







题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
来源: ACL 2021
模型名称: Prefix-Tuning
论文链接: https://aclanthology.org/2021.acl-long.353/
项目链接: https://github.com/XiangLi1999/PrefixTuning
感觉与prompt的想法很相近,那么问题来了,为什么不一开始就用prompt呢?应该看一下代码,我感觉并没有说prefix是在哪里添加
0.摘要
微调会修改所有语言模型参数,因此需要为每个任务存储完整副本。作者提出了前缀调整,这是自然语言生成任务微调的一种轻量级替代方案,它保持语言模型参数不变,而是优化**一系列连续的特定于任务的向量,称之为前缀。**灵感来源于prompt,在两个任务上使用prefix-tuning:在GPT-2上table-totext generation,在BART上面总结
1.引言
问题:大模型进行微调的代价很大,应该怎么办?
现有解决办法:Adapter-tuning、in-context learning
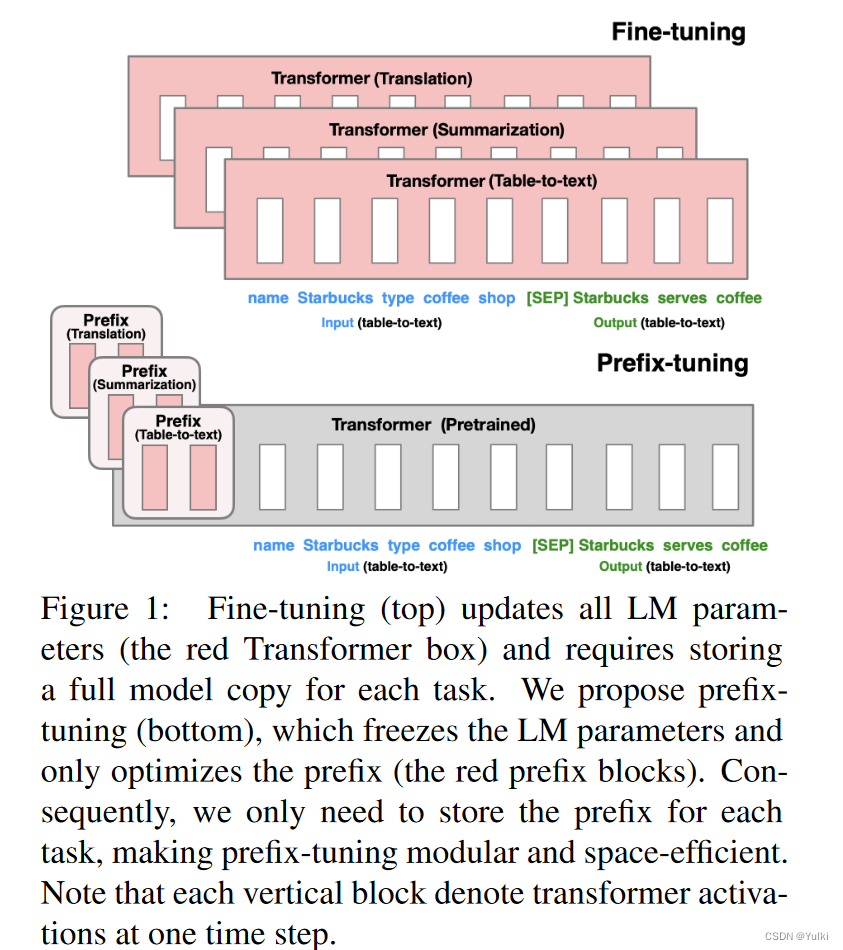
考虑生成数据表的文本描述的任务,如图 1 所示,其中任务输入是线性化表(例如,“名称:星巴克 | 类型:咖啡店”),输出是文本描述(例如,“星巴克供应咖啡。”)。Prefix-tuning将一系列连续的特定于任务的向量添加到输入中,我们称之为前缀。Transformer 可以将前缀视为一系列“虚拟token”,但与prompt不同,前缀完全由不对应于真实令牌的自由参数组成。
针对不同的任务,是需要微调prefix即可。(图中红色的部分是在微调过程中需要进行优化的地方)
与完全微调相比,前缀调整也是模块化的:我们训练一个上游前缀来引导未修改的 LM,因此,单个 LM 可以同时支持许多任务。在任务与用户相对应的个性化背景下,我们将为每个只接受该用户数据训练的用户设置一个单独的前缀,从而避免数据交叉污染。此外,基于前缀的架构使我们甚至可以在一个批次中处理来自多个用户/任务的示例,这是其他轻量级微调方法(如 adaptertuning)无法做到的。
