







题目: The Power of Scale for Parameter-Effificient Prompt Tuning
来源: EMNLP 2021
模型名称: Soft-Prompt
论文链接: https://aclanthology.org/2021.emnlp-main.243/
项目链接: https://github.com/google-research/prompt-tuning
核心:针对不同的任务设计不同的soft
pormpt仅添加到embedding层中,仅训练这些参数。其余的参数都保持冻结,类似Prefix-tuning的想法,但是无论是token的长度以及所添加的位置都有一些差别
0.摘要
与 GPT-3 使用的离散文本提示不同,软提示是通过反向传播学习的,并且可以调整以合并来自任意数量的标记示例的信号。该方法是在T5上面进行实验的,随着模型大小的增加,该方法与全量微调的差距越来越小。作者的方法可以看作是 Li 和 Liang (2021) 最近提出的“prefix-tuning”的简化,我们提供了与这种方法和其他类似方法的比较。最后,我们表明,使用软提示调节冻结模型可为域转移带来稳健性优势,并实现高效的“提示集成”。
1.引言
prompt design是在GPT-3上实现的,在模型规模不断增加的前提下,通过使用这种“冻结”预训练模型是非常有效的。
- Prompt的缺点:需要人工设计,并且prompt的有效性受到诸多限制。GPT-3尽管比T5-XXL大了16倍,但是在SuperGLUE的分数上仍落后17.5.
- 自动Prompt:尽管自动设计Prompt的方法比人工设计的要好,但是仍落后于模型的微调。
- Prefix-tuning:冻结模型参数并在调整期间将错误反向传播到编码器堆栈中每个层(包括输入层)之前的前缀激活
