






1. 应用背景
需要识别出图中紫色部分的数字,以及紫色的线。对于数字识别部分开始用了tensorrt-ocr但是识别不出来,后面改用了 easyocr 库,轻松上手并识别。

2. 紫色线识别
紫色的线的识别很好处理,直接上把图像转到HSV空间,提取紫色,然后再把提取出的轮廓分离出来,判断轮廓是否靠近图像底边,靠近的就是图中紫色的线了。
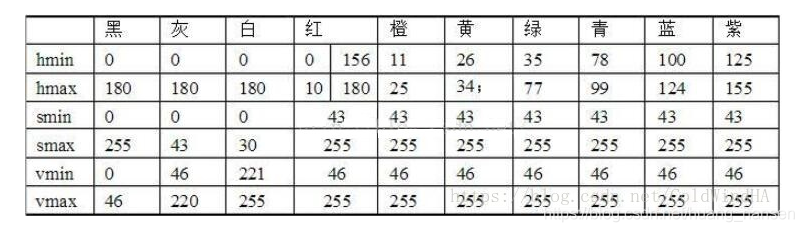
HSV的具体取值参考:
代码实现
import os
import cv2
import numpy as np
def show(img):
cv2.namedWindow("123", cv2.WINDOW_NORMAL)
cv2.imshow("123",img)
cv2.waitKey()
def rgLine(img):
n=0
hsv_img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 定义HSV中颜色的范围,例如这里是提取绿色
lower_green = np.array([125, 100, 100])
upper_green = np.array([155, 255, 255])
# 根据范围进行掩膜操作,提取绿色
binary = cv2.inRange(hsv_img, lower_green, upper_green)
show(binary)
contours, _ = cv2.findContours(binary, cv2.RETR_LIST,
cv2.CHAIN_APPROX_NONE) # 根据二值图找轮廓 cv2.CHAIN_APPROX_SIMPLE
for c in contours:
x,y,w,h=cv2.boundingRect(c)
maxY=y+h
if abs(maxY-720)<10:
n+=1
return n
if __name__=="__main__":
dir=r"D:\projects\data\leisi\s1"
files=[os.path.join(dir,f) for f in os.listdir(dir)]
for p in files:
img=cv2.imread(p)
n=rgLine(img)
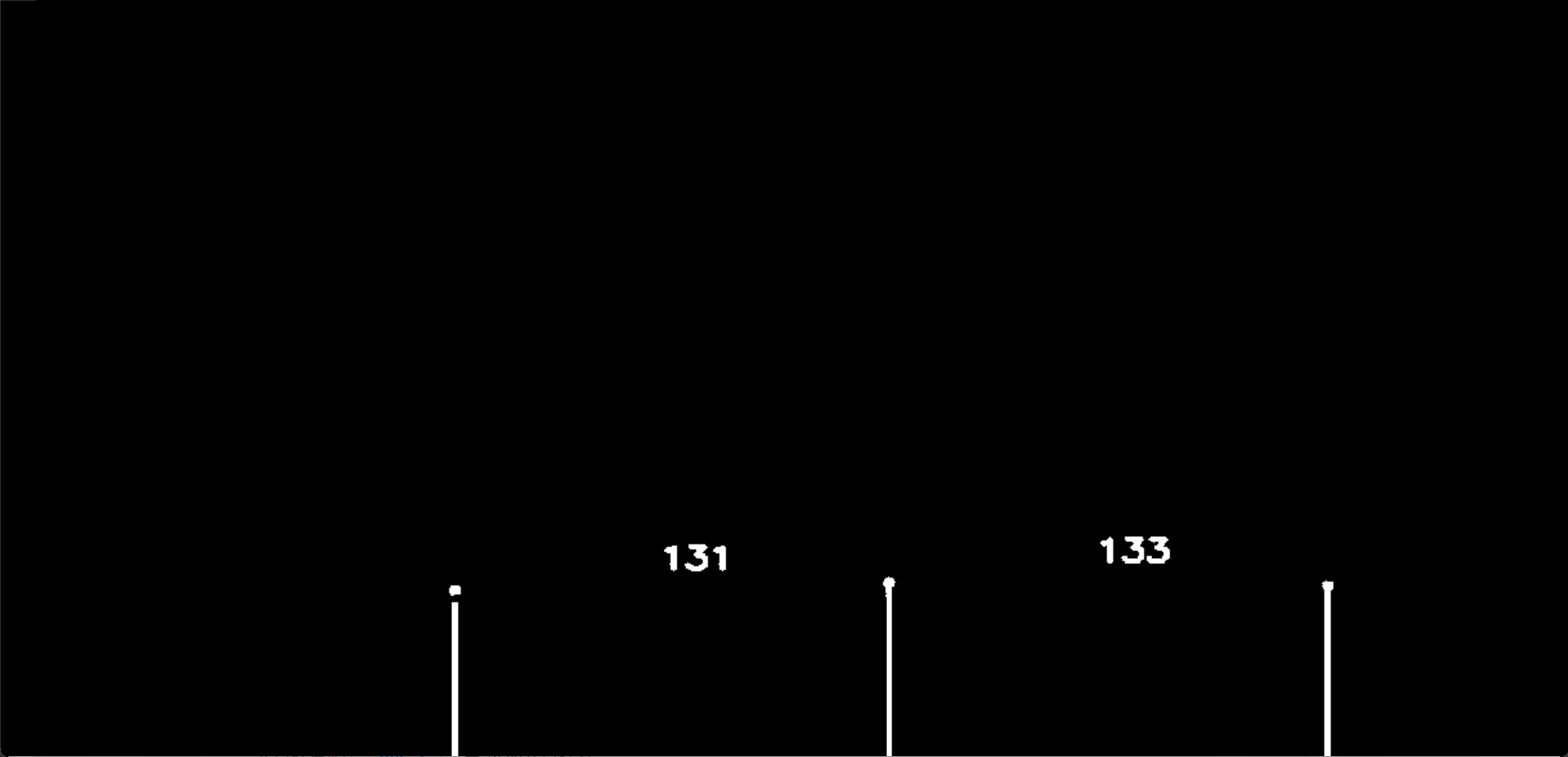
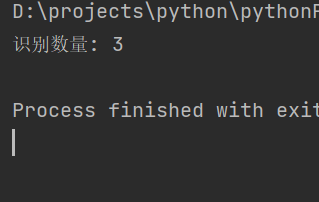
print("识别数量:",n)运行结果如下
3. 数字识别
import os
import cv2
import numpy as np
import easyocr
def getDigit(img):
results = reader.readtext(img)
digits = []
