






大家好,我是来自聚美优品刷宝大数据部门的吴攀刚,本文将跟大家分享 PyFlink 在刷宝的应用,包括:背景介绍、架构演进、技术选型以及一个问题的解决思路分享。
刷宝是一款短视频 APP,涵盖短视频、直播视频等内容,为用户提供快乐视频和优质的主播。在来到聚美之前,我主要做离线数仓开发和数据开发,来到刷宝之后,部门也并没有现成的实时框架,需要自行搭建。所以,当实时的需求来到我面前的时候,内心是忐忑的。
下面我将分享下,我与 PyFlink 的缘分。
1.背景介绍
业务场景
刷宝有许多重要的业务场景,其中之一是为用户实时推荐短视频。其中推荐的实时性,决定了用户在视频上的停留时长、观看视频时长、留存等指标,进而影响到广告位的收益,比如广告的单价等。
刷宝从 2019 年开始,业务飞速发展,截止到 2020 年 5 月份,用户行为数据峰值每秒过百万,每天有 200 亿数据。这个业务量,对我们现有的技术架构、数据计算的实时性提出了挑战。
实时化挑战
我们的数据流程整个环节完成需要1小时左右时间,远达不到实时的要求。如何更快速的根据用户浏览习惯实时推荐相关视频会对用户观看视频时长、停留时长、留存等有重大的影响,比如在现有基础上提升10-20%。
我们更期望数据的计算实时化,也就是将原有技术架构中的批量计算(hive)变成实时计算(Flink SQL),架构图如下。
2.架构演进
架构演进
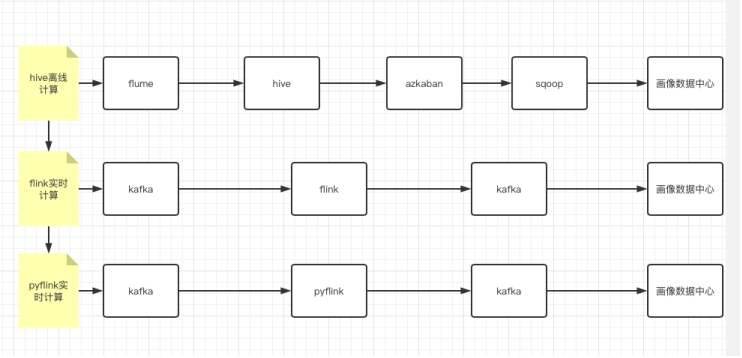
第一层:最开始是离线计算,完成一次计算需要30分钟,还不包括后续的模型处理;
第二层:考虑实时计算后,我们打算采取 Flink 架构来处理,整体主件过程如图;
第三层:考虑到人力和时间等成本,还有技术人员技能匹配度,最终选择第三层;
我们成员更多的是对 Python 和 SQL 熟悉,所以 PyFlink 更加适合我们。我们用 PyFlink 开发了 20 个业务作业,目前每秒过百万,每天有 200 亿,业务平稳运行(PyFlink 1.10)。
3.技术选型
面对实时化的业务和架构升级需求,我们团队本身没有 Spark、Flink 等框架的背景积累,但是一个偶然的机会,我们观看了金竹老师的直播,了解到了 PyFlink 是 Flink 的 Python API 和我团队现有的开发人员语言技能比较吻合。所以就想利用 PyFlink 进行业务的实时化升级。
看完金竹老师的分享,我对 PyFlink 有了一个简单的了解,就和团队同学一起规划了解 PyFlink,进行技术选型。
初识与困难
虽然 PyFlink 和团队的语言技能比较 match,但是其中还是涉及到很多 Flink 的环境、文档、算子等的使用问题,遇到了很多困难:
PyFlink 的知识文档、示例、答疑等都非常少,除了官网和阿里云,基本无其他参考。
PyFlink 官方文档缺少很多细节,比如:给了方法不给参数格式。
PyFlink 的内容不明确,官网上没有明确具体写出哪些 PyFlink 没有,哪些有。没法将 Flink 和 PyFlink 清晰的区分开。
PyFlink 本身等局限性,比如:left/rigint Join 产生 retraction 无法写入 Kafka,要写入需要改写 Flink SQL 让流改为 append 模式,或者修改 kafka-connector 源码支持 retraction。
所以一时感觉利用 PyFlink 的学习时间也比较漫长。大家比较担心短时间内很难满足业务开发。
机遇
在我和团队担心开发进度时候,我也一直关注 Flink 社区的动态,恰巧发现 Flink 社区在进行 “PyFlink 扶持计划”,所以我和团队都眼前一亮,填写了 PyFlink 调查问卷。也和金竹老师进行了几次邮件沟通。最终有幸参与了 PyFlink 社区扶持计划。
4. OOM 报错解决思路分享
其实了解下来 PyFlink 的开发是非常便捷的,在完成了第一个作业的开发之后,大家逐渐熟悉 PyFlink 的使用,3周左右就完成了 20 个业务逻辑的开发,进入了测试阶段。这个快速一方面是团队成员不断的熟悉 PyFlink,一方面是由社区 PyFlink 团队金竹/付典等老师的帮助和支持。这里,不一一为大家分享全部内容,我这里列举一个具体的例子。
