






xpath 语法
首先介绍 xpath 的语法:
选取节点:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点 |
| /bookstore | 选取根元素 bookstore。注:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()< 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
逻辑表达式:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 titile 和 price 元素。 |
| //book[@class=“title” and @id=“kw”] | 选取 class 属性值为 title 并且 id 属性值为 kw 的所 有 book 元素。 |
| //title[@class!=“content”] 或者 //title[not(@class=“content”)] | 选取 class 属性值不为 content 得所有 title 元素。 |
轴以及相关案例:

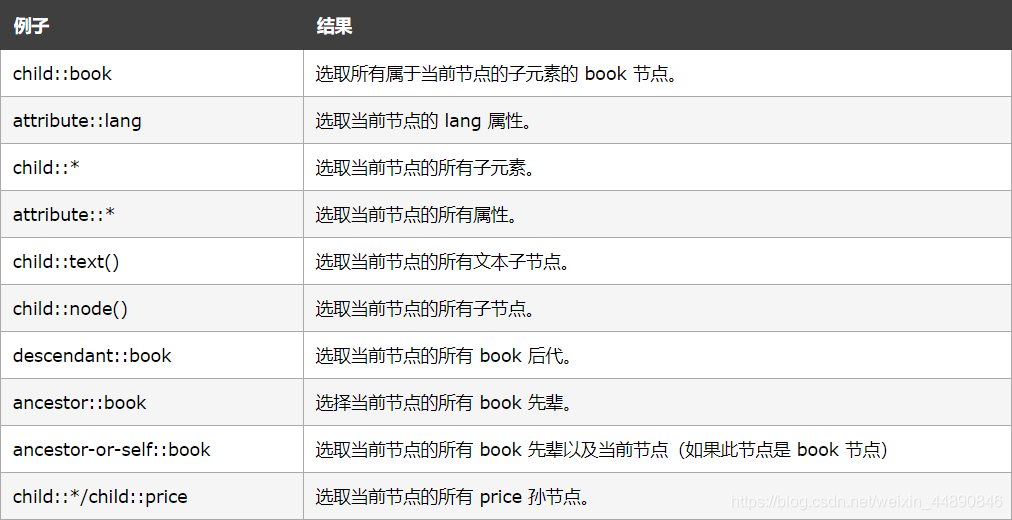
实例
以下列代码为例:
<div>
<div class="csdn-side-toolbar">
<a class="option-box" data-type="app">
<img src="https://g.csdnimg.cn/side-toolbar/1.6/images/qr.png" alt="" srcset="">
<span class="show-txt">手机看</span>
<div class="app-qr-box">
<div class="bg-box">
<div class="qr-item-box">
<img src="https://g.csdnimg.cn/side-toolbar/1.6/images/qr_wechat.png" alt="关注公众号">
<p class="desc">关注公众号</p>
</div>
<div class="qr-item-box">
<img src="https://g.csdnimg.cn/side-toolbar/1.6/images/qr_app.png" alt="下载APP">
<p class="desc">下载APP</p>
</div>
</div>
</div>
</a>
<a class="option-box" data-type="cs">
<img src="https://g.csdnimg.cn/side-toolbar/1.6/images/kefu.png" alt="" srcset="">
<span class="show-txt">客服</span>
</a>
<a class="option-box go-top-hide" data-type="gotop">
<img src="https://g.csdnimg.cn/side-toolbar/1.6/images/fanhuidingbucopy.png" alt="" srcset="">
<span class="show-txt">返回<br>顶部</span>
</a>
</div>
</div>
定位标签
基础的定位方式:
# 定位 class 属性值为 app-qr-box 的节点
//div[@class="app-qr-box"]
# 获取 span 节点的文本内容
//span[@class="show-txt"]//text()
# 获取 <div class="bg-box"> 子元素中的第一个 div 节点
//div[@class="bg-box"]/div[1]
获取指定区域的html代码:
result = html.xpath("//a[@data-type='gotop']")
content = etree.tostring(result[0])
轴的使用
语法:轴名称::节点名[谓语]
选取目标 a 节点的所有属性值,返回一个列表。
//a[@class='option-box go-top-hide']/attribute::*
# 输出:['option-box go-top-hide', 'gotop']
选取目标 a 节点及其所有子孙节点的所有属性值,返回一个列表。
//a[@class='option-box go-top-hide']//attribute::*
# 输出:['option-box go-top-hide', 'gotop', 'https://g.csdnimg.cn/side-toolbar/1.6/images/fanhuidingbucopy.png', '', '', 'show-txt']
模糊匹配
选取文本内容为“客服”的所有节点:
//*[contains(text(), "客服")]
选取 class 属性值为“option-box”的所有节点:
//*[contains(@class,"option-box")]
匹配 class 属性值以“option”开头的所有节点:
//*[starts-with(@class,"option")]
匹配 class 属性值以“txt”结尾的所有节点:
//*[ends-with(@class,"txt")]
python 中利用正则表达式匹配 class 属性值全部为字母的节点:
ns = {"re": "http://exslt.org/regular-expressions"}
content = html.xpath("//*[matchs(@class,'客.+')]",namespaces=ns)














 2322
2322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