for result in results:
text = result[1]
if text.isdigit():
digits.append(int(text))
print(digits)
return digits
if __name__=="__main__":
dir=r"D:\projects\data\leisi\s1"
files=[os.path.join(dir,f) for f in os.listdir(dir)]
reader = easyocr.Reader(['en'])
for p in files:
img=cv2.imread(p)
n=getDigit(img)
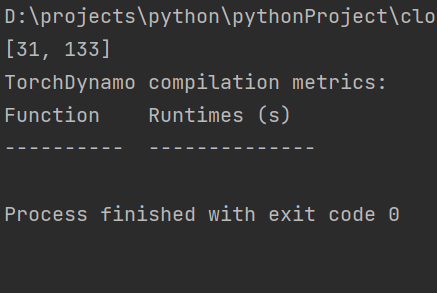
print("识别数量:",n)执行结果如下,131识别为了31,这里有点问题
改进办法,将紫色的数字通过HSV提取出来后再进行OCR的识别,
改进代码如下:
import os
import cv2
import numpy as np
import easyocr
def getDigit(img):
hsv_img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 定义HSV中颜色的范围,例如这里是提取绿色
lower_green = np.array([125, 100, 100])
upper_green = np.array([155, 255, 255])
# 根据范围进行掩膜操作,提取绿色
binary = cv2.inRange(hsv_img, lower_green, upper_green)
results = reader.readtext(binary)
digits = []
for result in results:
text = result[1]
if text.isdigit():
digits.append(int(text))
print(digits)
return digits
if __name__=="__main__":
dir=r"D:\projects\data\leisi\s1"
files=[os.path.join(dir,f) for f in os.listdir(dir)]
reader = easyocr.Reader(['en'])
for p in files:
img=cv2.imread(p)
n=getDigit(img)
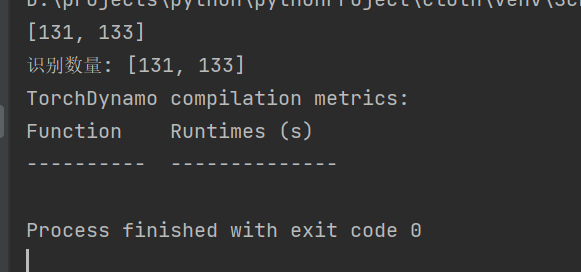
print("识别数量:",n)这样就识别出来了


















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











