






论文阅读笔记:Not Too Deep Clustering via Clustering the Local Manifold of an Autoencoded Embedding, 对自动编码embedding的局部流形进行(没那么深的)深度聚类
摘要
深度聚类算法通常将表示学习与深度神经网络相结合,优化聚类和非聚类损失。在这种情况下,自动编码器通常与聚类网络连接并共同学习。相反,我们建议学习自动编码嵌入,然后进一步搜索底层流形。为简单起见,我们随后使用浅层聚类算法对其进行聚类,而不是使用更深层次的网络。我们研究了一些基于原始数据和自动编码嵌入的局部和全局流形学习方法,在我们的框架中,UMAP能够找到嵌入的最佳聚类流形。这表明在自动编码嵌入上的局部流形学习对发现更高质量的簇类是有效的。这些结果为深度聚类显示了一个有希望的研究方向。
简介
深度学习的最新算法可以有效地从原始数据中学习,而不需要手动特征提取和选择。自动编码器是自动学习数据表示的一种流行方法。自动编码器通过深度神经网络有效地学习数据的内在结构,并通过学习重建原始数据(例如,通过瓶颈结构诱导压缩表示)来实现。从原始数据中学习到的压缩表示可以用于一系列任务。
这一研究领域也影响了无监督领域,深度聚类已经成为一个热门的研究领域。深度聚类是指使用深度神经网络进行聚类的过程,通常使用CNN或自动编码器从原始数据中自动学习的特征,并使用深度神经网络进行聚类。例如,Guo等人对自动编码器进行预训练,用k-means初始化深度聚类网络的权重。随后,自动编码器继续学习表示,但与聚类网络联合训练以寻求良好的聚类效果。
在这项工作中,我们提出了一种简单的方法,N2D,它在自动编码表示的基础上,用流形学习技术有效地取代了聚类网络。具体地说,我们打算让它在这个表示中找到一个保持距离的流形。通过该方法更新embedding,我们就可以用传统的非深度聚类算法对其进行聚类。N2D用流形学习方法和简单的非深度聚类算法取代了聚类网络的复杂性,降低了深度聚类的深度,通过额外的流形学习步骤实现了优异的性能。
相关工作
深度聚类方法使用深度神经网络进行聚类,通常涉及两个不同的过程,一个是学习表示,另一个是实际聚类。这一过程可以单独进行,也可以联合进行。用于深度聚类的深度神经网络多种多样,包括MLP、CNN和GAN。当用于表征学习步骤时,这些方法将优化特定损失,例如重建损失或生成性对抗损失。另外需要增加一个聚类损失来指导算法找到更多的对聚类友好特征。这些损失通常以某种方式组合(如联合训练),其中,聚类损失的权重通常比非聚类损失的权重低得多。
使用两种不同损失进行交替方法是使用单个组合损失,将表示和聚类集成到单个递归模型的后向和前向过程中。缺点是由于模型的重复性效率相当低。
我们感兴趣的是学习整个embedding的流形,优化聚类性。
方法论
Autoencoder, AE
AE在学习表示时并不显式地考虑局部结构。我们将证明,通过使用流形学习技术(该技术充分考虑了局部结构)来增强自动编码器。
AE的两个部分——编码器和解码器——实质上是通过最小化惩罚输入输出不一致性的函数、试图将输入复制到输出的两个深度神经网络。这通常通过正则化的形式实现,如强制将输入压缩到低维空间。
虽然自动编码器在许多特征表示任务中表现良好,但它们并没有明确地保留它们学习到的表示中数据的距离。我们相信,考虑到这一点可以提高学习到聚类的质量。
Isomap (等距映射)
有多种多样的学习技术明确地寻求在数据中保持距离。Isomap[25]是一种非线性方法,包含由加权图构成的测地距离。测地距离是在流形上测量的两点之间的距离,因此利用测地距离等值线图可以了解流形的结构。根据数据构造k-近邻图,其中两个节点之间的最短距离被视为测地距离。Isomap在数据中的所有点之间构造一个全局成对测地相似矩阵,因此,Isomap可以被认为是一种全局流形学习技术。我们的假设是,在自动编码嵌入上学习局部流形将导致更好的结果,但我们将研究N2D中Isomap的使用,特别是了解全局方法如何执行和检验我们的假设。
t-SNE (t-distributed Stochastic Neighbor Embedding)
t-分布随机近邻嵌入是一种非线性方法,在创建嵌入时具有优化局部距离的特定目标。t-SNE算法的第一阶段是在数据中构建成对的概率分布,以便相似点具有较高的被选择概率,而不相似点具有极低的被选择概率。在第二阶段,t-SNE定义映射点上的概率分布,最小化两个分布之间的KL散度。
UMAP
最近提出的流形学习方法是UMAP(统一流形近似和投影),它寻求准确地表示局部结构,但也被证明能更好地结合全局结构。
UMAP依赖于三个假设,即数据均匀分布在黎曼流形上,黎曼度量是局部常数,流形是局部连通的。根据这些假设,可以通过搜索具有最接近的等价模糊拓扑结构的数据的低维投影来发现嵌入。
UMAP与Isomap类似,它使用基于k-NN的图形算法来计算点的最近邻。UMAP首先构造一个加权k近邻图,并从该图计算低维布局。该低维布局经过优化,以基于交叉熵的模糊拓扑表示尽可能接近原始布局。
它有许多影响性能的重要超参数。第一个是考虑局部近邻的数量。这表示保留多少局部结构和捕获多少全局结构的粒度之间的权衡。第二个是目标嵌入的维数。在我们的方法中,我们将维度设置为我们正在寻找的类的数量。第三个是嵌入空间中点之间的最小间距。较低的最小间距将更准确地捕捉真实的流形结构。
注:N2D可以使用Isomap、t-SNE和UMAP作为流形学习器,实验结果表明UMAP效果更好
N2D
通过学习AE嵌入后的流形,特别是学习一个强调局部性的流形,我们可以实现更适合聚类的嵌入。然而,由于在无监督设置中通常无法交叉验证超参数,因此为每种方法选择合理的默认参数非常重要。
N2D的步骤总结如下:
- 对原始数据应用自动编码器以学习初始表示。
- 我们通过使用保持局部距离的流形学习方法搜索更具聚类性的流形来对AE进行重嵌入。
- 最后对这种新的、更具聚类性的嵌入,我们应用最终的浅层聚类算法。
也可以用数学符号表示N2D:
C
=
F
C
(
F
M
(
F
A
(
X
)
)
)
C=F_C(F_M(F_A(X)))
C=FC(FM(FA(X)))
其中C为最终聚类结果,
F
C
F_C
FC为聚类算法,
F
M
F_M
FM为流形学习器,
F
A
F_A
FA为自动编码器,X为原始数据。
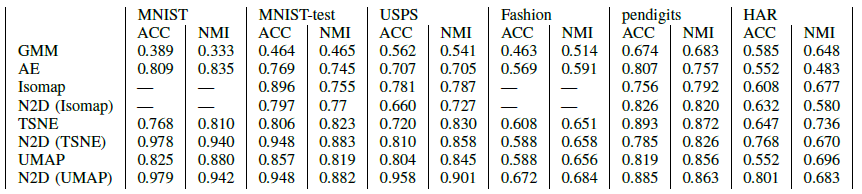
实验结果
数据集
MNIST、MNIST-test、USPS、Fashion、pendigits。都是小型数据集。
Metrics
ACC和NMI
Role of Each Component of N2D















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









