







一、前言
Detectron2是一个用的比较广泛的目标检测和分割的深度学习框架,最近在电脑上配置环境后就准备跑一下,发现上手没那么方便,官方教程也不清晰,还得自己摸索,所以暂记一下个人成功训练的方法以及遇见的bug解决。
要看bug解决,直接跳到文末。
二、训练detectron2(自制目标训练集进行训练)
1、需要把数据集转化成COCO数据集的格式,即
----dataset
--------annotations 存放标注文件
--------------instances_train2017.json
--------------instances_val2017.json
--------train2017 存放训练集图片
--------val2017 存放测试集图片
如上是对应COCO数据集格式文件夹文件的位置,如果缺少经验就按标准的来.
COCO数据集格式参考官网介绍:https://cocodataset.org/#format-data
其中目标检测:
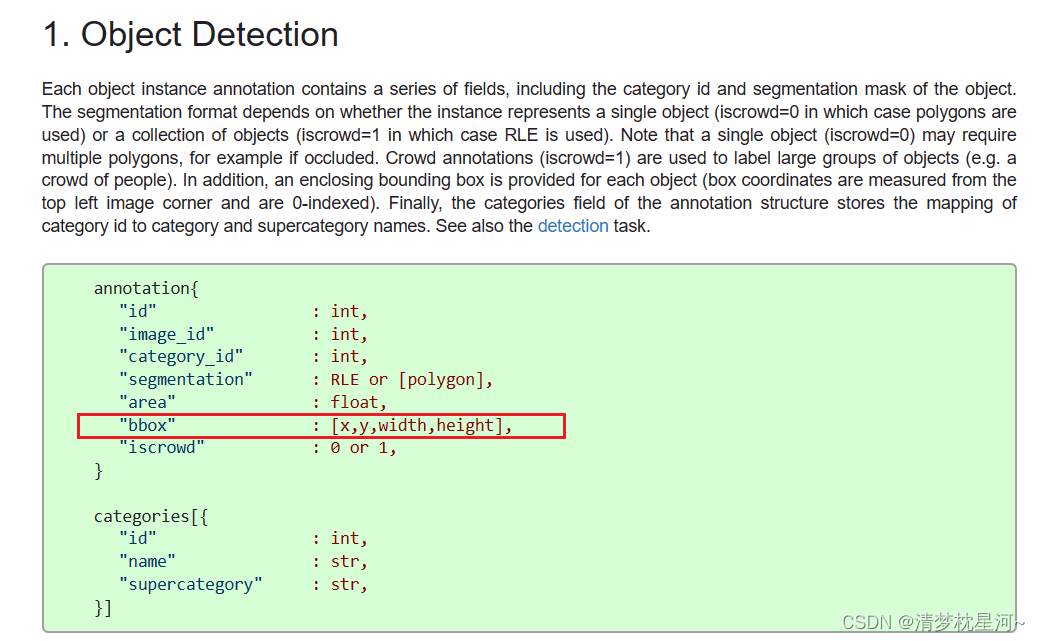
如果标注文件对目标的表示格式(如yolo的txt)与COCO上面的格式不一样,需要自行转化统一格式
2、配置网络及数据集路径:
这一块可以找到很多教程,官方的或者各大网站博主的,我一开始看得有点懵,觉得挺复杂,不够清晰,摸索了一下,现在更清楚一些。
总结共有两种方法,一种不太灵活,适合不太想改代码的人,按部就班;第二种灵活一些,需要自己清楚需要什么进行训练来进行灵活配置。
第一种按部就班的:
①先对你的数据集进行注册,假如是自制的目标检测数据集,在detectron2/detectron2/data/datasets/builtin.py的如下位置:
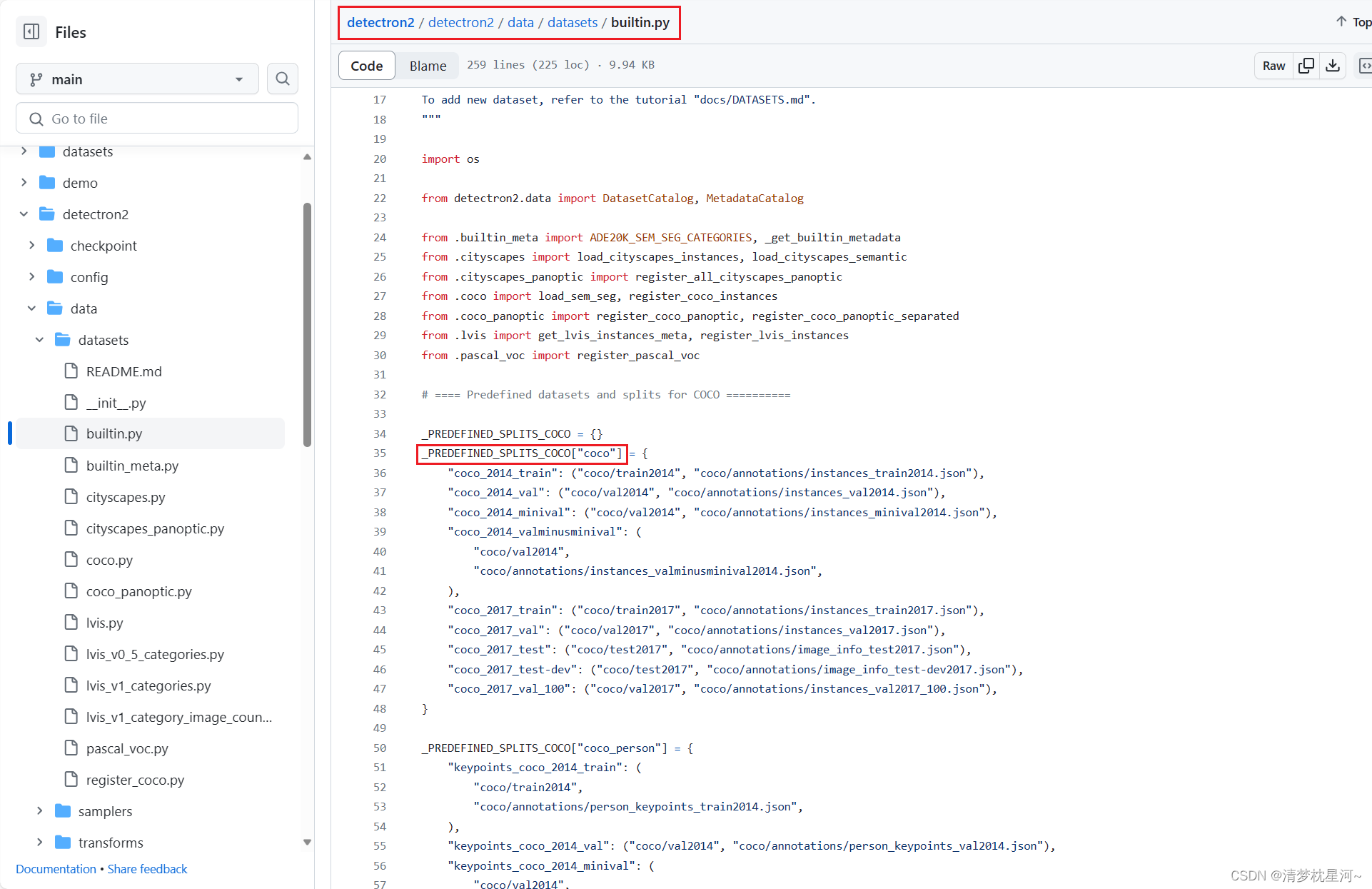
_PREDEFINED_SPLITS_COCO = {}
_PREDEFINED_SPLITS_COCO["coco"] = {
"coco_2014_train": ("coco/train2014", "coco/annotations/instances_train2014.json"),
"coco_2014_val": ("coco/val2014", "coco/annotations/instances_val2014.json"),
"coco_2014_minival": ("coco/val2014", "coco/annotations/instances_minival2014.json"),
"coco_2014_valminusminival": (
"coco/val2014",
"coco/annotations/instances_valminusminival2014.json",
),
"coco_2017_train": ("coco/train2017", "coco/annotations/instances_train2017.json"),
"coco_2017_val": ("coco/val2017", "coco/annotations/instances_val2017.json"),
"coco_2017_test": ("coco/test2017", "coco/annotations/image_info_test2017.json"),
"coco_2017_test-dev": ("coco/test2017", "coco/annotations/image_info_test-dev2017.json"),
"coco_2017_val_100": ("coco/val2017", "coco/annotations/instances_val2017_100.json"),
#自制数据集,注意路径别写错了.