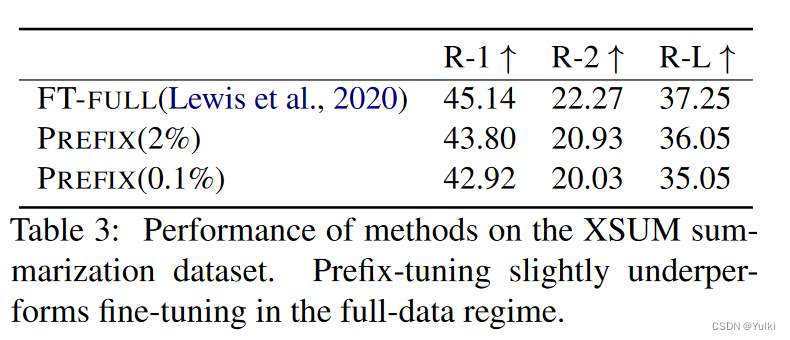
在table-to-text中,与全量微调效果差不多。在summarization中,只退化了一点点性能。但是在low-data设定下,在两个任务上,prefix效果都要比微调要好。prefix对于未见过的数据处理的更好。
2.相关工作
NLG中进行微调:本文只是用了GPT-2和BART,其实可以用在所有的生成任务和预训练模型上面的、
轻量化微调:关键问题是如何扩充 LM 架构并决定调整哪个预训练参数子集。一项研究学习了特定于任务的参数掩码。另一项研究是插入具有可训练参数的新模块。与Adapter相比,减少了30倍的参数。【我的理解,大模型对文本其实已经理解的很好了,只是不知道要做什么任务罢了】
Prompting:AutoPrompt,采用离散的提示词。尔prefix tuning用的是连续的向量进行表示。前缀调整优化适用于该任务所有实例的任务特定前缀。因此,与以前的应用仅限于句子重建的工作不同,前缀调整可以应用于 NLG 任务。
可控生成:目前没有直接的方法来应用这些可控生成技术来对生成的内容实施细粒度控制,如表到文本和摘要等任务所要求的那样。
P-tuning*:(P*指的是 p-tuning,prompt-tuning,prefix-tuning)调整软提示优于以前的工作

3.Prefix-tuning
Prompt表明在适当的上下文条件下可以在不更改其参数的情况下引导 LM。例如,如果我们希望 LM 生成一个词(例如 Obama),我们可以将其常见搭配作为上下文(例如 Barack)添加到前面,LM 将为所需词分配更高的概率。将这种直觉扩展到生成单个单词或句子之外,我们希望找到一个上下文来引导 LM 解决 NLG 任务。
