







论文阅读笔记(11):Adaptive Self-Paced Deep Clustering with Data Augmentation,用数据增强的自适应Self-Paced深度聚类
摘要
深度聚类通过联合执行特征学习和聚类分割,获得了比传统聚类更好的性能。尽管许多深度聚类算法已经出现在各种应用中,但大多数算法都无法学习到健壮的面向聚类的特征,这反过来又会影响最终的聚类性能。为了解决这个问题,我们提出了一种两阶段的深度聚类算法,该算法结合了数据增强和自步学习(self-paced learning)。
具体地说:
在第一阶段,我们通过使用随机位移和旋转给定干净示例来增强示例来训练自动编码器,从而学习稳健的特征;
在第二阶段,通过使用这些增强示例的fine-tunning编码器来更新干净例的聚类分配,鼓励学习到的特征是面向聚类的。
在调整编码器时,损失函数中每个增强示例的目标是聚类中心,干净示例被分配到该聚类。目标计算不正确的示例可能会误导编码器网络。为了稳定网络训练,我们在每次迭代中利用自适应自步学习选择最有说服力的示例。大量的实验验证了我们的算法在四个图像数据集上的性能优于现有的算法。
1 简介
聚类在数据挖掘和机器学习领域得到了广泛的研究。传统的聚类算法,如 k k k-means、高斯混合模型(GMM)和层次聚类通常根据内在相似性对手工特征上的数据进行分组。众所周知,这些功能是为一般目的而设计的,可能不适用于特定任务。一些聚类算法,包括谱聚类和核 k k k-means将数据转换为一个新的特征空间,在这个空间中聚类任务变得更加容易。然而,这些方法通常具有有限的转换能力或具有较高的计算复杂度。
深度神经网络(DNN)在高度非线性变换(或特征学习)方面表现出惊人的能力。最近,一些研究采用DNN进行聚类,聚类性能有了显著提高。其基本思想是,好的特征有助于产生好的聚类结果,而后者反过来又指导DNN学习更好的特征。这两个过程无缝连接以实现卓越的性能。这被称作深度聚类(Deep Clustering),即通过DNN联合执行特征学习和聚类。
大多数现有的深度聚类算法通过使用由聚类中心和分配定义的损失函数来调整DNN的参数,这通常是基于上次迭代中DNN的输出获得的。我们观察到这些方法没有明确地考虑边缘示例对网络训练的影响。由于DNN的目标是学习更适合聚类的特征,因此聚类边界附近的示例可能无法提供令人信服的指导信息。这与有监督学习不同,监督学习预先给出所有目标标签,因此所有示例都可以给出可信的监督信号。
实际上,监督学习中的边缘示例在搜索类边界方面起着更重要的作用。在深度聚类中,靠近聚类边界的不可靠示例可能会混淆甚至误导DNN的训练过程,导致令人不满意的性能。另一方面,这些聚类算法也忽略了在有监督深度学习模型中广泛应用的数据增强技术,以提高泛化能力。
在本文中,我们提出了ASPC-DA算法,该算法分为两个阶段:预训练和过滤。在预训练阶段,我们通过最小化重建损失来训练使用增强数据的自动编码器。如我们所知,自动编码器可以将数据从相对高维稀疏空间转换为低维紧凑表示空间。我们使用求值数据来增强学习表示所在流形的平滑度。然后在第二阶段,我们通过使用定义为类内平方和的聚类损失来调整编码器(特征提取器)。为了稳定训练过程,我们采用自适应自适应学习,选择“容易”(靠近聚类中心)的测试样本作为训练集,并逐步添加较难的示例。与典型的自定步调学习不同,我们的自适应变体没有超参数,并且总是将边缘示例排除在训练之外。我们还采用了与训练前阶段相同的数据扩充类型,以进一步促进特征学习。我们的实验表明,在各种数据集上,与最先进的聚类算法相比,我们具有巨大的竞争优势。本文的主要贡献如下:
- 我们提出了一个简单但有效的深度聚类模型,该模型结合了自步学习和数据增强。
- 我们推导并采用了一种无需额外超参数的、自适应的自步学习,用于消除特征学习过程中聚类边界附近示例的负面影响。
- 本研究揭示了自步学习和数据扩充对深度聚类算法的影响,并提供了扩展现有深度聚类算法的可能途径。
2 相关工作
我们将依次回顾现有的深度聚类算法、自步学习和数据增强技术。
2.1 深度聚类
深度聚类是一系列采用深度神经网络学习面向聚类特征的聚类算法。如图1所示,其损失函数通常由网络损失 L n L_n Ln和聚类损失 L c L_c Lc组成,其中网络损失用于学习可行特征,聚类损失鼓励特征点形成分组。网络损失可以是自动编码器(AE)的重建损失、变分自动编码器(VAE,variational autoencoder)的变分损失或一般对抗性网络(GAN)的对抗性损失。聚类损失可以是任何现有聚类算法的损失,如 k k k-means、高斯混合模型(GMM)和层次聚类。一些工作设计了一种新的、合并了网络损失的聚类损失,在这种情况下不再需要单独的网络损失。我们称之为聚类DNN(CDNN),即仅通过聚类损失 L c L_c Lc训练的网络。根据DNN的类型,现有的深度聚类算法可分为四类:基于AE的深度聚类、基于VAE的深度聚类、基于GAN的深度聚类和基于CDNN的深度聚类。
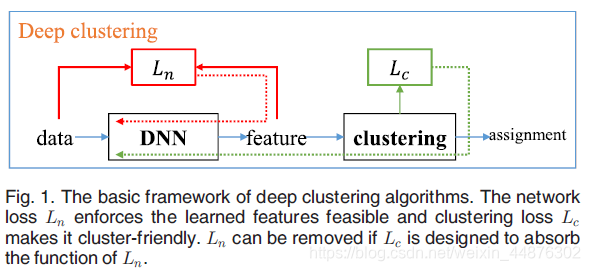
