









一、String的基本特性
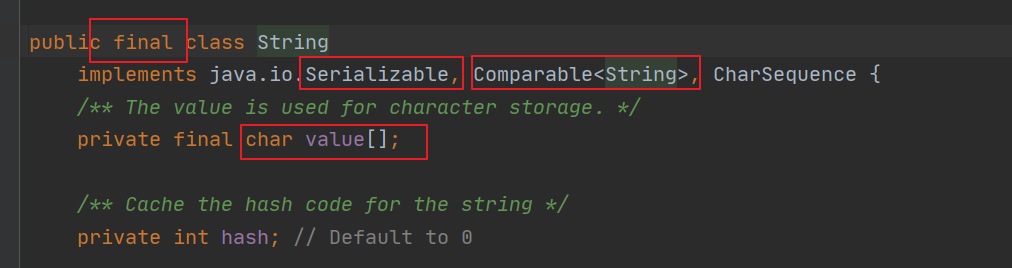
- String声明为
final,不可被继承 - 实现了
Serializable接口,支持序列化;实现了Comparable接口,字符串可以比较大小 - 在Java8及以前使用
char[]存储字符串,在Java9后改用byte[],数组创建后大小不可变
不可变性
-
字符串重现赋值时,需要重新指定内存区域赋值,不能直接修改原来地址的值
public void test1() { String s1 = "abc";//字面量定义的方式,"abc"存储在字符串常量池中 String s2 = "abc"; System.out.println(s1 == s2); s1 = "hello"; System.out.println(s1 == s2); System.out.println(s1); System.out.println(s2); } --------------- true false hello abc -
对原有的字符串进行拼接操作时,也需要重新指定内存区域赋值,不能直接修改原来地址的值
public void test2() { String s1 = "abc"; String s2 = "abc"; s2 += "def"; System.out.println(s2);//abcdef System.out.println(s1);//abc } -
当调用String的
replace()方法修改字符或者字符串时,需要重新指定内存区域赋值,不能直接修改原来地址的值public void test3() { String s1 = "abc"; String s2 = s1.replace('a', 'm'); System.out.println(s1);//abc System.out.println(s2);//mbc }
一道面试题
public class StringExer {
String str = new String("good");
char[] ch = {'t', 'e', 's', 't'};
public void change(String str, char ch[]) {
str = "test ok";
ch[0] = 'b';
}
public static void main(String[] args) {
StringExer ex = new StringExer();
ex.change(ex.str, ex.ch);
System.out.println(ex.str);//good
System.out.println(ex.ch);//best
}
}
-
str原来是存在544位置的,在调用change()函数进行的是值传递,在change()函数中的str的作用域仅在方法中,于是在546位置创建了字符串
test ok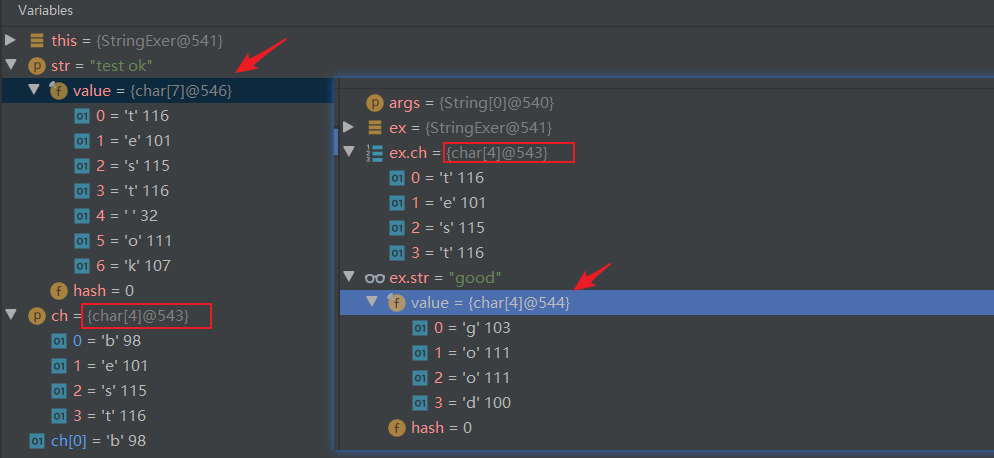
-
如果改一下change()函数的参数列表
public void change(String str11, char ch[]),这时输出结果就会是test ok,因为change()方法中的str作用域是整个类,所以相当于重新赋值,但是必须注意,字符串具有不可变性,仍然是在新的内存地址创建test ok -
所以本题的关键在于作用域的范围的理解
二、String的内存分配
- 在Java6及以前,字符串常量池放在永久代当中;在Java7之后,字符串常量池放入堆中
- Java7之前,方法区在堆里面;Java8以后,方法区放到本地内存中
- 方法区是一个概念模型,Java8之前用永久代(PermGen)实现,Java8之后用元空间(Metaspace)实现
三、String的基本操作
-
字符串常量池中不能存储内容相同的字符串
-
