






创建矩阵: A = np.array([[2, 3], [0, 1]])
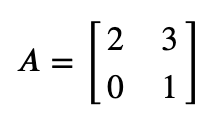
2.矩阵乘法: b = A @ x (A和x都是矩阵,这里就是正常的矩阵相乘)
3. 矩阵元素相乘: b = A * x
4. 矩阵元素相加: b = A + x
5. 取出矩阵中单独的元素: b = A[0, 0] (这里可以输出:2,A的00位置的元素)
6. 取出矩阵中的一整行row: b = A[0, :]

7. 取出矩阵中的一整列column:b = A[:, 0]

8. 矩阵转置: A_Transpose = A.T
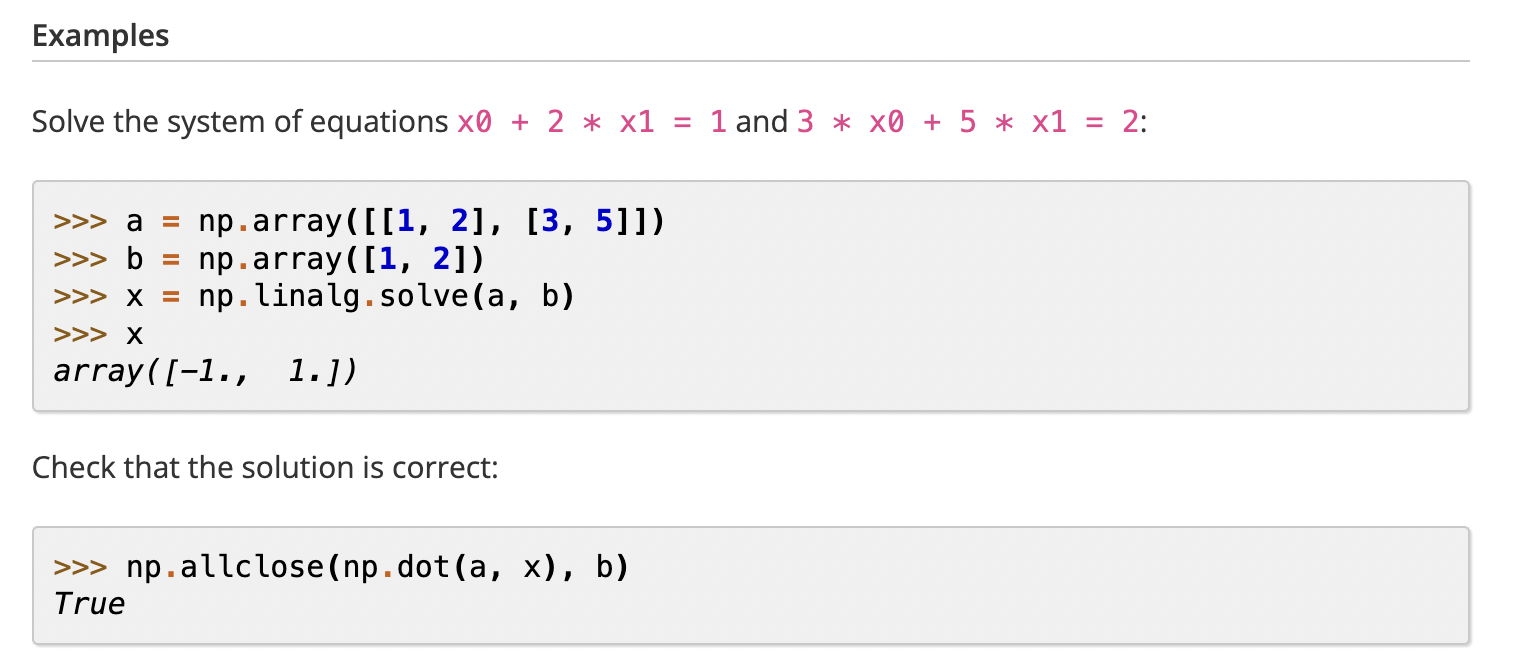
9. 解决线性方程: x = np.linalg.solve(A, B)
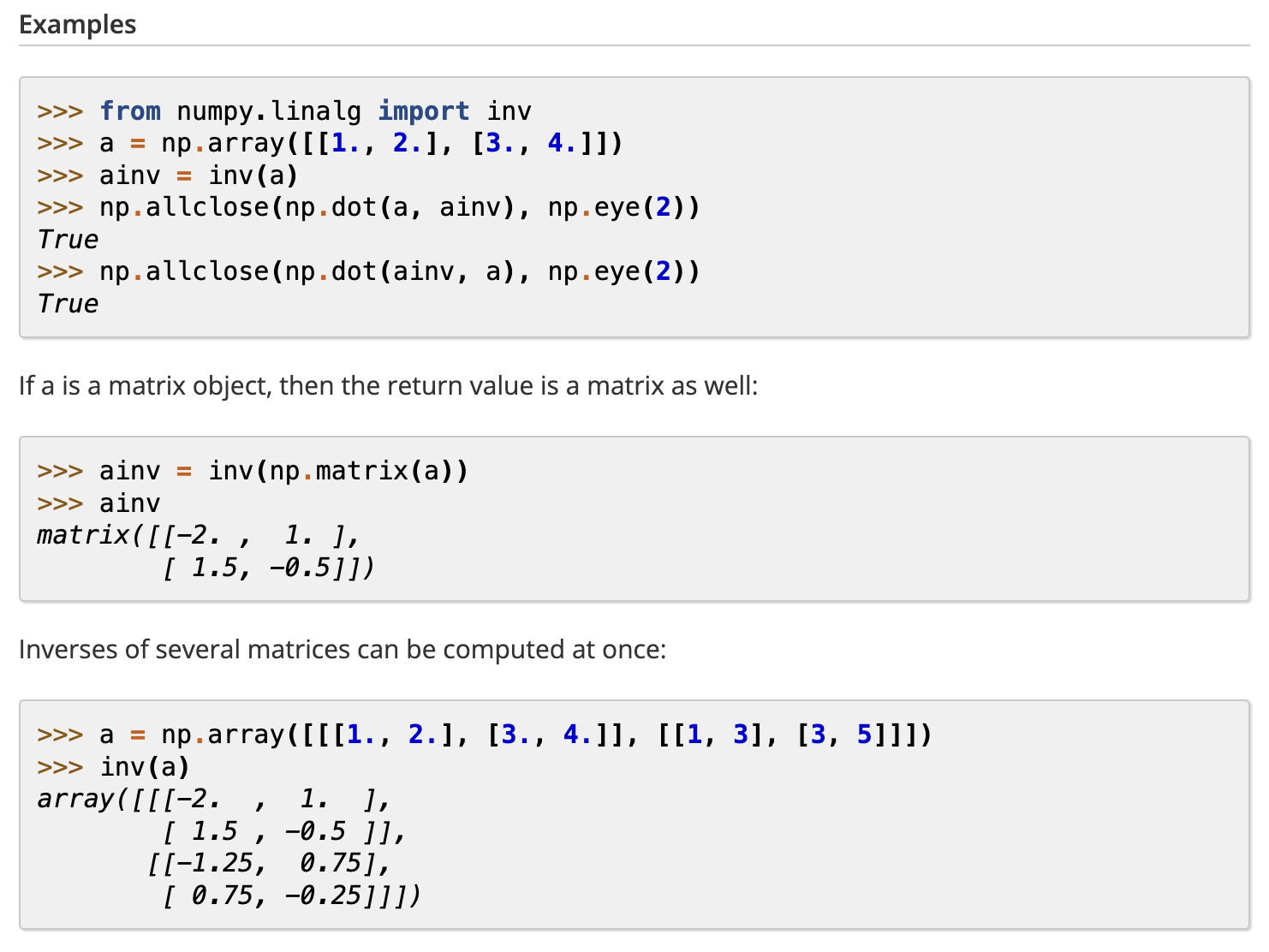
10. 矩阵的可逆计算: A_inv = np.linalg.inv(A)
11. 矩阵的伪逆计算(moore-penrose inverse): B = np.linalg.pinv(a)
12. 高斯消元的思路:
找到每一列的最大值
将最大值的那一行移到“最上方”(第一次循环就是挪到第一行,第二次循环就是将最大值挪到第二行....)
将“最上方”的元素变成1
将除了“最上方”那一行的下面所有列元素都变成0
循环上述操作,直到所有min(行数,列数)完成步骤(因为矩阵最多有min(行数,列数)的pivot)
13. Kmeans的思路:(一切的目的都是为了找到最小的training loss)
先明确初始时K(clusters)的数量,同时确定每个cluster的中心点
将training data中的所有点与每个cluster的中心点的距离计算出来
每个training data选取距离最近的中心点
重新计算每个clusters的中心点,并回到步骤2,直到每个cluster中没有新的点的加入(一切如旧)即停止
14.两种聚类的方法(clustering method):
agglomerative(凝聚):先由几个不同的clusters构成一个大的clusters
divisive(分裂):初始都在一个cluster中,接着分裂成不同的组合
【怎么来明确cluster:使用cluster的中心点(centroid)作为代表/在training data中随便找一个点】

















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