作者冻结了整个预训练模型,只允许将每个下游任务的额外 k 个可调标记添加到输入文本中。这种“软提示”经过端到端训练,可以压缩来自完整标记数据集的信号,使我们的方法能够胜过少样本提示,并通过模型调整缩小质量差距。
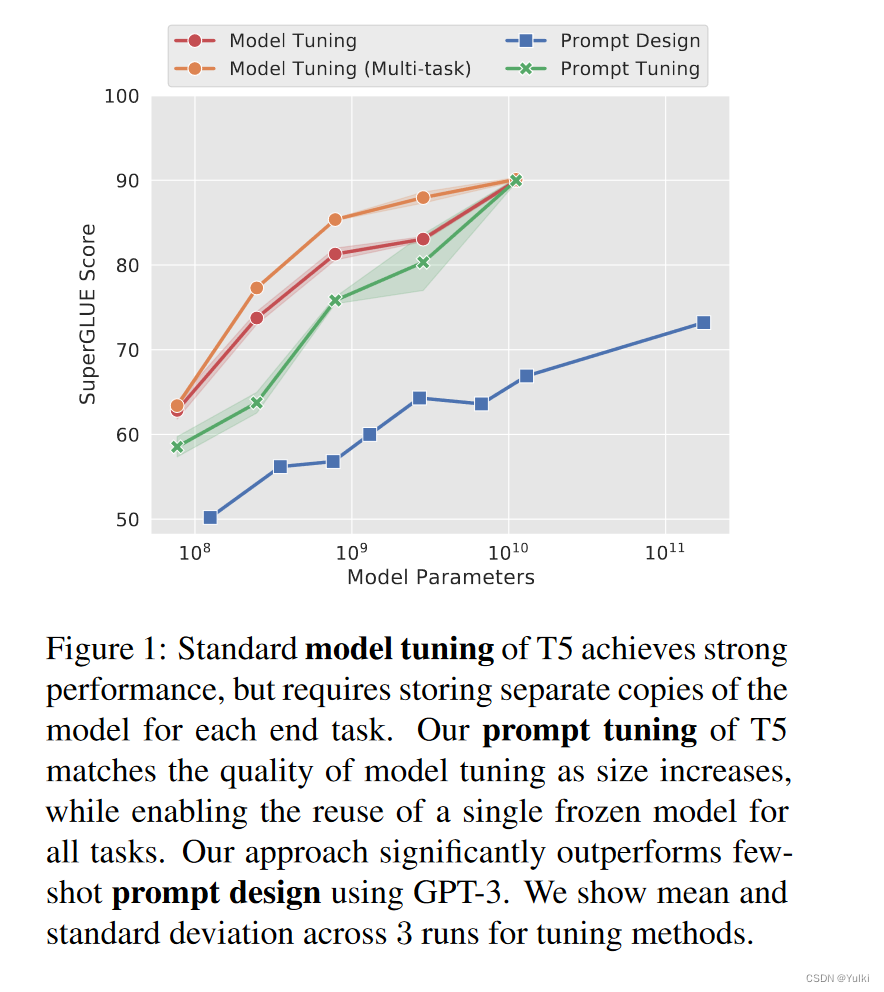
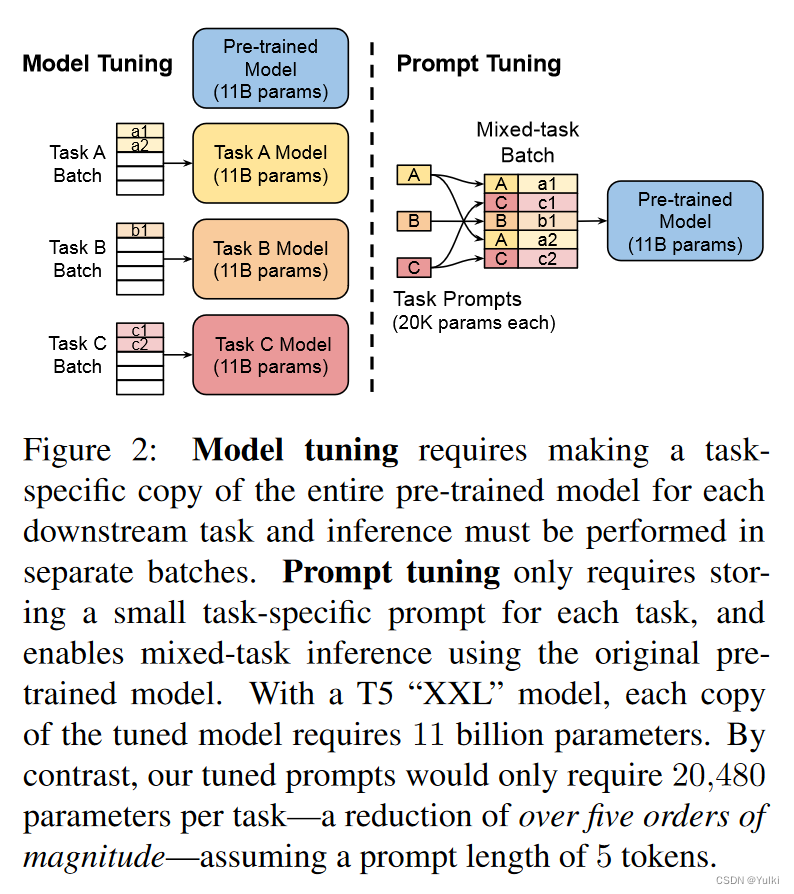
尽管本文是基于Prefix-tuning的,但是他们是第一个单独使用prompt的,并没有在中间层或者不同任务的输出层条件额外的prefix。并且明确地将特定于任务的参数与一般语言理解所需的“通才”参数分开具有一系列额外的好处。
本文主要贡献:
- 提出prompt-tuning并且展示它的优势
- 做了许多消融实验,随着模型规模的提升,prompt tuning的质量和鲁棒性都提高
- 提出 🧐prompt ensembling并且展示他的有效性
2.方法
将T5中,将文本分类任务当作: P r ( y ∣ X ) Pr(y|X) Pr(y∣X)→ P r θ ( Y ∣ X ) Pr_θ(Y |X) Prθ(Y∣X), y y y代表类别, Y Y Y代表class label的Token。把所有的任务都看成文本生成。
P r θ ( Y ∣ [ P ; X ] ) Pr_θ(Y |[P ; X]) Prθ(Y∣[P;X]),P是prompt token,看成条件概率生成Y, θ θ θ是原始模型,需要对其进行固定的
在GPT3中,P = {p1, p2, . . . , pn}, 是模型嵌入表的一部分,由冻结的 θ 参数化
Prompt tuning去掉了提示P被θ参数化的限制,而是有自己的专用参数 θ P θ_P θP ,可以进行更新。
