







https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
本文仅为翻译
摘要
虽然自我监督学习的总体思想在不同的模式中是相同的,但实际的算法和目标却有很大的不同。为了让我们更接近于一般的自我监督学习,我们提出了data2vec,一个对语音、NLP或计算机视觉使用相同学习方法的框架。其核心思想是使用标准Transformer体系结构下的自蒸馏(self-distillation),根据输入的隐藏视图预先记录完整输入数据的潜在表示。Data2Vec预测的是包含整个输入信息的情境化潜在表示,而不是预测特定于模态的目标,如单词、视觉标记或人类语音单元(本质上是局部的)。
1 简介
为了更接近以更通用的方式学习环境的机器,我们设计了data2vec,这是一个通用自监督学习框架,适用于图像、语音和文本,其中学习对象在每种模式中都是相同的。目前的工作统一了学习算法,但仍然分别学习每个模态的表示。我们希望,单一算法将使未来的多模式学习更简单、更有效,并通过多种模式产生更好地理解世界的模型。
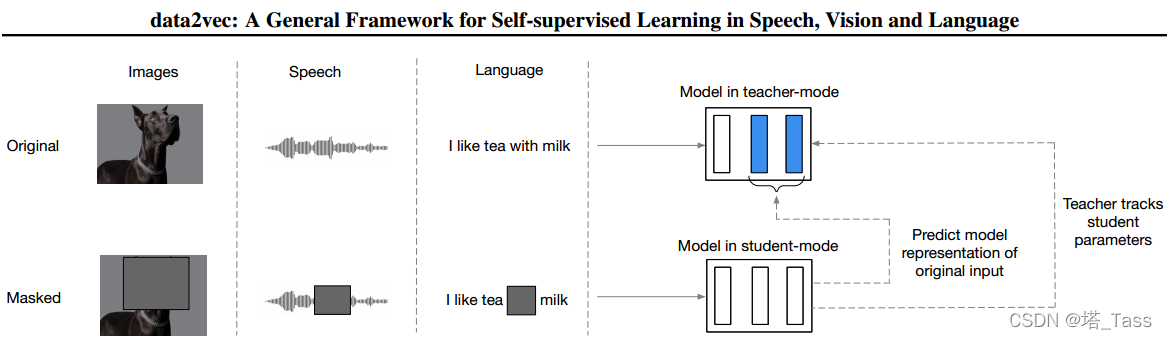
我们的方法将Mask预测与潜在目标表示的学习相结合,但通过使用多个网络层作为目标对后者进行了推广,并表明该方法可以跨多模态工作。具体来说,我们训练一个现成的Transformer网络,我们在教师或学生模式下使用它(图1):
我们首先构建完整输入数据的表示,其目的是作为学习任务的目标(教师模式)。接下来,我们对输入样本的Masked版本进行编码,用它预测完整的数据表示(学生模式)。教师的权重是学生的指数衰减平均值。由于不同的模态具有非常不同的输入,例如像素与单词,我们使用文献中的模态特定特征编码器和Mask策略。由于我们的方法适用于学习者自身的潜在网络表示,因此可以将其视为许多特定于模态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









