









此文字数5845,看完时间约为。。。。。 当然看自己的理解能力了,第二章的内容基本都在这里,根据自己的的理解而编写的。
欢迎大家一起讨论学习!
2.1经验误差与过拟合
误差 : 学习器上的实际预测输出与样本真实输出之间的差异。
训练误差(经验误差): 学习器在训练集上的误差。
泛化误差: 在新样本上的误差。
过拟合: 学习器学习能力过强,把训练样本自身独有的特点当作所有潜在样本的一般性质,导致泛化性能下降。

2.2 评估方法
评估学习器的好坏即评估其泛化误差。
D:数据集 S:训练集 T:测试集
D中产出S与T的方法:
1、留出法(hold - out): 直接把D划分为互斥的S与T,即D = S∪T,S∩T=空集(我的输入法打不出空集)。
一般要采取若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
划分比例: 训练集2/3~4/5,剩下的就测试集了。
2、交叉验证法(cross validation): 先采用分层抽样将数据集D划分为k个大小相似的互斥子集,每次采用k-1组子集作为训练集, 剩余作为测试集。重复取k次训练集,即得到k组测试结果。返回k组数据的均值。

k折交叉验证(k-fold cross validation): 交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为强调这一点,通常把交叉验证法称为“k折交叉验证”(k-fold cross validation)。
p次k折交叉验证: 即将数据集D划分为k个大小相似的互斥子集这一步骤进行p次,得到p×k个评估结果,返回均值。
留一法: 假定数据集D有m个样本,k=m,m个样本只有唯一的方式划分k = m个子集,因此留一法不受随机划分的影响,留一法在数据集较小的情况下用。(较为准确)
3、自助法: 以自助采样法为基础。(减少训练样本规模不同所造成的影响)
给定包含m个样本的数据集D,对它进行采样产生数据集次D: 随机从D中挑出一个样本,拷贝放入数据集次D中,再将原样本放回数据集D中,下次随机挑选仍可以被挑到,这个过程执行m次,我们就得到了m个样本的数据集次D,这就是自助采样的结果。
通过自助采样,初始数据集D中约有36.8%的样本未出现在数据集次D中,因此,我们可以用次D做训练集,D\次D作为测试集,这样实际评估的模型与期望评估的模型都使用了m个样本,但我们仍有约1/3的、没在训练集中出现的样本作为测试集,测试结果称为**“包外估计”**。
(在训练集较小、难以有效划分训练集、测试集时使用)
4、调参与最终模型: (之后补上)
2.3 性能度量
定义: 对学习器的泛化性能进行评估,不仅需要有效可行的实验评估方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量。(反映任务需求)
回归任务最常用的性能度量是 “均方误差”
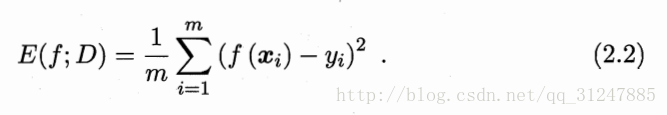
更一般的,对于数据分布d和概率密度函数p(·),均方误差可描述为
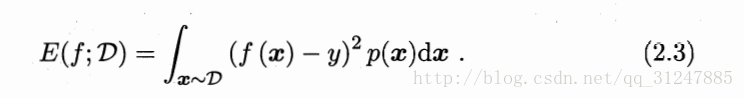
2.3.1 错误率与精度 (适用于二分类任务,也适应于多分类任务)
错误率: 分类错误样本数占总样本数的比例。
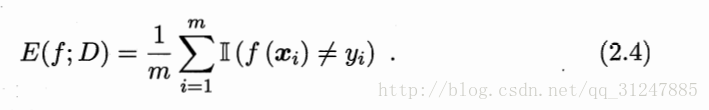
精度: 分类正确的样本数占样本总数的比例。
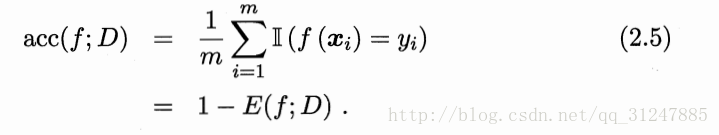
2.3.2 查准率(precision)、查全率(recall)与F1(harmonic mean )
True positive 真正例,False positive 假正例,True negative 真反例,False negative 假反例,TP+FP+TN+FN = 样例总数,如图:

查准率P和查全率R分别定义为:

即 查准率P=真正例/预测结果的正例,查全率R=真正例/真实情况的正例。
P-R图直观显示出学习器在样本总体上的查全率、查准率。 如下图:

根据P-R图来判断学习器的性能:
若一个学习器的P-R曲线被另一个学习器的P-R曲线所包围,则可断言后者的性能优于前者;
“平衡点”(Break - Even Point,简称BEP),它是“P = R”时的取值,因此,A的性能优于B的;(P-R曲线交叉时用此判断)
“调和平均”(harmonic mean ):(更常用)
F1=

