







1.1训练集、测试集、验证集,这三者最好来自同一分布,搭建训练验证集和测试集能够加速神经网络的集成。
1.2方差、偏方差




1.3正则化
一般过度拟合数据(高方差问题)解决方法通常是正则化或者准备更多数据。
正则化就是在原有的成本函数上加一个含有正则化参数的项lambd
L2正则化,也称为权重衰减

L1正则化(会导致w变得稀疏,含有大量0)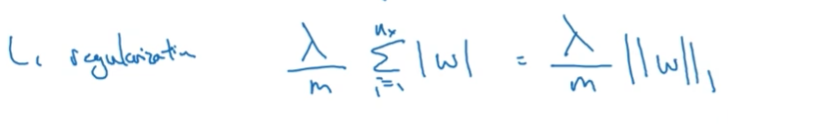
过拟合解决方法-正则化
1.dropout
keep-prob表示保留一个隐藏单元的概率
Inverted dropout (反向随机失活)——用来除以keep-prob,确保期望值不变
2.Data augmentation
当出现过拟合,需要增加训练数量来解决时,就可以通过图片的翻转来实现数据增广(水平或者垂直等其他图片操作或者强变形处理都视为新图片),也就是数据集的增加。
3.Early stopping
让成本函数j提前在已经较小的值结束整个神经网络的训练,从而获得找出w的较小值、中间值和较大值,而无需尝试L2 的正则化超级参数lamda的很多值,但缺点是,该处理方式会提前结束j,让j达不到最小的时候得到参数,虽然这样可以减小过拟合。换句话来讲,就是该处理方式不能同时满足j小和过拟合小的目的。
2归一化输入
Normalizing training sets
3梯度爆炸和梯度消失
梯度爆炸和梯度消失就是指下降的导数或者坡度有时会很大或者很小。就是,当出现与层数相关的激活函数会出现指数式的变化
为了解决这个问题,可以从权重的初始化改变
梯度的数值逼近:1.双边检验法
***梯度检验-仅用来debug ***
1.把所有参数转换成一个巨大的向量数据,即将w转换成个向量矩阵















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