class Memory { public static void main(String[] args) {//line 1 int i = 1;//line 2 Object obj = new Object();//line 3 Memory mem = new Memory();//line 4 mem.foo(obj);//line 5 }//line 9 private void foo(Object param) {//line 6 String str = param.toString();//line 7 System.out.println(str); }//line 8 }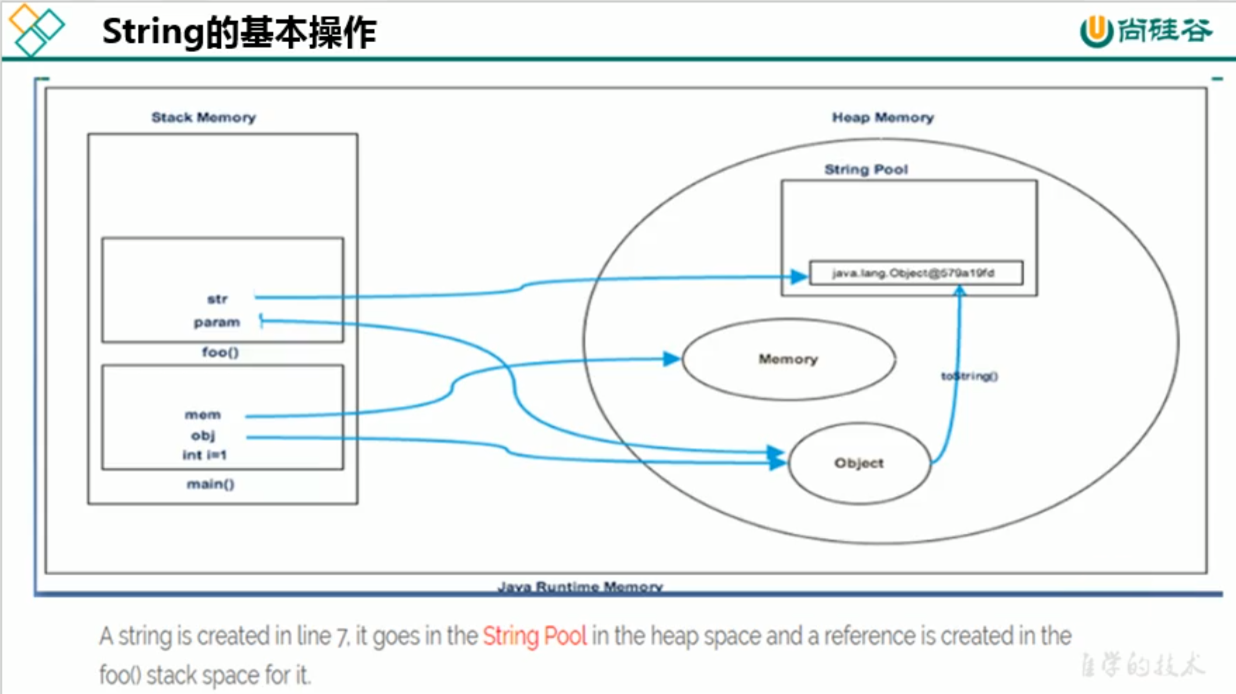
四、字符串拼接操作
-
常量和常量的拼接结果在常量池中,原理是编译器优化
-
只要有一个变量,结果就会在堆中,原理是
StringBuilder的拼接操作,对于final修饰的变量也会在编译器优化成常量public class StringTest5 { @Test public void test1(){ String s1 = "a" + "b" + "c";//编译期优化:等同于"abc" String s2 = "abc"; //"abc"一定是放在字符串常量池中,将此地址赋给s2 /* * 最终.java编译成.class,再执行.class * class文件中的结果 * String s1 = "abc"; * String s2 = "abc" */ System.out.println(s1 == s2); //true System.out.println(s1.equals(s2)); //true } @Test public void test2(){ String s1 = "javaEE"; String s2 = "hadoop"; String s3 = "javaEEhadoop"; String s4 = "javaEE" + "hadoop";//编译期优化 //如果拼接符号的前后出现了变量,则相当于在堆空间中new String(),具体的内容为拼接的结果:javaEEhadoop String s5 = s1 + "hadoop"; String s6 = "javaEE" + s2; String s7 = s1 + s2; System.out.println(s3 == s4);//true System.out.println(s3 == s5);//false System.out.println(s3 == s6);//false System.out.println(s3 == s7);//false System.out.println(s5 == s6);//false System.out.println(s5 == s7);//false System.out.println(s6 == s7);//false //intern():判断字符串常量池中是否存在javaEEhadoop值,如果存在,则返回常量池中javaEEhadoop的地址; //如果字符串常量池中不存在javaEEhadoop,则在常量池中加载一份javaEEhadoop,并返回次对象的地址。 String s8 = s6.intern(); System.out.println(s3 == s8);//true } @Test public void test3(){ String s1 = "a"; String s2 = "b"; String s3 = "ab"; /* 如下的s1 + s2 的执行细节:(变量s是我临时定义的) ① StringBuilder s = new StringBuilder(); ② s.append("a") ③ s.append("b") ④ s.toString() --> 约等于 new String("ab") 补充:在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是StringBuffer */ String s4 = s1 + s2;// System.out.println(s3 == s4);//false } /* 1. 字符串拼接操作不一定使用的是StringBuilder! 