"my_train": ('coco/train2017/images', "coco/annotations/instances_train2017.json"),
"my_val": ('coco/val2017/images', 'coco/annotations/instances_val2017.json'),
# "my_train" : 数据集名称
# 'coco/train2017/images' : 图片存放路径
# 'coco/annotations/instances_train2017.json' : 标注信息json路径
}
"""同一代码下找到如下代码"""
# True for open source;
# Internally at fb, we register them elsewhere
if __name__.endswith(".builtin"):
# Assume pre-defined datasets live in `./datasets`.
#_root = os.path.expanduser(os.getenv("DETECTRON2_DATASETS", "datasets"))
"""datasetroot的路径需要在my_train和my_dval的上一级,即coco的上一级,
比如,my_train='./xxx/xxx/coco/annotations/xxx.json'
"""
datasetroot = './xxx/xxx/'
_root = os.path.expanduser(os.getenv("DETECTRON2_DATASETS", datasetroot))
register_all_coco(_root)
register_all_lvis(_root)
register_all_cityscapes(_root)
register_all_cityscapes_panoptic(_root)
register_all_pascal_voc(_root)
register_all_ade20k(_root)
②然后修改 detectron2/detectron2/data/datasets/builtin_meta.py
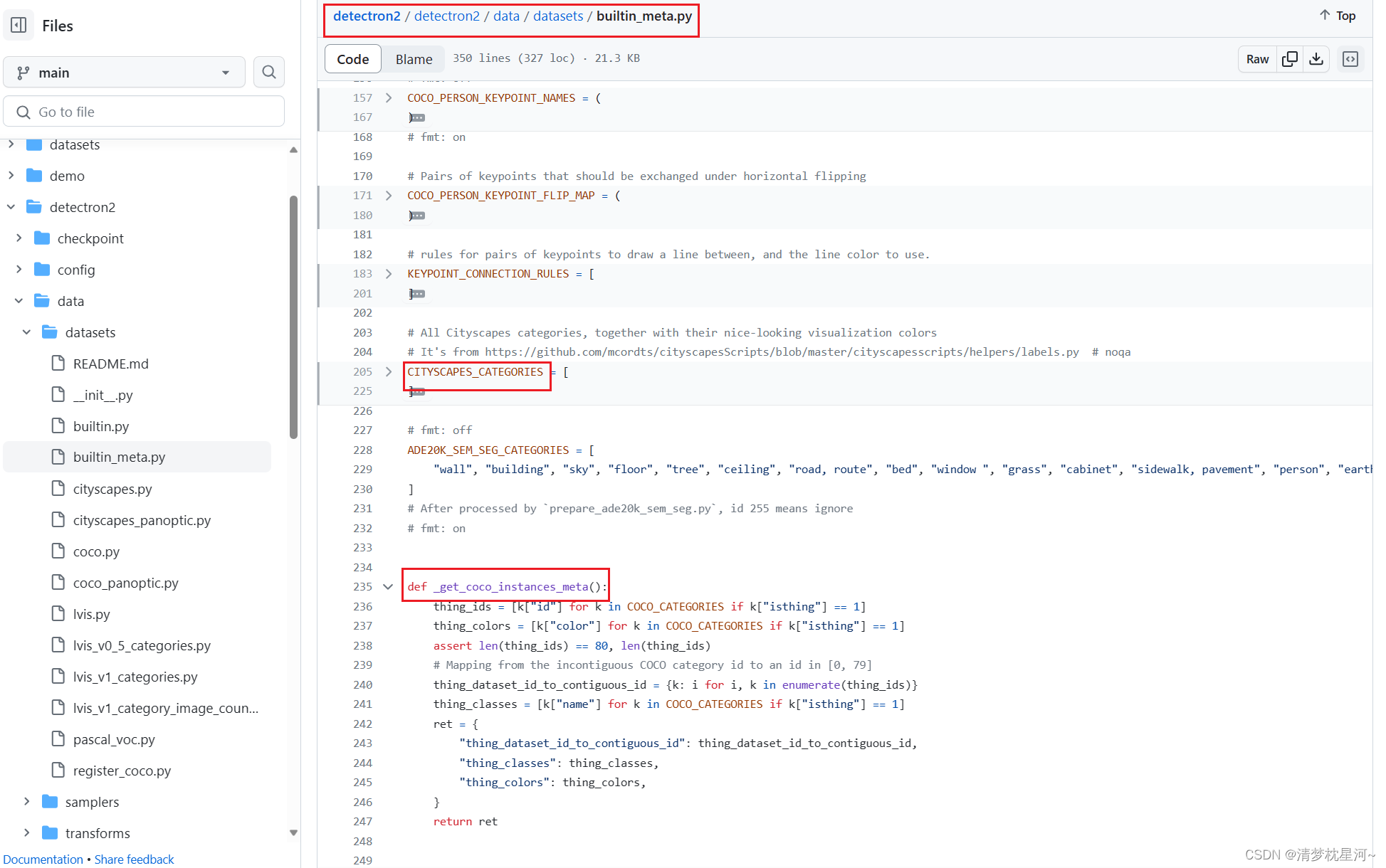
添加自己数据集的类别信息和一个获取自己数据集信息的函数:
"""要加"""
MY_COCO_CATE=[
