










2023 年 2 月 8 日,我们组织了首场 Flink Batch 社区开发者会议。虽然是第一次举办社区会议,有诸多准备不周的地方,但会议当天仍然非常火热,参与的听众有 100 多人,可以比拟一场 Meetup,让我们感受到了用户对 Flink Batch 的期待和关注。完整的会议视频和会议资料可以点击「阅读原文」查看。之后我们也会定期组织社区会议,下一场会议将于 2 月 22 日举办(见文末),欢迎大家参与和提交议题。
Flink Batch 社区开发者会议旨在推广 Flink Batch 技术,解决用户遇到的问题和需求,建立社区用户和开发者的定期交流平台,并帮助用户和开发者了解 Flink Batch 和流批一体的发展方向和开发动态,分享生产落地经验,并协调开发贡献工作。
社区会议回顾总结
本次开发者会议邀请到了 Apache Flink 多位核心 PMC/Committer,以及来自快手、Shopee、字节跳动、蚂蚁金服等一线技术专家们,与开发者们分享 Flink Batch 最新的进展和落地的实践经验。
Flink 1.17 Batch 最新进展介绍
来自阿里巴巴的 Apache Flink PMC member 贺小令老师,分享了即将发布的 Flink 1.17 版本 Batch 相关的最新功能进展。主要包括了:
- Adaptive Batch Scheduler:改进了分区消费算法,解决了分区大小不均匀导致下游处理数据不均匀。并成为 Batch 模式下默认的 Scheduler。
- Speculative Execution:针对 Sink 支持了 Speculative Execution,并根据 Task 处理的数据量及执行时间改进了慢任务检测算法,排除数据倾斜的影响。
- Hybrid Shuffle:优化了 Broadcast 性能,并能与 Adaptive Batch Scheduler 和 Speculative Execution 一起工作。
- 新 Join Reorder 算法:引入 DPSize 算法生成稠密树。根据 Query 中 Join 个数,自动选择稠密树算法还是左深树算法。
- Dynamic Partition Pruning:更多的场景能使用 DPP 优化。
- Adaptive Local Hash Aggregate:运行时动态根据 Local Agg 的聚合度,决定是否继续做 Local Hash Agg 还是改做简单的Projection。
- Hive Sink:在批模式下,支持小文件合并,对齐 Hive 合并行为。
- Hive SQL:Hive 语法模式下,原生支持 Hive 常用的聚合函数,TPC-DS 性能提升一倍。
- SQL Client/Gateway:SQL Client 能直连到远程 SQL Gateway,方便用户做交互式查询分析。
