










基于keras_yolov3的代码训练自己的数据集,完成一个手势识别小测试。
环境:windows10、python3.6、keras2.15、opencv3、pycharm2017
前言:
- 本人也是小白一枚,按照网上的一些教程和一些前辈的指导简单的改了些代码实现的,在此感谢一些有帮助过的文章的作者,一些前辈的指导。
- 之前还做过一个基于tensorflow2.0+CNN的手势识别程序,这里上了目标检测的算法(yolov3)。
- 如果有还没看过YOLO视频就想直接上手的同学,不太建议。可以不太懂的yolo算法的细节具体实现,但是怎么也得懂一些YOLO的基本过程吧,建议先看下吴恩达的机器学习视频,还有一些别的视频教程。
先看一下效果图吧:

第一步:下载需要的keras代码,自定义数据集测试图片
- yolo3 Keras 代码地址: https://github.com/qqwweee/keras-yolo3 (必须下载的文件!)
- 论文地址:YOLO V1 https://pjreddie.com/darknet/yolov1/
- YOLO V2 https://pjreddie.com/darknet/yolov2/
- YOLO V3 https://pjreddie.com/media/files/papers/YOLOv3.pdf
- YOLO V3 中文版 https://zhuanlan.zhihu.com/p/34945787
- 下载完第一个链接的文件之后把它放在一个全是英文的路径下!!!
***emmm允许我先说一些废话(大神忽略)…,因为刚刚接触yolo算法不懂得算法内容,但是又想用这个算法实现一些功能的话,这下面的话是我的理解,因为我也是小白所以我知道我刚接触的时候看网上教程,就说你要第一步做这个,第二步做那个的,虽然我们会做但是不知道为什么要这么做,在脑子里没有一个概念,很懵。当然因为我们的思想和那些大牛的想法完全不一样,这可能就是对新手不友好的体现吧,希望我的这篇文章对你能有一些帮助吧。下面是正式的内容(都是我自己的理解可能有错误,希望大佬前辈们发现后能斧正。
先说下为什么要下载上面的那个keras的代码: - yolo算法是用的darknet框架,我们都知道现在深度学习的框架很多,darknet这个框架比较小众出现问题很难搞,也很少有人维护没有什么社区什么的解决问题,所以有很多tensorflow、pytorch复现这个算法的,keras就是一种相对比较简单的一种方法,因为这个算法比较复杂我们自己很难完全手动的完成它,所以我们只能做到修改别人的代码来完成自己需要的功能(当然大佬忽略)我们下载的这个keras的代码就是别人实现的,然后我们在此基础上修改,来完成一些我们自己需要的功能的。
1、
下载下来差不多是这个样子的,文件夹里面差别多有这些东西(引用别的博客的图)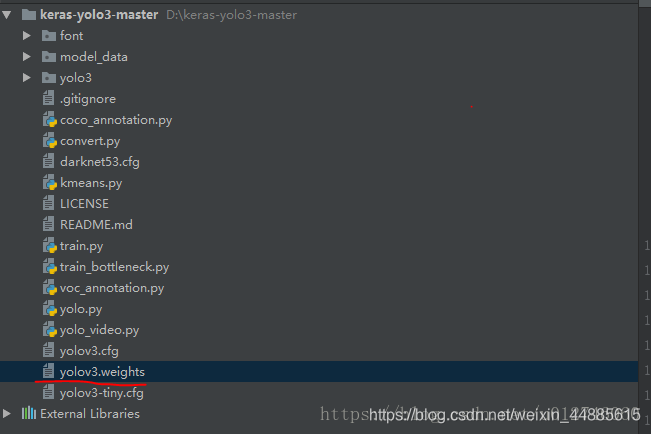