P r ( y ∣ X ) Pr(y|X) Pr(y∣X) → P r θ ( Y ∣ X ) Pr_θ(Y |X) Prθ(Y∣X) → P r θ ( Y ∣ [ P ; X ] ) Pr_θ(Y |[P ; X]) Prθ(Y∣[P;X]) → P r θ ; θ P ( Y ∣ [ P ; X ] ) P_{rθ;θ_P} (Y |[P ; X]) Prθ;θP(Y∣[P;X])
[ P e ; X e ] ∈ R ( p + n ) × e [Pe; Xe] ∈ R^{(p+n)×e} [Pe;Xe]∈R(p+n)×e
训练目标就是对Y进行极大似然,只训练 P e P_e Pe
2.1 初始化
从概念上讲,我们的软提示以与输入之前的文本相同的方式调制冻结网络的行为,因此类似词的表示可能会作为一个很好的初始化点。对于分类任务,将Prompt初始化为它对应的类别。提示越短,必须调整的新参数就越少,因此我们的目标是找到仍然表现良好的最小长度。
2.2 T5
原始文本:Thank you for inviting me to your party last week
预训练模型的输入:Thank you 〈X〉 me to your party 〈Y〉 week
目标输出:〈X〉 for inviting 〈Y〉 last 〈Z〉
尽管这种结构比传统结构更加有效,但作者认为不是仅仅通过使用prompt tuning就能控制冻结的模型的。T5使用的Span Corruption策略使得模型在训练和输出过程中始终存在哨兵标记,模型从来没有输出过真实完整的文本,这种模式可以通过Fine-tune很容易纠正过来,但是仅通过prompt可能难以消除哨兵的影响。
- Span Corruption:使用现成的预训练 T5 作为我们的冻结模型,并测试其为下游任务输出预期文本的能力
