







因为机器学习,接触到了数据挖掘;因为数据挖掘,接触到了大数据;因为大数据,接触到了Hadoop。之前有过hadoop的简单了解,但都是基于别人提供的hadoop来学习和使用,虽然也很好用 ,终究不如自己的使用起来方便 。经过这两天参考大量网上的经验,终于成功的搭建了自己的hadoop完全分布式环境。现在我把所有的安装思路、安装过程中的截图以及对待错误的经验总结出来,相信安装这个思路去做,hadoop安装就不再是一件困难的事。
我自己是搭建的完全分布式的hadoop,就涉及到了创建若干个虚拟机并使它们能够互通。所以我整个hadoop安装能够分为三个独立的部分:1、linux 虚拟机详细搭建过程;2、hadoop完全分布式集群安装;3、hadoop 自带示例wordcount 的具体运行步骤。本文介绍第三部分。(我们在做本节内容的基础是Hadoop已经启动)
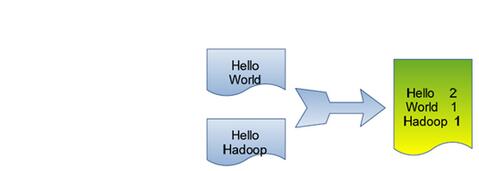
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版”Hello World”,该程序的完整代码可以在Hadoop安装包的”src/examples”目录下找到。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。
1.创建本地示例文件
在”/usr/hadoop”目录下创建文件夹”file”。
接着创建两个文本文件file1.txt和file2.txt,使file1.txt内容为”Hello World”,而file2.txt的内容为”Hello Hadoop”和“hello mapreduce”(两行)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4936
4936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