如果拼接符号左右两边都是字符串常量或常量引用,则仍然使用编译期优化,即非StringBuilder的方式。 2. 针对于final修饰类、方法、基本数据类型、引用数据类型的量的结构时,能使用上final的时候建议使用上。 */ @Test public void test4(){ final String s1 = "a"; final String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2; System.out.println(s3 == s4);//true } }
五、intern()的使用
两种创建对象方式
-
new String("ab")与new String("a") + new String("b")分别创建了几个对象?/** * 题目: * new String("ab")会创建几个对象?看字节码,就知道是两个。 * 一个对象是:new关键字在堆空间创建的 * 另一个对象是:字符串常量池中的对象"ab"。 字节码指令:ldc * * * 思考: * new String("a") + new String("b")呢? * 对象1:new StringBuilder() * 对象2: new String("a") * 对象3: 常量池中的"a" * 对象4: new String("b") * 对象5: 常量池中的"b" * * 深入剖析: StringBuilder的toString(): * 对象6 :new String("ab") * 强调一下,toString()的调用,在字符串常量池中,没有生成"ab" * * @author shkstart shkstart@126.com * @create 2020 20:38 */ public class StringNewTest { public static void main(String[] args) { // String str = new String("ab"); String str = new String("a") + new String("b"); } }
JDK6与JDK7/8对比
-
对
intern()的使用-
jdk1.6中,将这个字符串对象尝试放入串池。
如果串池中有,则并不会放入。返回已有的串池中的对象的地址
如果没有,会把此对象复制一份,放入串池,并返回串池中的对象地址 -
Jdk1.7起,将这个字符串对象尝试放入串池。
如果串池中有,则并不会放入。返回已有的串池中的对象的地址
如果没有,则会把对象的引用地址复制一份,放入串池,并返回串池中的引用地址
-
public class StringIntern {
public static void main(String[] args) {
String s = new String("1");
s.intern();//调用此方法之前,字符串常量池中已经存在了"1"
String s2 = "1";
System.out.println(s == s2);//jdk6:false jdk7/8:false
String s3 = new String("1") + new String("1");//s3变量记录的地址为:new String("11")
//执行完上一行代码以后,字符串常量池中,是否存在"11"呢?答案:不存在!!
s3.intern();//在字符串常量池中生成"11"。
// 如何理解:jdk6:在字符串常量池中创建了一个新的对象"11",也就有新的地址。
//jdk7:此时常量池中并没有创建"11",而是创建一个指向堆空间中new String("11")的地址
String s4 = "11";//s4变量记录的地址:使用的是上一行代码代码执行时,在常量池中生成的"11"的地址
System.out.println(s3 == s4);//jdk6:false jdk7/8:true
}
}















 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