基于AE的深度聚类
它们直接将有助于执行聚类的先验知识合并到自动编码器的目标函数中。例如选择 k k k-means的目标函数作为聚类损失 L c L_c Lc。Jabi等人进一步提出了一种软正则化的深度 k k k-means算法。Peng等人将先验稀疏信息纳入自动编码器的隐藏表示中,以便同时适应局部和全局子空间结构。Dizaji和Guo等人都借用了深嵌入聚类(DEC)的目标函数作为聚类损失,但前者使用卷积自动编码器,后者使用全连接的自动编码器。Ji等人提议将子空间聚类的自表达特性合并到完全连接的自动编码器的中间层。基于AE的深度聚类的优点是,现有的浅层聚类算法和正则化可以很容易地用于自动编码器的训练。但是必须引入一个超参数来平衡重建损失和聚类损失。
基于VAE的聚类
该算法强制执行潜在代码,以遵循可以描述聚类结构的预定义分布。Jiang等人采用高斯混合模型对潜在代码进行建模。在最大化证据下界后,通过学习的GMM模型推断聚类分配。Dilokthanakul等人提出了一个类似的公式,但他们的结果在经验上比Jiang等人差。这种算法除了输出聚类结果外,还能够生成逼真的图像。然而,它们的计算复杂度很高。
基于GAN的聚类
与基于VAE的算法具有相同的思想。作为一个典型的例子,InfoGAN最大化了GAN噪声变量的固定小子集与从分类分布中采样噪声变量的观测值之间的互信息。ClusterGAN使用离散连续混合物对GAN的噪声变量进行采样,以使潜在空间中的聚类成为可能。DASC将子空间聚类的自扩展特性合并到对抗性变分自动编码器中,但无法扩展到大规模数据集。Yu和Zhou介绍了GAN混合模型(GANMM),旨在扩展高斯混合模型(GMM)。基于GAN的算法具有GAN本身就难以解决的问题,例如难以收敛和模式崩溃。
基于CDNN的聚类
基于CDNN的算法明确定义了一个损失,该损失被用作聚类模型和DNN的目标。Yang等人提出了一个循环框架,该框架采用单一加权三重损失,将聚类和特征学习过程集成到单个模型中。虽然该算法非常有效,但由于其循环过程非常耗时。Xie等人通过定义分布P和Q之间的KL散度 注 1 ^{注1} 注1,提出了一种深嵌入聚类(DEC)算法,其中Q是由Student的t-分布测量的软标签分布,P是由Q导出的目标分布。最小化KL散度可以同时获得面向聚类的特征和聚类分割。然后,Li等人通过合并卷积神经网络和正态化目标函数的分布来扩展DEC。Peng等人将聚类损失定义为成对样本中心分布之间的差异。他们假设给定示例和集群中心之间的分布对于流形上的不同距离度量是不变的。基于现有的深度聚类框架,Boots等人将单一CNN替换为多个预训练CNN以提取特征。Lin等人提出了一种基于预训练深度特征的密度聚类算法,用于对无约束人脸图像进行聚类。Caron等人直接使用 k k k-means的损失函数来训练卷积网络,并在大规模数据集上获得良好的聚类性能。这个种聚类方式有一个简单而优雅的目标,但需要仔细设计。
KL散度(相对熵):衡量不同策略之间的差异,使用KL散度来做模型分布的拟合损失。
2.2 自步学习
自步学习模拟了人类的学习过程:从简单到困难。给出一些新任务的示例,我们倾向于首先选择最简单的示例来学习基本知识。在对任务的知识有所提高之后,我们可以收集更难的例子,逐渐获得更多的知识。在这一进程结束时,我们可能会获得有关该任务的所有知识。这种学习策略被认为更有效。关键问题是如何定义“易用性”。根据我们现有的知识,我们给出的答案越接近真实答案,示例就应该越容易。
在机器学习问题中,损失函数的值作为“易用性”的度量。训练中应使用多简单的示例由阈值 λ \lambda λ控制。正式地说,给定训练示例 D = { ( x 1 , y 1 ) , ⋯ , ( x n , y n ) } D=\{(x_1,y_1),\cdots ,(x_n,y_n)\} D={
(x1,y1),⋯,(xn,yn)}和参数为 w \bf w w的学习模型 f f f,传统的机器学习问题是:
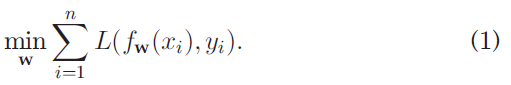
即通过调整参数来最小化模型所有预测值和所有对应标签之间的loss之和。
而自步学习的问题变为:
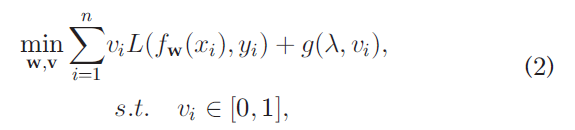
其中 v = [ v 1 , . . . , v n ] ⊤ \textbf v=[v_1,...,v_n]^\top v=[v1,...,vn]⊤为各个示例的权重,而这个 g ( λ , v i ) g(\lambda,v_i) g(λ,vi)被称作自步正则化项(self-paced regularization term)。这两个参数可以通过交替搜索策略(ASS)进行优化。对于简单硬加权自步学习,有 g ( λ , v i ) = − λ v i , v i ∈ { 0 , 1 } g(\lambda,v_i)=-\lambda v_i,v_i\in\{0,1\} g(λ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