我们可以将指令优化为连续词嵌入,而不是对离散标记进行优化,其效果将向上传播到所有 Transformer 激活层,并向右传播到后续标记。这比受限于真实单词嵌入的离散提示更具表现力。通过优化所有层的激活,而不仅仅是嵌入层,前缀调整在提高表现力方面更进了一步。另一个好处是,prefixtuning 可以直接修改网络更深处的表示,因此避免了跨越网络深度的长计算路径
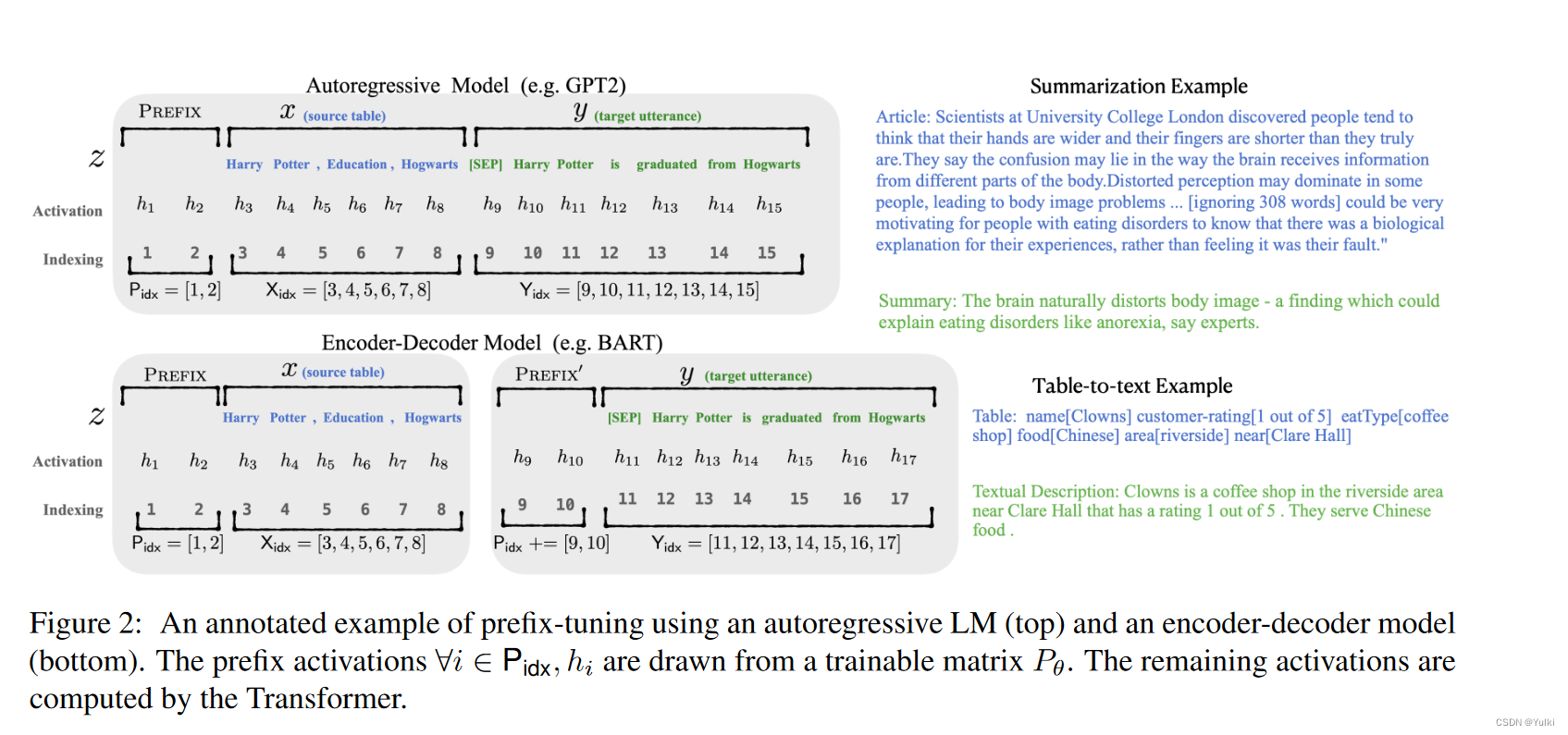
对于自回归模型,加入前缀后的模型输入表示: z = [ P R E F I X ; x ; y ] z=[PREFIX; x; y] z=[PREFIX;x;y]
对于Encoder Decoder模型,加入前缀后的模型输入表示: z = [ P R E F I X ; x ; P R E F I X ; y ] z=[PREFIX; x; PREFIX; y] z=[PREFIX;x;PREFIX;y]
本文构造一个矩阵 P θ ( ∣ P i d x ∣ × d i m ( h i ) ) P_\theta(|P_{idx}| \times dim(h_i)) Pθ(∣Pidx∣×dim(hi))去存储前缀参数,该前缀是自由参数
h i = { P θ [ i , ; ] , if i ∈ P i d x , L M ϕ ( z i , h < i ) , otherwise. h_i=\begin{cases}P_\theta[i,;],&\text{if}i\in\mathsf{P}{\mathrm{idx}},\\ \mathsf{LM}\phi(z_i,h_{<i}),&\text{otherwise.}\end{cases} hi={Pθ[i,;],LMϕ(zi,h<i),ifi∈Pidx,otherwise.
微调的时候参数Φ是固定的,θ是进行训练的
h i h_i hi 不属于 p i d x p_{idx} pidx时, h i h_i hi仍然依赖于 h θ h_\theta hθ,因为前缀激活总是在左侧上下文中,因此会影响右侧的任意激活函数
注意!