这个画红线部分是yolo算法之前已经训练好的权重文件,下载下来是没有的,需要自己下载,这个网上很多就不说了,这个权重文件是用于自带的数据集的检测的,这里要自定义自己的数据集,就要训练自己数据集的权重文件,当然这个权重文件也是有用的,因为在训练的时候可以导入进去在这基础训练这样就能够训练的快一些吧,可以这样理解,类似迁移学习。当然也可以不用这个权重文件,重头开始训练,那这样在之后一个地方需要做一个修改,之后再说。还有一点需要说的是,这个.weight文件是darknet这个框架才能够识别(用)的文件,需要转为tensorflow能够识别的.h文件,这个转的方法网上有很多,不会转的可以直接下载去.h文件也可以。下载下来放到
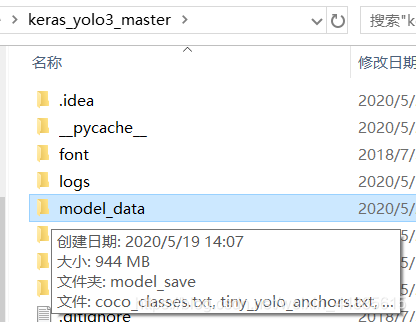 我鼠标指的这个文件夹下即可。
我鼠标指的这个文件夹下即可。
2、
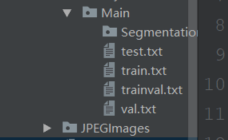
要自己手动建一个像下面这样的文件目录结构,就是结构必须和这里面这样一模一样,包括文件夹名字等等,如果没有某个文件夹就自己建一个文件夹。这一步很重要,因为我们是按着别人的代码来改的,所以我们也必须按着别人的框架来操作,除非大牛完全懂里面的代码、那另说。
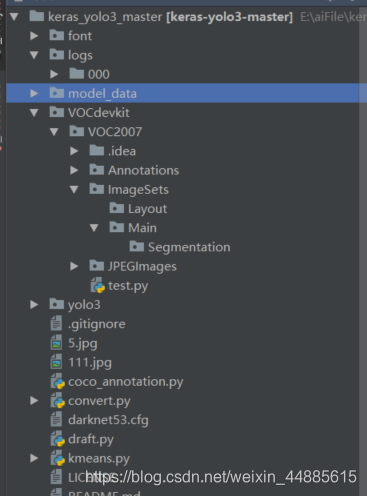
里面有一些文件你可以没有,就是下载下来是哪样就哪样就行,因为是我后来加进去的,可以无视,但是整个的文件夹结构必须完全一致。注意我有打开的文件夹和没有打开,打开的文件夹就是文件夹里还需要有文件夹,没打开的文件夹就是建个空的文件夹在那即可。说明:这个picture文件夹可以没有,因为这是我自己后来加的。还有那个.idea和test.py文件也可以没有,其他所有文件夹和上面一致。注意:JPEGImage文件夹下还有两个文件夹,图片可以不用,下一步用自己的图片。
3、
建立自己的数据集:将自己要训练的所有图片按照序号全部复制到JPEGImage文件夹下 ,这里的图片需要只要是按顺序就行,不需要什么标注区分,但是注意名字不能有空格,中文字符等等。使用labelimg软件标注自己的数据集,使用这个软件挨个来标注自己的所有图片,这里我就不详细说,附上教程训练自己的数据集也可以直接按着这里面的教程一步步做,也能成功,或者结合着本文看,能更理解一些。
在Annotations文件夹里得到所有标注文件之后基本就完成了自定义训练集,然后就开始代码的修改。
因为标注有点多,挺麻烦,我就只标注了120张手势的图片所以效果可能没有那么好,你们可以尝试扩大训练集,我一共分了六类,我以下就以我的数据集为例,来说要改哪些地方。
4、
先在VOC2007文件夹下面建一个python文件,这边是叫test.py然后输入下面的代码,然后运行:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
然后就会在Main文件夹里生成四个.txt文件。
5、
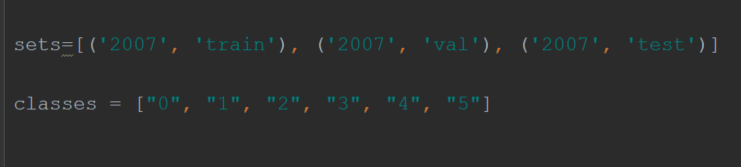
然后打开最外层的文件夹里面的voc_annotation.py文件,修改里面的classes列表,改为自己分的类别,我这里是分的六类。所以是这样的:
会在当前这个文件夹下面生成3个 2007_xxxx.txt文件夹,把前面的2007_去掉即可。这里用的是voc数据集,如果有用coco数据集的话可能会不一样。
6、