- Span Corruption + Sentinel【哨兵】:我们使用相同的模型,但在所有下游目标前加上一个哨兵,以便更接近预训练中看到的目标
- LM Adaptation:对于按原始方法训练好的T5模型,额外使用LM(语言模型)优化目标进行少量步骤的Finetune,使模型从输出带哨兵的文本转换为输出真实文本,期望T5和 GPT一样生成真实的文本输出。(这是本实验的默认设置)。至多100K step
【其实可以看到,无论对哪个变量就行消融,只要模型的规模上去了,效果都差不多】
2.3 消融实验
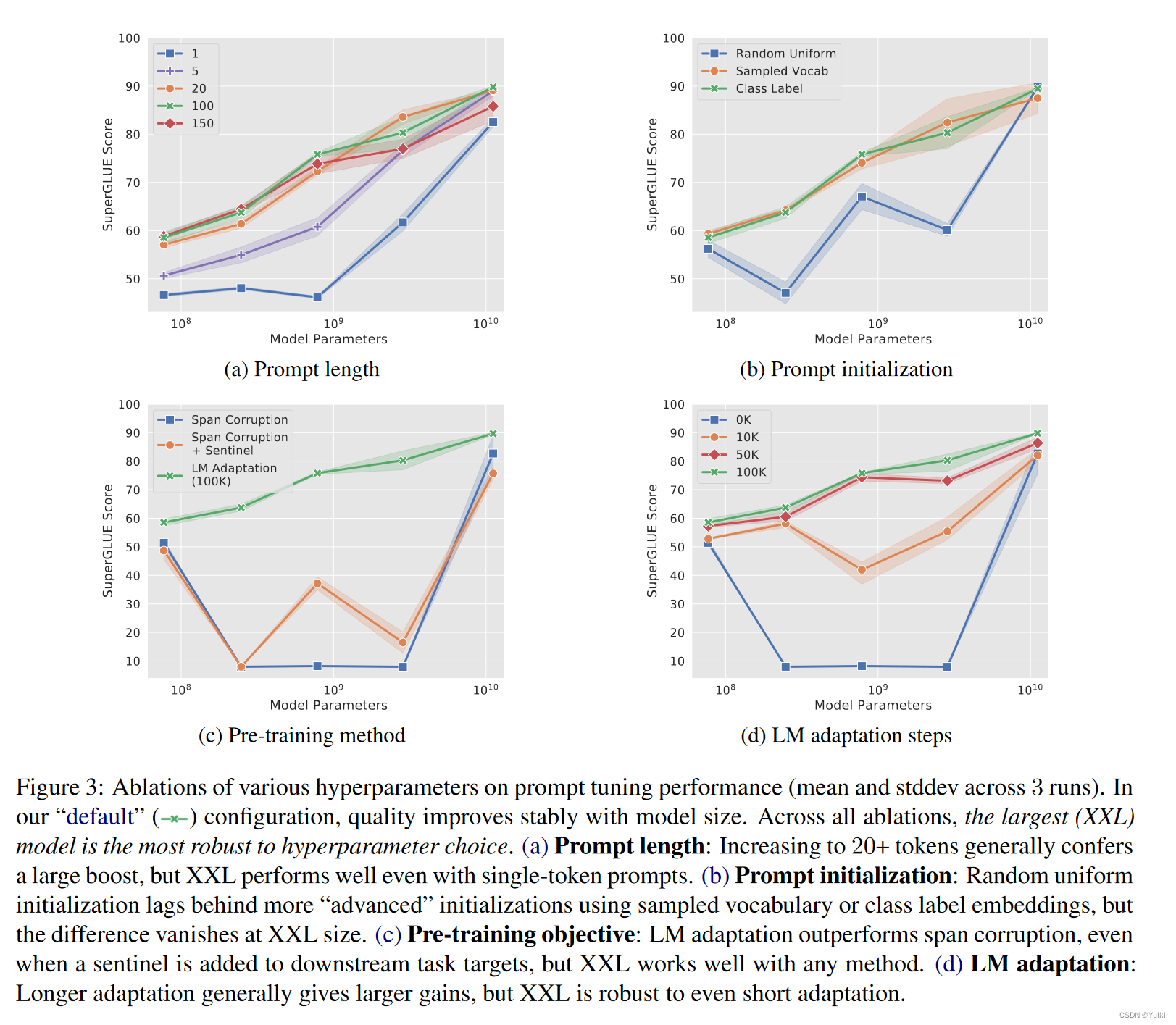
Prompt 长度:模型越大,实现目标行为所需的调节信号就越少。在所有模型中,增加超过 20 个token只会产生边际收益。【超过100个token会使得模型性能下降】
Prompt初始化:
- random initialization:随机初始化, [ − 0.5 , 0.5 ] [−0.5, 0.5] [−0.5,0.5]
- initializing from sampled vocabulary:从T5的SentencePiece vocabulary中抽出最常见的500个词汇
- class label初始化:讲类别对应的embedding座位prompt初始化。如果一个类有多个词,取词嵌入的平均表示作为一个prompt。假如标签数目不足,则从Sampled Vocab方案中继续采样补足。
作者发现基于类的初始化表现最好。在较小的模型尺寸下,不同初始化之间存在较大差距,但一旦将模型缩放到 XXL 尺寸,这些差异就会消失。