直接更新 P θ P_\theta Pθ会导致优化不稳定以及轻微的性能下降。因为对 P θ P_\theta Pθ矩阵进行了重参数化:
P θ [ i , : ] = MLP θ ( P θ ′ [ i , : ] ) P_{\theta}[i, :]=\text{MLP}_{\theta}(P'_{\theta}[i, :]) Pθ[i,:]=MLPθ(Pθ′[i,:])
现在,可训练的参数包括 P θ P_θ Pθ和 M L P θ MLP_θ MLPθ的参数。请注意, P θ P_θ Pθ 和 P ′ θ P′_θ P′θ 具有相同的行数(即前缀长度),但列数不同。 一旦训练完成,这些重新参数化参数可以被丢弃,只需要前缀 P θ P_θ Pθ已保存
4.实验
4.1 table-to-text
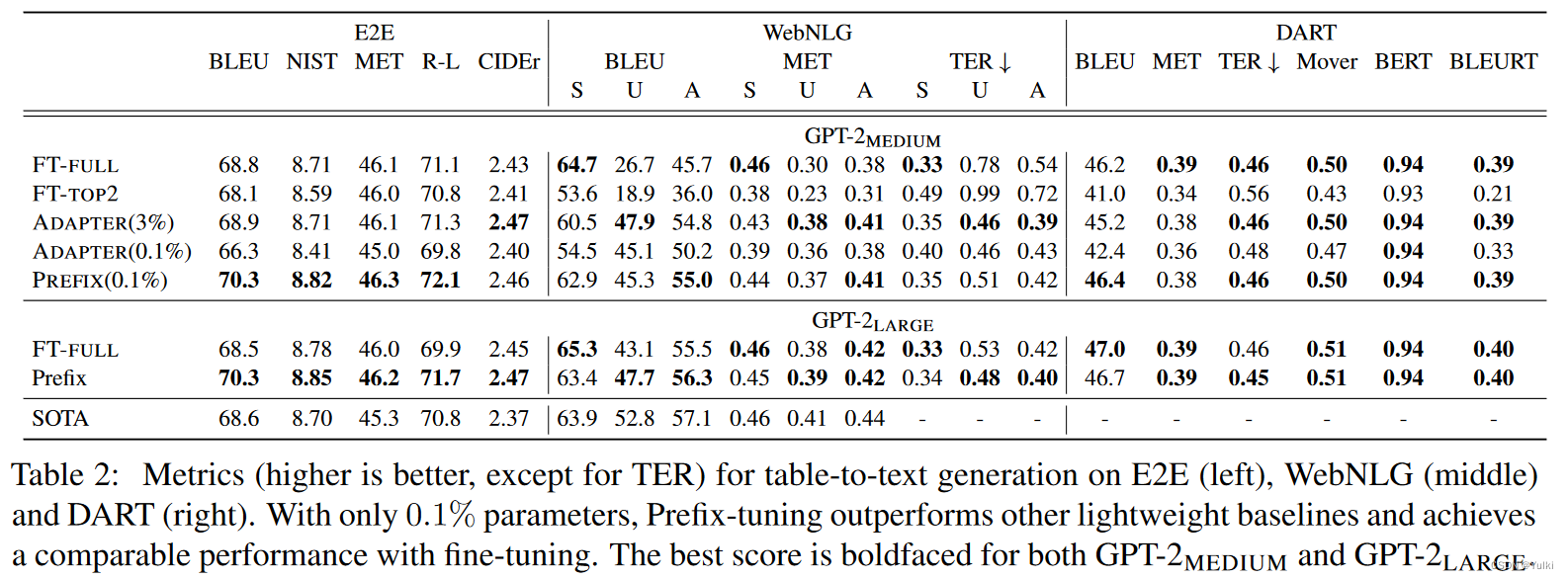
**NIST:**在 BLEU 方法上的一种改进
MET 和 BLEU 不同,MET同时考虑了基于整个语料库上的准确率和召回率,而最终得出测度
TER 是 Translation Edit Rate 的缩写,是一种基于距离的评价方法,用来评定机器翻译结果的译后编辑的工作量 详情