F1度量的一般形式——Fβ,能让我们表达出对查准率\查全率的不同偏好,它定义为
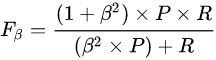
其中β>0度量了查全率对查准率的相对重要性。(调和平均更重视较小值)
β<1,查准率具有更大影响;
β=1,退化为标准F1;
β>1,查准率具有更大影响。
那些什么宏P、宏R以及宏F1就不讲了,自己去看书吧,即平均,or平均所求。
2.3.3 ROC与AUC
学习器将测试样本进行排序,“最可能”是正例的排在最前面,“最不可能”是正例的排在最后面。分类过程相当于是以某个 “截断点” (cut point)将样本分为两部分,前为正例,后为反例。
若更重视“查准率”,选择更靠前的位置进行截断;若更重视“查回率”,选择更靠后的位置进行截断。
排序本身质量的好坏,体现了学习器“一般情况下”泛化性能的好坏。
“ROC曲线 - 受试者工作特征” (Receiver Operating Characteristic )则是是从这个角度出发来研究学习器的泛化性能的有力工具。
ROC曲线的纵轴是“真正例率”(True Positive Rate 简称TPR),横轴是“假正例率”(False Positive Rate 简称FPR),两者定义为
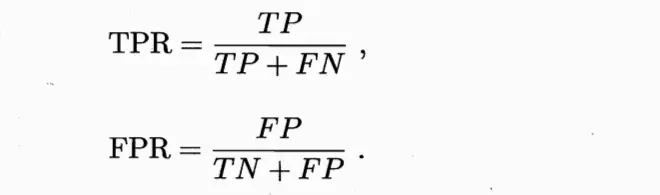
即TPR = 真正例/真实情况的正例,FPR = 假正例/真实情况的反例
图2.4(a)是ROC图的示意图,对角线对应随机猜测模型,而(0,1)对应将所有正例排在反例之前的理想模型。现实任务中通常利用有限个测试样例来绘制ROC图,无法产生图2.4(a)的光滑曲线,只能绘制出图2.4(b)所示的近似ROC曲线。
ROC曲线绘制过程: 给定m+个正例和m-个反例,根据学习器预测结果对样例进行排序,把所有样例均预测为反例,此时TPR和FPR均为0,在(0,0)处标记一个点,然后依次将每个样例划分为正例,设前一个标记点坐标为(x,y),当前若为真正例,则对应标记点的坐标为(x,y+1/m+),当前若为假正例,则对应标记点坐标为(x+1/m+,y),然后用线段连接相邻点即可

类似P-R图,若一个学习器的ROC曲线被另一个学习器的曲线包住,则可断言后者性能优于前者;若两个学习器的ROC曲线交叉,可以通过比较ROC曲线下的面积,即AUC来判断。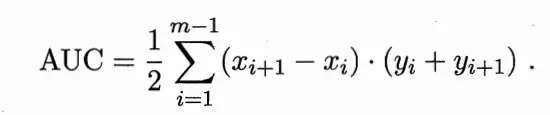
给定m+个正例和m-个反例,令D+和D-分别表示正、反例集合,排序“损失”(loss) 定义为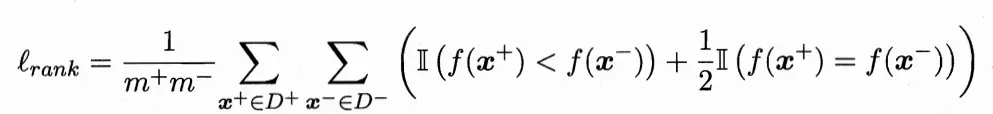
L(rank)对应得事ROC曲线之上的面积:若一个正例在ROC曲线上对应的标记点的坐标为(x,y),则x恰是排序在其之前的反例所占的比例,即假正例率。(说实话这句话我也不是特别明白,请知道的大佬赐教)因此有
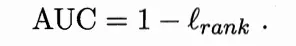
2.3.4 代价敏感错误率与代价曲线
为权衡不同类型错误所造成的不同损失,可为错误赋予 ”非均等代价“
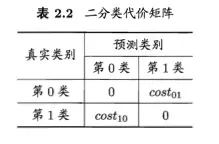
一般来说,cost[ii] = 0;若将第0类判别为第1类所造成的损失更大,则cost[01] >cost[10]; 损失程度相差越大,cost[01]与cost[10]的差值也就越大。
“代价敏感” (cost sensitive)错误率为
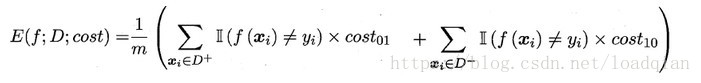
类似的,可给出基于分布定义的代价敏感错误率,也可给出其他一些性能度量,如精度的代价敏感版本。
在非均等代价下,ROC曲线不能直接反映学习器的期望总体代价,而 “代价曲线”(cost curve) 可达到此目的。代价曲线图的横轴是正例概率代价
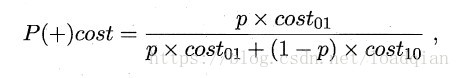
其中p表示正例的概率,纵轴是取值为[0,1]的归一化代价。
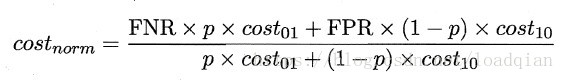
代价曲线的绘制很简单:设ROC曲线上点的坐标为(TPR,FPR) ,则可相应计算出FNR=1-TPR,然后在代价平面上绘制一条从(0,FPR) 到(1,FNR) 的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价,如图所示:

2.4比较检验
先使用某种实验评估方法,测得学习器的某个性能度量结果,再通过统计假设检验方法对其性能度量进行比较。
影响学习器性能评估比较的几个重要因素:
第一,我们希望比较的是泛化性能,而实验评估方法让我们得到的是测试集上的性能,两者的对比结果未必相同;
第二,测试集上的性能与测试集本身的选择有很大关系;
第三,很多机器学习算法本身具有一定的随机性。
概率论还没学,之后在另一篇补上。
若测试集上观察到A比B的性能好,基于假设检验结果我们可以推断出A的泛化性能是否在统计意义上优于B,以及这个结论有多大的把握。(先知道这个就好了)
2.5 偏差与方差
下一篇吧,这一篇篇幅太长,看得你们恶心。哈哈哈
公式图都是“借”了别人的,感谢!!!!















 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