还是打开当前文件夹下面的yolov3.cfg文件修改一些训练的参数。看下面:
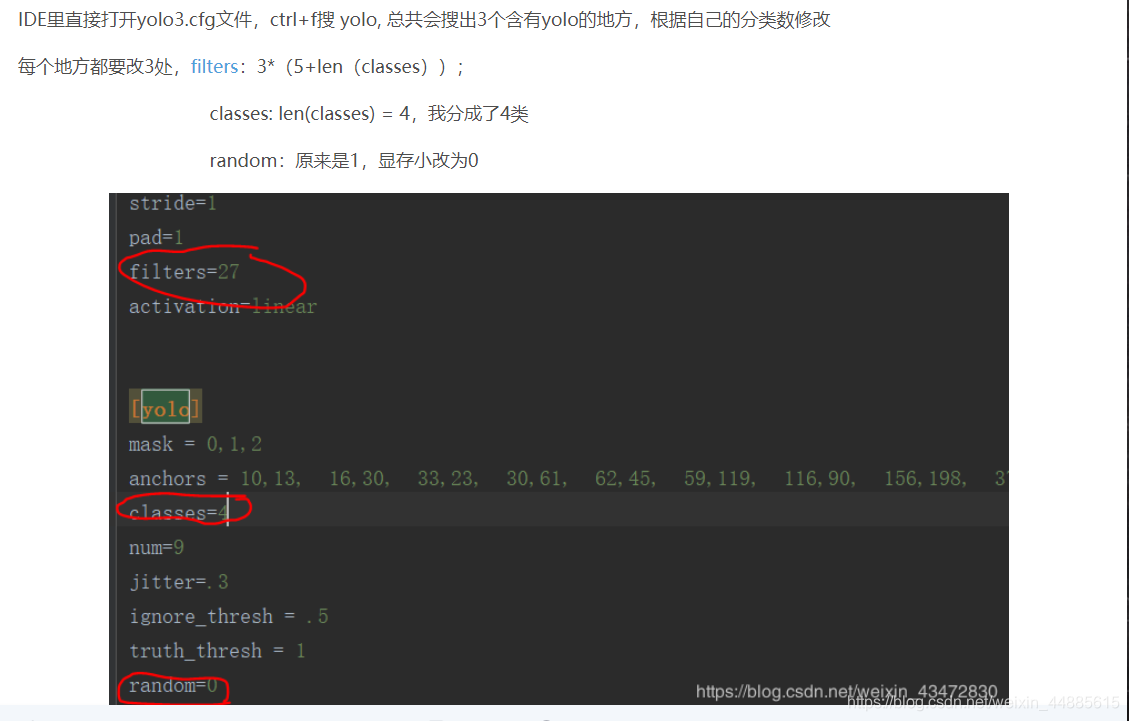
一共有三处yolo要改,每处改的内容是一样的,改三遍,注意这个filters是需要根据自己的类别数量算出来的,不同的类别不一样。
7、
打开model_data文件夹下面的文件修改类别名称
就是这个文件夹下面的coco_classes.txt和voc_class.txt文件,这张图里面你们没有的文件也没关系就改需要改的就行。改成自己的类的名字
注意这里可能会报错,最好是打开文件夹,然后用Noteoad++来修改,或者在pycharm里修改吧,不要用txt记事本打开修改,可能会有格式错误。推荐:
8、
然后就是修改train.py里的内容了:
首先,如果电脑内存运行,并且有英伟达的gpu的话默认即可,如果只要cpu则需要在最前加两句话:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" # 仅用cpu
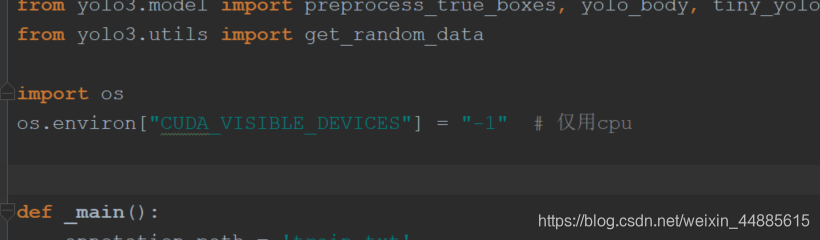
这里可能会有坑,会在后面总结。
然后前面说过如果要用yolo训练的权重的话在这里把load_pretrained=True
改为True,否则改为False,如果改成True注意下面参数还有一个参数路径weights_path=,要把你的那个.h5文件路径写对即可 。

然后需要改这个 batch_size,有两处,下面还有一处要改的,建议都改为1吧,如果电脑好的话可以适当调大2-3。
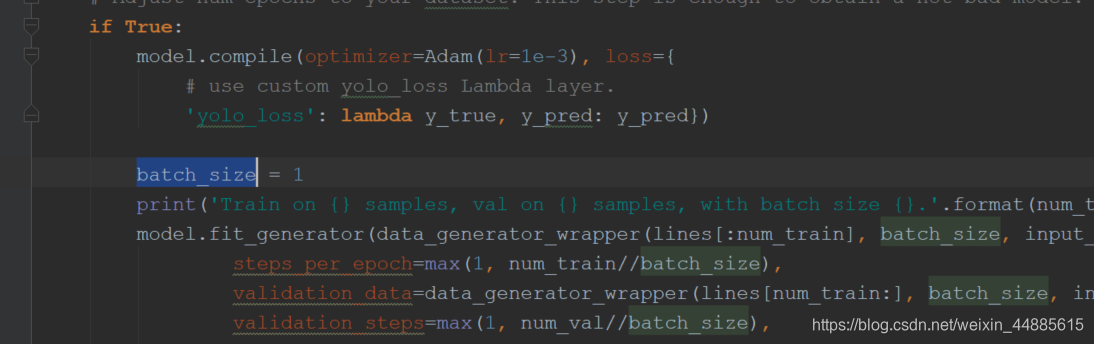
到这里之后运行train.py文件就可以开始训练了,一共有两次 训练前一次0-50 后一次50-100,一次执行完gpu大约需要30分钟左右或者更短,cpu则要4个小时甚至更长,会在logs的000文件夹下面生成一个叫trained_weights_final.h5的文件,复制下放到model_data文件夹下名字改为改成yolo.h5就可以了。
9、
图片测试代码,建一个随便什么名字的.py文件,然后粘贴,改下路径就可以测试自己的图片了。
from yolo import YOLO
from PIL import Image
def detect_image():
yolo = YOLO()
images = Image.open("2.jpg")
result = yolo.detect_image(images)
yolo.close_session()
result.show()
detect_image()
注意train.py文件里的这部分要和自己的文件对应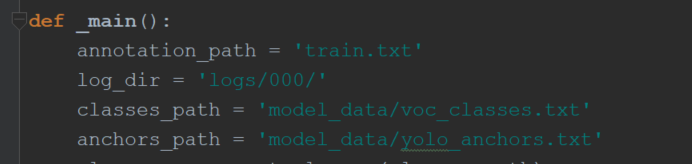
还有yolo.py里面的这部分也得注意,特别是权重名路径,这里的权重是刚刚训练好的权重路径,保存在model_data里的那个。
第二步:读取摄像头利用模型测试
from yolo import YOLO
from PIL import Image
import cv2 as cv
import numpy as np