{"color": [220, 20, 60], "isthing": 1, "id": 1, "name": "my_cate"},
]
"""要加"""
def _get_coco_meta_mycate():
thing_ids = [k["id"] for k in MY_COCO_CATE if k["isthing"] == 1]
thing_colors = [k["color"] for k in MY_COCO_CATE if k["isthing"] == 1]
assert len(thing_ids) == 1, len(thing_ids) #自己的数据集有几类就改成数字几
# Mapping from the incontiguous COCO category id to an id in [0, 79]
thing_dataset_id_to_contiguous_id = {k: i for i, k in enumerate(thing_ids)}
thing_classes = [k["name"] for k in MY_COCO_CATE if k["isthing"] == 1]
ret = {
"thing_dataset_id_to_contiguous_id": thing_dataset_id_to_contiguous_id,
"thing_classes": thing_classes,
"thing_colors": thing_colors,
}
return ret
"""要改"""
def _get_builtin_metadata(dataset_name):
if dataset_name == "coco":
#return _get_coco_instances_meta()
return _get_coco_meta_mycate()
if dataset_name == "coco_panoptic_separated":
return _get_coco_panoptic_separated_meta()
elif dataset_name == "coco_panoptic_standard":
meta = {}
③这样基本上就配置完了,可以直接训练:
–config-file 参数可选择具体网络,要预训练模型可以自己先下载
python ./tools/train_net.py --config-file ./configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml
第二种灵活一点的方法,可以直接在一个代码里把网络跑起来,所以需要在这一个代码里把相关信息加进去
①复制一个train_net.py文件,在里面直接配置数据集等信息
#!/usr/bin/env python
# Copyright (c) Facebook, Inc. and its affiliates.
import logging
import os
from collections import OrderedDict
import detectron2.utils.comm as comm
from detectron2.checkpoint import DetectionCheckpointer
from detectron2.config import get_cfg
from detectron2.data import MetadataCatalog
from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, hooks, launch
from detectron2.evaluation import (
CityscapesInstanceEvaluator,
CityscapesSemSegEvaluator,
COCOEvaluator,
COCOPanopticEvaluator,
DatasetEvaluators,
LVISEvaluator,
PascalVOCDetectionEvaluator,
SemSegEvaluator,
verify_results,
)
from detectron2.modeling import GeneralizedRCNNWithTTA
"""添加代码"""
from detectron2.data.datasets import register_coco_instances
from detectron2.data import MetadataCatalog
classnames=['person']
mydata_train_images='./xx/xxx/train2017' #可以直接写绝对路径
mydata_train_labels='./xx/xxa/train.json' #可以直接写绝对路径
mydata_val_images='./xx/xxb/val2017' #可以直接写绝对路径
mydata_val_labels='./xx/xxa/val.json' #可以直接写绝对路径
register_coco_instances("mydata_train", {}, mydata_train_labels, mydata_train_images)
MetadataCatalog.get("mydata_train").thing_classes=classnames
register_coco_instances("mydata_val", {}, mydata_val_labels, mydata_val_images)
MetadataCatalog.get("mydata_val").thing_classes=classnames
"""到这里,再后面"""
def build_evaluator(cfg, dataset_name, output_folder=None):
if output_folder is None:
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
evaluator_list = []
evaluator_type = MetadataCatalog.get(dataset_name).evaluator_type
if evaluator_type in ["sem_seg", "coco_panoptic_seg"]:
evaluator_list.append(
SemSegEvaluator(
dataset_name,
distributed=True,
output_dir=output_folder,
)
)
if evaluator_type in ["coco", "coco_panoptic_seg"]:
evaluator_list.append(COCOEvaluator(dataset_name, output_dir=output_folder))
if evaluator_type == "coco_panoptic_seg":
evaluator_list.append(COCOPanopticEvaluator(dataset_name, output_folder))
if evaluator_type == "cityscapes_instance":
return CityscapesInstanceEvaluator(dataset_name)
if evaluator_type == "cityscapes_sem_seg":
return CityscapesSemSegEvaluator(dataset_name)
elif evaluator_type == "pascal_voc":
return PascalVOCDetectionEvaluator(dataset_name)
elif evaluator_type == "lvis":
return LVISEvaluator(dataset_name, output_dir=output_folder)
if len(evaluator_list) == 0:
raise NotImplementedError(
"no Evaluator for the dataset {} with the type {}".format(dataset_name, evaluator_type)
)
elif len(evaluator_list) == 1:
return evaluator_list[0]
return DatasetEvaluators(evaluator_list)
class Trainer(DefaultTrainer):
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
return build_evaluator(cfg, dataset_name, output_folder)
@classmethod
def test_with_TTA(cls, cfg, model):
logger = logging.getLogger("detectron2.trainer")
# In the end of training, run an evaluation with TTA
# Only support some R-CNN models.
logger.info("Running inference with test-time augmentation ...")
model = GeneralizedRCNNWithTTA(cfg, model)
evaluators = [
cls.build_evaluator(
cfg, name, output_folder=os.path.join(cfg.OUTPUT_DIR, "inference_TTA")
)
for name in cfg.DATASETS.TEST
]
res = cls.test(cfg, model, evaluators)
res = OrderedDict({k + "_TTA": v for k, v in res.items()})
return res
def setup(args):
"""
Create configs and perform basic setups.