R-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文 C 和参考译文 S 的最长公共子序列
4.2 summarization
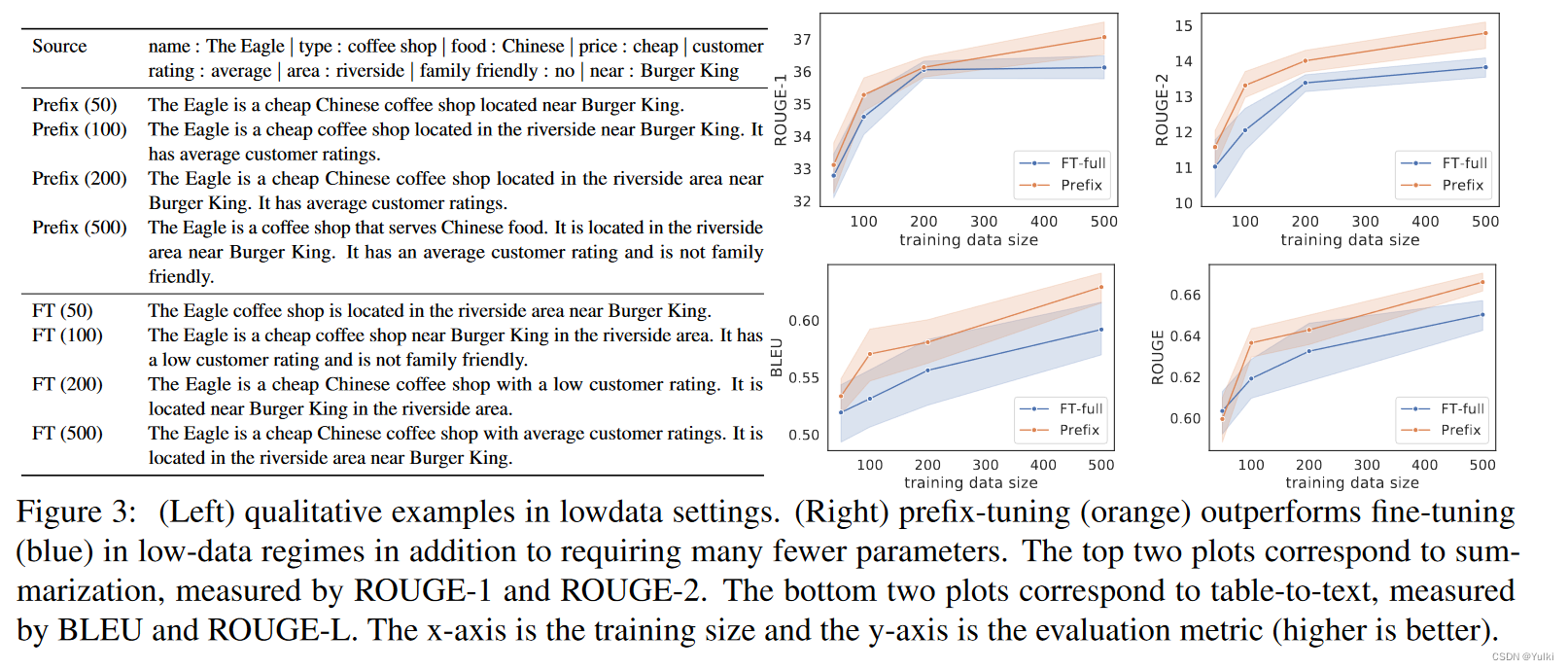
4.3 Low-data Setting
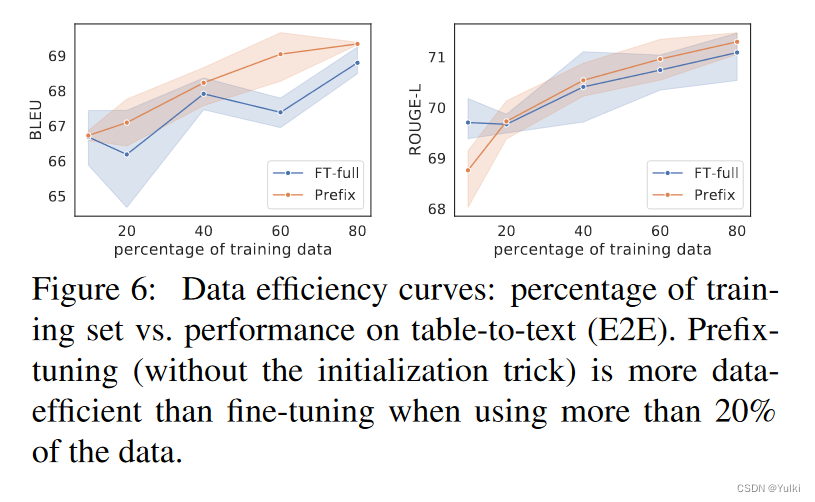
在训练数据很小的情况下,优势更加明显。【他们在做实验的时候,直接控制数据集的规模就好了】
4.4 归纳推理性能
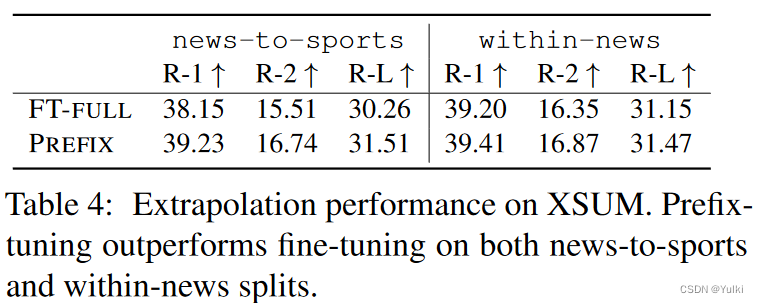
为了构建一个推测设置,作者将现有的数据集进行分割,以便训练和测试覆盖不同的主题。对于table-to-text,WebNLG数据集被标记为表主题。在train和dev中出现了9个类别,表示为SEEN,5个类别只出现在测试时,表示为UNSEEN。因此,我们通过对SEEN类别的训练和对UNSEEN类别的测试来评估extrapolation能力。