







摘要
我们研究了零样本视觉和语言导航(ZS-VLN)的任务,这是一个实际但具有挑战性的问题,代理学习按照语言指令描述的路径导航,而不需要任何路径指令注释数据。通常,指令具有复杂的语法结构,并且通常包含各种动作描述(例如,“继续越过”、“离开”)。如何正确地理解和执行这些操作需求是一个关键问题,而缺乏带注释的数据使其更加具挑战性。请注意,一个受过良好教育的人可以很容易地理解路径指令,而不需要任何特殊的训练。在本文中,我们利用基础模型的视觉和语言能力,提出了一种动作感知的零样本VLN方法(A2Nav)。具体来说,所提出的方法包括一个指令解析器和一个动作感知的导航策略。指令解析器利用大型语言模型(如GPT-3)的高级推理能力,将复杂的导航指令分解为一系列特定于动作的对象导航子任务。每个子任务都要求代理本地化对象,并根据关联的操作需求导航到特定的目标位置。为了完成这些子任务,我们从自由收集的特定于动作的数据集中学习了一个动作感知的导航策略,这些数据集揭示了每个动作需求的不同特征。我们使用学习到的导航策略来依次执行子任务来遵循导航指令。大量的实验表明,A2Nav在R2R-Habitat和RxR-Habitat数据集上取得了良好的ZS-VLN性能,甚至超过了监督学习方法。
先前方法的缺陷
现有的零样本VLN方法忽略了指令中的行动,因为它们更关注指令中的地标。我们的A2Nav正确地解析了指令中的动作需求,并准确地执行它们,以成功地遵循导航指令。

本文方法
我们利用一个大型语言模型作为指令解析器(instruction parser)来解析所有地标及其相关的操作需求。然后将指令分解为一系列特定于动作的对象导航子任务,其中需要agent来定位地标,并根据与该地标相关联的特定动作需求进行导航。

定义了五种动作的导航策略。GO TO, GO PAST, GO INTO, GO THROUGH, EXIT。

对于GOTO动作需求,我们直接使用一个训练过的ZSON模型作为导航器,而不进行微调,因为ZSON可以很好地处理这个动作需求。对于期望代理到达对象并继续前进并经过对象的GOPAST动作需求,我们在路径的中间捕获目标图像。对于期望代理穿过门口进入目标区域的GOINTO动作需求,我们对穿过两个区域的路径进行采样,并在该路径的末端对目标图像进行采样。对于期望代理从区域的一侧走到另一侧的遍历行动需求,我们随机抽样从一个入口开始,到另一个入口结束的路径。目标图像在路径的中间被捕获。对于退出动作需求,将以与GOINTO动作需求相同的方式采样路径,而目标图像是在路径的开始处捕获的。我们使用与ZSON相同的学习管道对这些数据集上训练过的ZSON模型进行了微调。
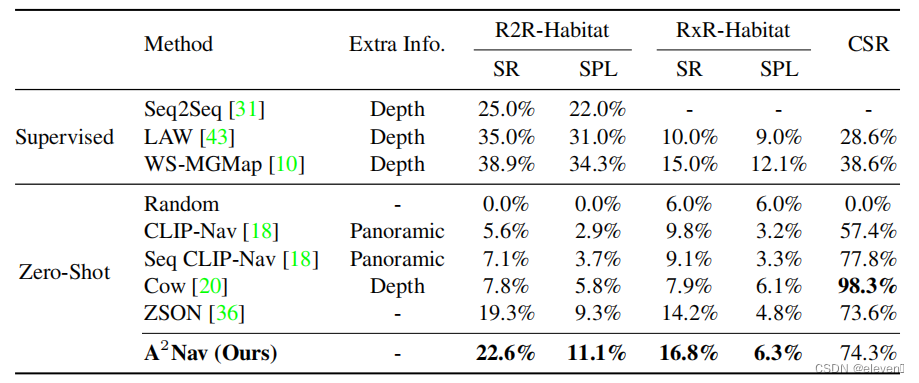
实验结果
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