"""
cfg = get_cfg()
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
cfg.DATASETS.TRAIN = ("mydata_train",)
cfg.DATASETS.TEST = ("mydata_val",) # 没有不用填
cfg.DATALOADER.NUM_WORKERS = 2
#预训练模型文件,可自行提前下载
cfg.MODEL.WEIGHTS = r"detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl"
#或者使用自己的预训练模型
# cfg.MODEL.WEIGHTS = "../tools/output/model_00999.pth"
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.OUTPUT_DIR = "./output_trainsample/"
cfg.SOLVER.MAX_ITER = 10000
cfg.SOLVER.BASE_LR = 0.002
cfg.TEST.EVAL_PERIOD= 100
# cfg.INPUT.MAX_SIZE_TRAIN = 400
# cfg.INPUT.MAX_SIZE_TEST = 400
# cfg.INPUT.MIN_SIZE_TRAIN = (160,)
# cfg.INPUT.MIN_SIZE_TEST = 160
cfg.MODEL.DEVICE = 'cpu'
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1# 类别数
cfg.MODEL.WEIGHTS = "./model_final.pth" # 预训练模型权重
#cfg.SOLVER.IMS_PER_BATCH = 6 # batch_size=2; iters_in_one_epoch = dataset_imgs/batch_size
ITERS_IN_ONE_EPOCH = int(118/ cfg.SOLVER.IMS_PER_BATCH)
# (ITERS_IN_ONE_EPOCH * ) - 1 # 12 epochs
cfg.SOLVER.MOMENTUM = 0.9
cfg.SOLVER.WEIGHT_DECAY = 0.0001
cfg.SOLVER.WEIGHT_DECAY_NORM = 0.0
cfg.SOLVER.GAMMA = 0.1
cfg.SOLVER.STEPS = (500,)
cfg.SOLVER.WARMUP_FACTOR = 1.0 / 1000
cfg.SOLVER.WARMUP_ITERS = 300
cfg.SOLVER.WARMUP_METHOD = "linear"
cfg.SOLVER.CHECKPOINT_PERIOD = ITERS_IN_ONE_EPOCH - 1
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True) #传入output文件夹 存放训练好的权重等
cfg.freeze()
default_setup(cfg, args)
return cfg
def main(args):
cfg = setup(args)
if args.eval_only:
model = Trainer.build_model(cfg)
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
)
res = Trainer.test(cfg, model)
if cfg.TEST.AUG.ENABLED:
res.update(Trainer.test_with_TTA(cfg, model))
if comm.is_main_process():
verify_results(cfg, res)
return res
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
if cfg.TEST.AUG.ENABLED:
trainer.register_hooks(
[hooks.EvalHook(0, lambda: trainer.test_with_TTA(cfg, trainer.model))]
)
return trainer.train()
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args,),
)
这样就在一个代码里都配置好了,接下来可以直接训练:
python ./tools/train_net_copy.py --config-file ./configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml
这就是两套方法都介绍完了,第二种明显方便很多。
三、bug解决:KeyError: Dataset ‘m’ is not registered! Available datasets are…
在配置过程中,突然报了这个错,自己看着错也很纳闷,找了一下发现也有其他人遇到,但是没有看到有效的解决办法,后面在个人的尝试中,发现了这个bug很好解决,就是要细心。
因为我用第一种办法是可以成功跑起来的,是第二种方法卡到我了,主要是开始验证的阶段出现的,我还以为没加载到验证集数据,很纳闷,看了别人的配置文件,发现一个很傻逼的操作,就是:
cfg.DATASETS.TRAIN = ("mydata_train")
cfg.DATASETS.TEST = ("mydata_val") # 没有不用填
我的 验证集cfg.DATASETS.TEST = (“mydata_val”) 没在括号里加逗号,改成
cfg.DATASETS.TRAIN = ("mydata_train")
cfg.DATASETS.TEST = ("mydata_val",)
就可以了,而且就只有 cfg.DATASETS.TEST = (“mydata_val”) 受影响,训练集加没加都不受影响。
我找的办法里说,括号里要求是元组格式,可是没说直接的办法,走了一点弯路。

















 2561
2561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











