






前言:关于VOC数据集
下面以VOC 2007为例分析一下里面数据集格式:
首先来个直观的文件夹结构截图:(备注下面四个.txt文件是需要运行相应py文件才能生成的)
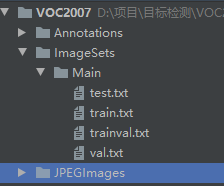
文件结构解释:
├── Annotations 进行 detection 任务时的标签文件,xml 形式,文件名与图片名一 一对应
├── ImageSets 包含三个子文件夹 Layout、Main、Segmentation,其中 Main 存放的是分类和检测的数据集分割文件
├── JPEGImages 存放 .jpg 格式的图片文件
├── SegmentationClass 存放按照 class 分割的图片
└── SegmentationObject 存放按照 object 分割的图片
├── Main
│ ├── train.txt 写着用于训练的图片名称, 共 2501 个
│ ├── val.txt 写着用于验证的图片名称,共 2510 个
│ ├── trainval.txt train与val的合集。共 5011 个
│ ├── test.txt 写着用于测试的图片名称,共 4952 个
注意train.txt+test.txt不等于总共的图像数量。
备注:linux安装detectron2是非常好安装的,但是windows是非常困难
首先下载资源链接:
链接:https://pan.baidu.com/s/1L0_hfzig4xsZOPNGWk_mnQ
提取码:usix
1.环境配置
备注:这里以我们研究生实验室linux配置为例进行安装
备注:实验室环境是Ubuntu 18.04.5(可视化桌面) 、CUDA环境cuda11.1
- conda create -n detectionWyh python=3.6
- 激活detectionWyh 虚拟环境 conda activate detectionWyh
- 安装 torch 和torchvision:
注意此时需要注意:torch 和 torchvision版本需要由cuda版本决定。
可以参考链接cuda版本对应torch和torchvision版本:
我们实验室是cuda11.1 安装下面这个(注意这里没有选择安装pytorch 1.8.0因为此版本运行detectro2会报错,后面再提)
conda install pytorch1.7.0 torchvision0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch
- 安装COCO API:
因为需要detectron2需要使用COCO数据集
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
- 验证一下上面是否安装成功:

- OpenCV, Demo和显示时需要使用,
pip install opencv-python - 上面是为了安装detectron2或者打基础使用的或者更好使用detectron2,下面正式安装detectro2:
首先给大家一个链接:
https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html (注意这个网址要根据实际配置进行修改 你可以尝试比如你的cuda=11.1 你可以改为cu111 然后与之对应的torch是1.8你可以该torch1.8)
打开进入网址:

注意其实cuda11.1可以使用cuda11.0最后一个版本号不大影响。
上面链接中加粗的可以根据自己实际电脑配置修改,然后:
pip install detectron2==0.3 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
版本号需要自己指定一个,然后程序会根据你的python版本自动进行下载相应版本安装
- 安装谷歌实验室
pip install google-colab
至此detectron2安装完成
2.测试demo
备注:这一步测试demo大家按照兴趣可以去尝试或者不尝试
备注:这里demo是指detectron2官网的一个项目,可以用来快速感受一下detectron2
- 首先得说明一下,这个demo需要我们进行在网站上下载:
下载网址:https://github.com/facebookresearch/detectron2
- 下载好解压后detectron2-main文件目录结构:

- 以上面文件路径为例,我们在linux下首先进入detectron2-main文件夹下(cd命令),找到一张图片作为输入input1.jpg放在detectron2-main下面(你也可以放在其他路经下面,但是下面执行路径时你要指定比如你放在demo/input1.jpg 那么你就要对下面命令进行修改比如–input demo/input1.jpg),再解释一下–opts MODEL.WEIGHTS 我们可以选择从https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md 下下载我们想要的权重,然后把权重文件放到你想要放置的路径里面就像你input1.jpg做的那样。
python demo/demo.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml
--input input1.jpg
--output .
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
解释:–opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl 会直接从网上下载,我们可以预先下载到本地,然后指定路径即可。
- 上面一切弄好之后,会在当前文件夹下看到已经被处理好的input1.jpg,比如大致时这个样子

3.使用detectron2前奏–数据集转换
detectro2需要coco数据集所以我们需要将labelImag标注的pascal voc数据集转换为 coco数据集:
首先下载下面文件:
文件链接:统一放到文章开头

2. 首先先根据make_main_txt.py中文档说明运行make_main_txt.py文件 (文档说明已经很详细)

3. 根据appliance.py中文档说明运行appliance.py文件 (文档说明已经很详细)

4. 拷贝train、val文件夹到 ,注意这里换了一个工程 detectro2_train项目下
备注:也就是说我们一个工程是用来生成train,val(coco要求的数据格式),然后另一个工程是用来训练模型

5. 根据train_hat.py文档说明 修改一些东西,就可以跑出模型了















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