**预训练目标:**T5 的默认“span corruption”目标不太适合训练冻结模型,以便稍后通过提示进行调节。经过预训练以读写哨兵标记的模型很难直接应用于没有哨兵的读写文本任务
这表明从 span corruption 到语言建模目标的“过渡”不是一个微不足道的变化,并且进行有效的转换需要训练资源的投资(原始 T5 预训练步骤的 10%)
在非最佳“跨度损坏”设置中,我们观察到模型大小的不稳定性,小型模型优于较大的基础模型、大型模型和 XL 模型。在检查中,我们发现对于许多任务,这些中型模型从未学会输出合法的类标签,因此得分为 0%。这些结果表明,使用以“跨度损坏”目标预训练的模型可能不可靠,5 个模型中只有 2 个运行良好,而 LM 适应版本在所有模型大小上都能可靠地运行。
3. 结果
使用100个token的长度作为soft prompt,与prefix的10 token相比,prompt只是在输入层使用,在别的层不添加,因而参数量更少。
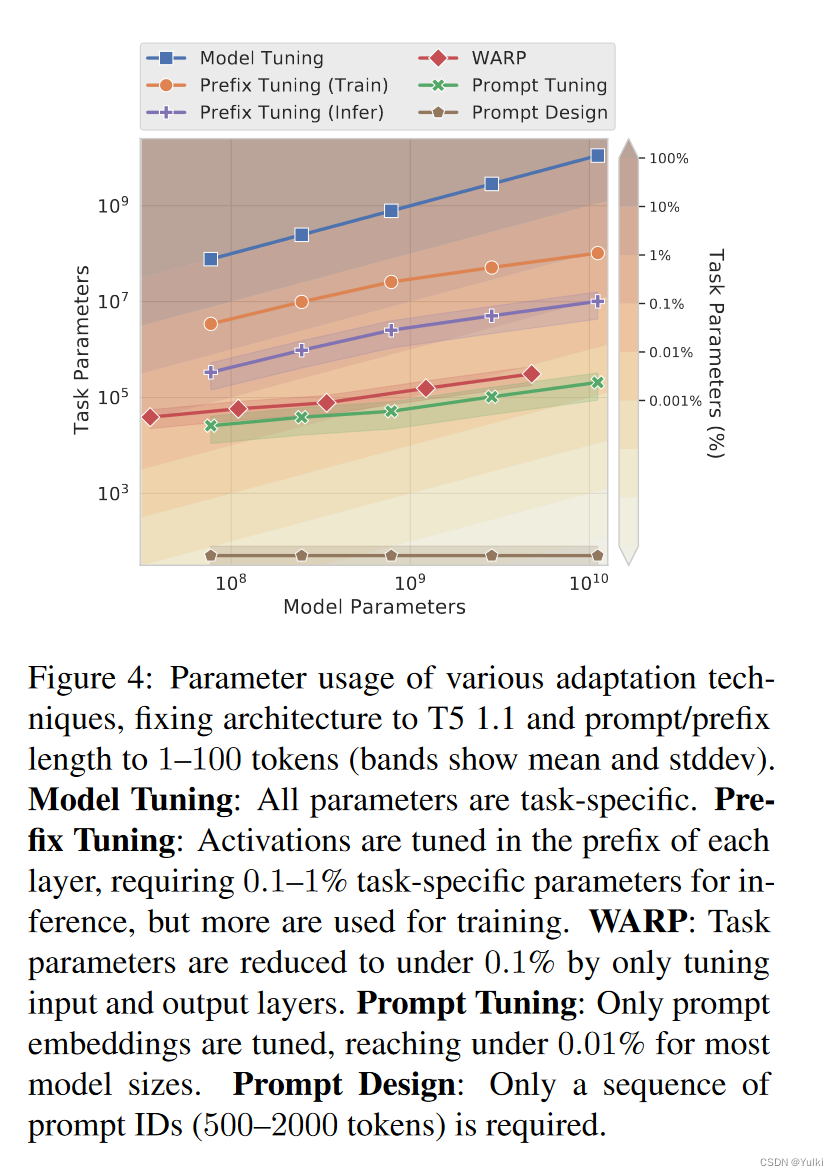
prompt tuning只需要在encoder加入prompt,而prefix tuning需要在encoder和decoder都添加
只在输入层加入可以防止模型的过拟合,因此prompt tuning可以迁移到别的领域上面
连续空间的prompt比离散空间的prompt难以解释。
4. 结论
在SupreGLUE上,Prompt tuning的任务性能可与传统模型调整相媲美,随着模型尺寸的增加,差距会逐渐消失。在Zeor-shot领域迁移,有效提升泛化性。在few-shot上面可以看作,冻结模型的参数,限制为轻量级的参数有效避免过拟合。
核心:将下游任务的参数和预训练任务的参数分开















 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