def get_roi(frame, x1, x2, y1, y2):
dst = frame[y1:y2, x1:x2]
cv.rectangle(frame, (x1, y1), (x2, y2), (0, 0, 255), thickness=2)
return dst
def detect_image(yolo, images):
# yolo = YOLO()
# m = 0
# cv.imwrite("E:\\aiFile\\keras_yolo3_master\\picture\\%s.jpg" % m, images)
image = Image.fromarray(cv.cvtColor(images, cv.COLOR_BGR2RGB))
# image = Image.open("E:\\aiFile\\keras_yolo3_master\\picture\\0.jpg")
# print("image = ", image)
# print("images = ", images)
print("-----------------------")
result = yolo.detect_image(image)
res = np.asarray(result)
ress = cv.cvtColor(np.asarray(image), cv.COLOR_RGB2BGR)
cv.imshow("res", ress)
# print("result = ", res)
# result.show()
if __name__ == "__main__":
capture = cv.VideoCapture(0)
yolo = YOLO()
while True:
ret, frame = capture.read()
detect_image(yolo, frame)
c = cv.waitKey(50)
if c == 27:
yolo.close_session()
break
cv.waitKey(0)
capture.release()
cv.destroyAllWindows()
先给上当时用的代码填个坑,之后再做详细说明
总结
注意事项:
- 1、在过程中一定要注意文件夹名字,要与上述的一模一样,不然可能会报错
- 2、总结下可能会报错的点:1、图片路径出错:找不到xxx图片,分隔符要统一“\”,或者都用“/”如果是这个错误,可能是在修改运行voc_annotation这一步的时候有问题,改下里面的代码,如果路径正确文件夹里也有图片,可能就是图片名称出现了空格、中文字符等等python无法识别的字符。可能需要重新修改图片再重新标注了。2、keras的版本是2.15版本注意,版本太高可能也会报版本错误。3、运行GPU跑的时候可能会出现显存不够而出错,也有可能会在前50轮没问题很快就训练完了,在之后的50轮里出现GPU显存不够的报错,这个没有办法,只能全用CPU跑。
- 建议结合下面的参考博客,再结合本文帮助理解。
- 本人水平有限,如果有说错的地方希望前辈们能够斧正,我好修改学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









