程执行完毕!");
System.out.println("现在缓存中的值:"+fdw.get());
System.out.println("现在数据库中的值:"+DATA_MAP.get("fdw"));
System.exit(0);
}
}
测试结果:
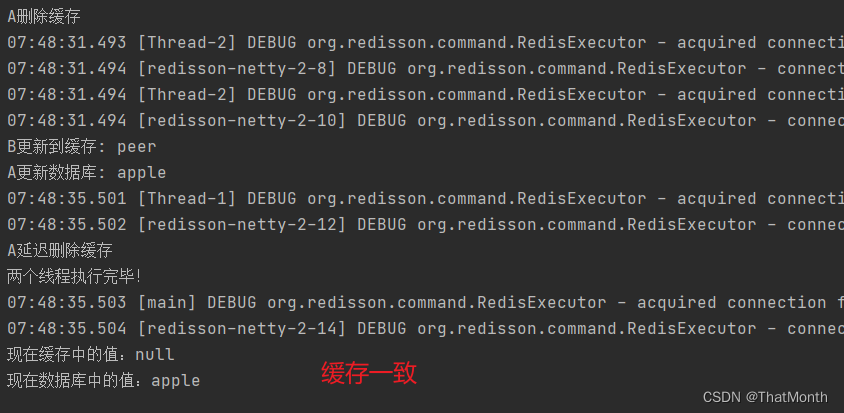
注意:这个延迟时间是要大于 B线程【查数据库然后更新缓存所需的时间】 ,这个要根据业务来确定,一般很难确定,所以这种方案不常用。
最优方案
以上几种方式中推荐使用【4、先更新数据库,再删除缓存】,但如果对一致性要求较高的话,目前最好的缓存同步方案是使用阿里的Canal组件,该组件只适用于MySQL,它的原理是把自己模拟成一台MySQL的从机,从主机获取binlog日志,通过解析binlog日志获取到数据的变化,再同步到Redis缓存,保证强一致性!

















 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