例如:在news-to-sports中,训练新闻文章,测试体育文章。在within-news,训练{world, UK, business}新闻,并对其余的新闻类别进行测试(e.g., health, tech)
表2(中间)中的“U”列也表示extrapolation的结果
我们还发现,adapter-tuning 也获得了良好的extrapolation性能,这一共同的趋势表明,保留LM参数确实对extrapolation有积极的影响。然而,prefifix-tuning如何改进外推法是一个悬而未决的问题
【结果详见Table2 中间 S:seen,U:unseen,A:all】
5.评估
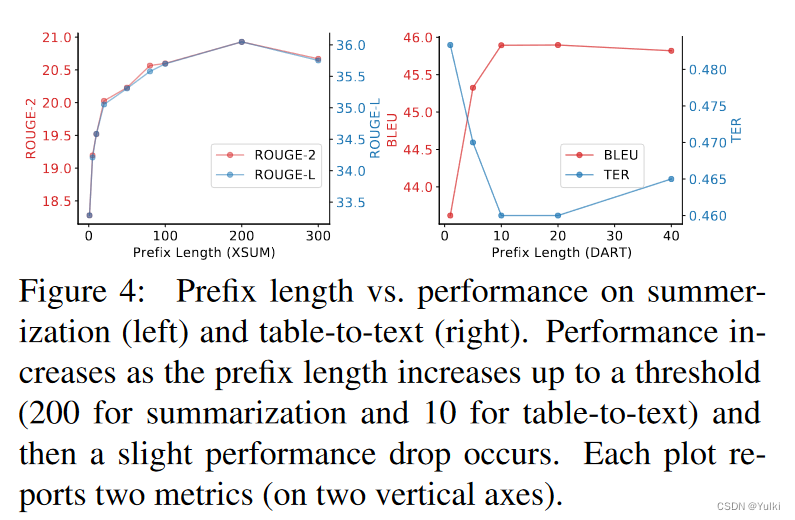
5.1 Prefix Length
prefix的长度越长,说明可以训练的参数就越多,当长度超过一定阈值的时候,性能就会出现下降的情况,这说明模型已经开始出现了过拟合的问题。
5.2 Full vs Embedding-only
discrete prompting < embeddingonly < prefix-tuning.