■ 背景:
从接触到 Flink 开始,有个别 job,一直有 running beyond physical memory limits 问题。多次调整 tm 内存,修改 tm 和 slos 的比例,都没用,最终还是会挂。最后妥协的方案是,增加自动重启次数,定期重启任务
■ 现象:
Flink job 通常会稳定运行5-6天,然后就报出这个错误。一直持续和反复。
■ 详细信息:
Closing TaskExecutor connection container_e36_1586139242205_122975_01_000011 because: Container [pid=45659,containerID=container_e36_1586139242205_122975_01_000011] is running beyond physical memory limits. Current usage: 4.0 GB of 4 GB physical memory used; 5.8 GB of 32 GB virtual memory used. Killing container.
Dump of the process-tree for container_e36_1586139242205_122975_01_000011 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 45659 45657 45659 45659 (bash) 0 0 115814400 297 /bin/bash -c /usr/local/jdk//bin/java -Xms2764m -Xmx2764m -XX:MaxDirectMemorySize=1332m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/test.bin -Dlog.file=/data/emr/yarn/logs/application_1586139242205_122975/container_e36_1586139242205_122975_01_000011/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir . 1> /data/emr/yarn/logs/application_1586139242205_122975/container_e36_1586139242205_122975_01_000011/taskmanager.out 2> /data/emr/yarn/logs/application_1586139242205_122975/container_e36_1586139242205_122975_01_000011/taskmanager.err
|- 45705 45659 45659 45659 (java) 13117928 609539 6161567744 1048471 /usr/local/jdk//bin/java -Xms2764m -Xmx2764m -XX:MaxDirectMemorySize=1332m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/test.bin -Dlog.file=/data/emr/yarn/logs/application_1586139242205_122975/container_e36_1586139242205_122975_01_000011/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir .
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
我们的解决思路:
1. 从内容上看是 oom 问题,所以一开始调整了 tm 大小,直接到最大内存,2调整 tm 和 slot 的比例,尽量做到 1v1.
2. dump heap 的内存,分析占用情况。
3. 调整 backend state 的类型
结果:以上手段都失败了,在持续一段时间后,依然一定报错。
PyFlink 团队处理思路:
1.分析当前作业的 state 情况,作业情况,作业环境参数情况。通过 flink-conf 可以看 backend state 情况,通过 flinkdashboard 可以知道作业图和环境参数。
2. 由于 1.10 中,rocksdb statebackend 占用的内存默认为非 managed memory,通过在 PyFlink 作业中增加如下代码,可以将其设置为 managed memory:env.get_state_backend()._j_rocks_db_state_backend.getMemoryConfiguration().setUseManagedMemory(True)
3. 为了分析 OOM 是否是由于 rocksdb statebackend 占用的内存持续增长导致的,开启了关于 rocksdb 的监控,因为我们使用的是 rocksdb,这里需要在 flink-conf 中增加如下配置:
state.backend.rocksdb.metrics.block-cache-capacity: true
state.backend.rocksdb.metrics.block-cache-usage: true
state.backend.rocksdb.metrics.num-running-compactions: true
state.backend.rocksdb.metrics.num-running-flushes: true
state.backend.rocksdb.metrics.size-all-mem-tables: true
然后通过自建的 metrics 系统来收集展示和分析,我们使用的 grafana。
4. 通过前面的步骤,观察到 rocksdb 的内存基本是稳定的,内存占用符合预期,怀疑是“rocksdb 超用了一点点,或者是 jvm overhead 不够大”导致的。这两种问题,都可以通过调整 jvm overhead 的相关参数来解决。于是在 flink-conf 中添加了配置:
taskmanager.memory.jvm-overhead.min: 1024m
taskmanager.memory.jvm-overhead.max: 2048m
用大佬的原话:rocksdb 超用了一点点,或者是 jvm overhead 不够大,这两种情况调大 jvm overhead 应该都能解决。
5. 调整 flink.size 的大小,让 flink 自动计算出 process.size,这部分在 flink-conf:
taskmanager.memory.flink.size: 1024m
完成所有调整后,经历了14天的等待,job 运行正常,这里充分说明了问题被解决了。同时开始观察 rocksdb 的 metrics 情况,发现 native 内存会超用一些,但是 rocksdb 整体保持稳定的。目前能判断出某个地方用到的 native 内存比 flink 预留的多,大概率是用户代码或者第三方依赖,所以加大下 jvm-overhead 大数值,能解决问题。
6. 最终需要修改的参数有:
1) 在 pyflink 作业中增加如下代码:
env.get_state_backend()._j_rocks_db_state_backend.getMemoryConfiguration().setUseManagedMemory(True)
2) flink-conf 修改或增加:
taskmanager.memory.jvm-overhead.min: 1024m
taskmanager.memory.jvm-overhead.max: 2048m
taskmanager.memory.process.size: 6144m
其实针对这个业务升级,老板为了不影响最终的业务上线,起初我们准备了2套方案同时进行:
基于某个云平台进行平台搭建和开发;
基于开源 PyFlink 进行代码开发;
两个方案同时进行,最终我们团队基于 PyFlink 开发快速的完成了业务开发和测试。最终达到了我前面所说的每秒百万/每天200亿的稳定业务支撑。
重点,重点,重点,参与这个业务升级的开发只有2个人。
5.总结和展望
通过 PyFlink 的学习,刷宝大数据团队,在短时间能有了实时数据开发的能力。目前稳定运行了 20+PyFlink 任务,我们对接了多个需求部门,如推荐部门、运营、广告等;在多种场景下,模型画像计算、AB 测试系统、广告推荐、用户召回系统等,使用了 PyFlink。为我们的业务提供了坚实稳定的实时数据。
此外,我们将搭建 Flink on Zeppelin 这样的实时计算平台,扩大 Flink 开发用户群体,进一步简化 Flink 开发成本。Flink 1.11 版本也准备上线,Python UDF 功能会有进一步的优化,Pandas 模块也会被引入。假如读者和我们一样,期望能快速拥有实时的能力,以 Python 语言为主,并且还有数据开发/数仓的能力,PyFlink 将是不二之选。
如果您也对 PyFlink 社区扶持计划感兴趣,可以填写下方问卷,与我们一起共建 PyFlink 生态。

了解详情:PyFlink 社区扶持计划正式上线
参与方式:点击「阅读原文」填写问卷即有机会加入哦
关注 Flink 中文社区,获取更多技术干货

你在看」吗?

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