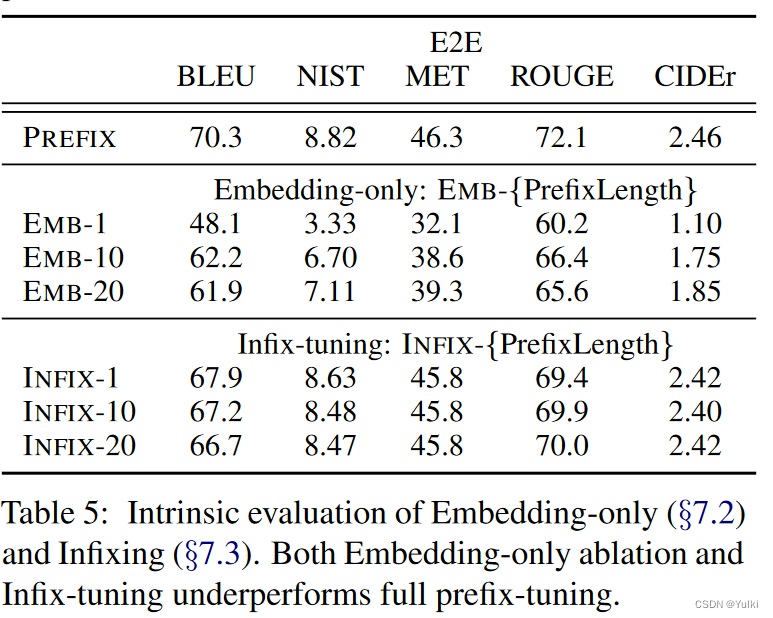
5.3 Prefix-tuning vs Infix-tuning
上述Table 5 中的下半部分就是Infix-tuning
作者认为这是因为前缀调整可以影响 x 和 y 的激活,而中缀调整只能影响 y 的激活。
[PREFIX; x; y] →[x; INFIX; y]
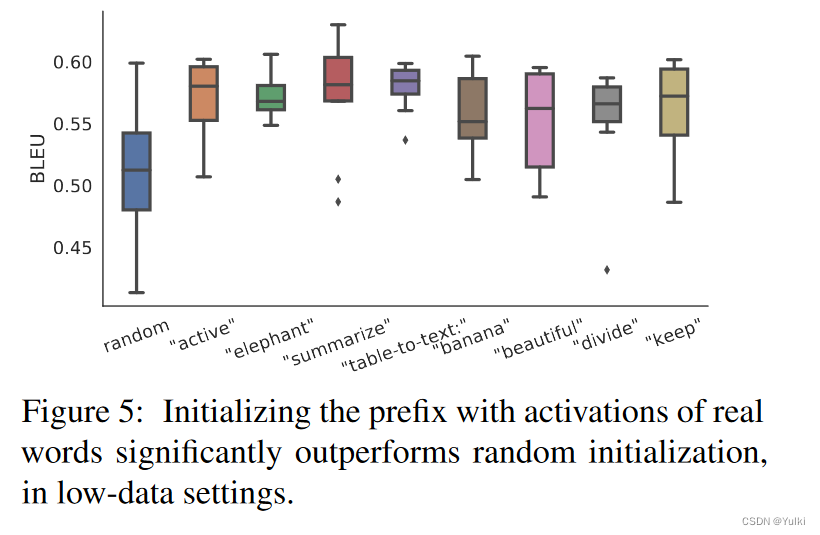
5.4 初始化
在low-data设定下:用任务相关的词初始化效果>随机真实词汇初始化>随机初始化
在全量数据下:哪种初始化都没有影响
由于作者使用 LM 计算的真实单词的激活来初始化前缀,因此这种初始化策略与前缀调整的理念一致,它尽可能地保留了预训练的 LM。
6.讨论
个性化:每个用户都被视为一个独立的任务,每个任务都有独立的prefix
Batching across users:可以进行批量计算,只要把prefix添加到对应层就可以,而adapter做不到这一点
Inductive bias of prefix-tuning:保留 LM 参数可能有助于泛化到训练期间看不到的域。【但具体是如何外推的,并不清楚】prefix并没有破坏LM的结果,Adapter实际上破坏了LM的结果,因此Prefix-tuning比起Adapter能更好的利用LM
Aghajanyan 等人最近的工作。 (2020) 使用内在维度表明存在低维重新参数化,它与全参数化一样有效地进行微调。这解释了为什么仅更新少量参数就可以获得下游任务的良好准确性。作者的工作通过表明也可以通过更新非常小的前缀来获得良好的生成性能来回应这一发现。然而,前缀调整不仅仅是关于可训练参数的大小,更重要的是,要修改参数的哪个子集。因此,探索其他轻量级微调方法以实现更好的精度大小权衡将是有趣的未来工作。















 1439
1439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