- UPDATE/DELETE 语法:支持了标准的数据修正语法 UPDATE 和 DELETE,以及对应的 Connector API,方便数据湖的对接。
我们也针对当前的 Flink 1.17 版本与 Flink 1.16 做了 TPC-DS 的性能对比,在 10TB 级别的分区表场景,1.17 性能比 1.16 提升了 25%。在正式发版之后,我们也会分享更详细的测试细节和性能对比数据。
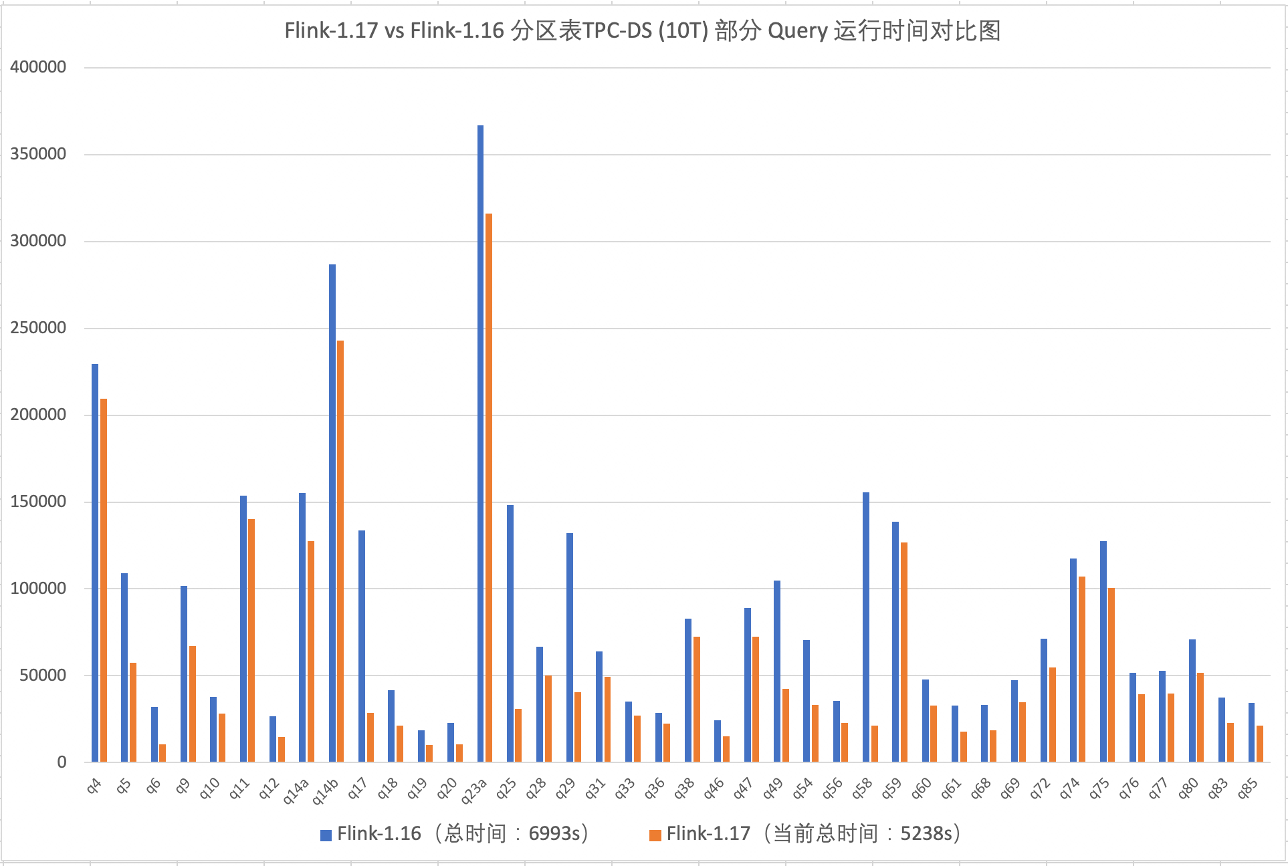
Flink 1.17 版本目前正在发版测试阶段,预计 3 月份发布,欢迎感兴趣的用户试用和反馈。
快手的 Flink Batch 实践经验
来自快手的技术专家、Apache Flink & Apache Calcite Committer 张静老师,分享了快手内部 Flink Batch 的实践经验。在快手内部,目前 Flink Batch 上的作业已经有 3000 多个了,主要有几个场景:
第一个是数据同步场景。以前老的架构,离线同步基于 MR 和 DataX,实时是基于 MR 和自研框架。这个架构的缺点是计算能力弱,扩展性不强。所以数据同步团队基于 Flink 来打造新的版本,希望用 Flink 计算能力和可扩展性来增强数据同步这个产品。
第二个是机器学习场景。机器学习一直是快手内部 Flink Streaming 的重点业务方,他们用 Flink 做实时特征计算和实时样本拼接。他们希望能够用 Flink Batch 复用一套业务逻辑,来满足回溯的需求,做数据修正和冷启动生成历史数据。而且用一个引擎也可以避免结果不一致的问题。
第三个是数据湖场景,之前大部分 Hudi 作业是用 Spark 来做,今年春节活动的时候,已经有部分的 Hudi 作业切到了 Flink 上,包括流和批都有涉及。
最后一个是 Hive/Spark 的任务迁移到 Flink。其实这个工作主要用来推演哪些场景比较适合用 Flink Batch,以及验证 Flink Batch 的稳定性。对于迁移的用户来说,稳定性是基本条件,性能的话需要持平或者差距不大。目前验证了在简单的 ETL 场景下,Flink Batch 的稳定性、易用性、性能、Hive语法兼容方面都是达到生产可用的水平的。关于具体做了哪些工作,感兴趣的可以参考 Flink Forward Asia 2022 上的分享《流批一体架构在快手的实践和思考》。
之后,张静老师还分享了一些在生产上线过程中遇到的问题,以及解决思路和优化方案。感兴趣的可以观看完整的会议视频了解更多。
蚂蚁金服的流批一体落地实践
来自蚂蚁金服的技术专家闵文俊老师,分享了流批一体在蚂蚁金服的落地实践。蚂蚁是从 2022 年开始引入社区 1.15 版本,在其上构建蚂蚁的流批处理引擎,去年基本上落地完成。在最近的 2023 年五福业务中已经覆盖了部分场景。今年会开始对之前的 Blink(流批)引擎升级以及承接一些新的批/流批业务场景、大促场景,并通过流批一体的能力来对数据开发提效。
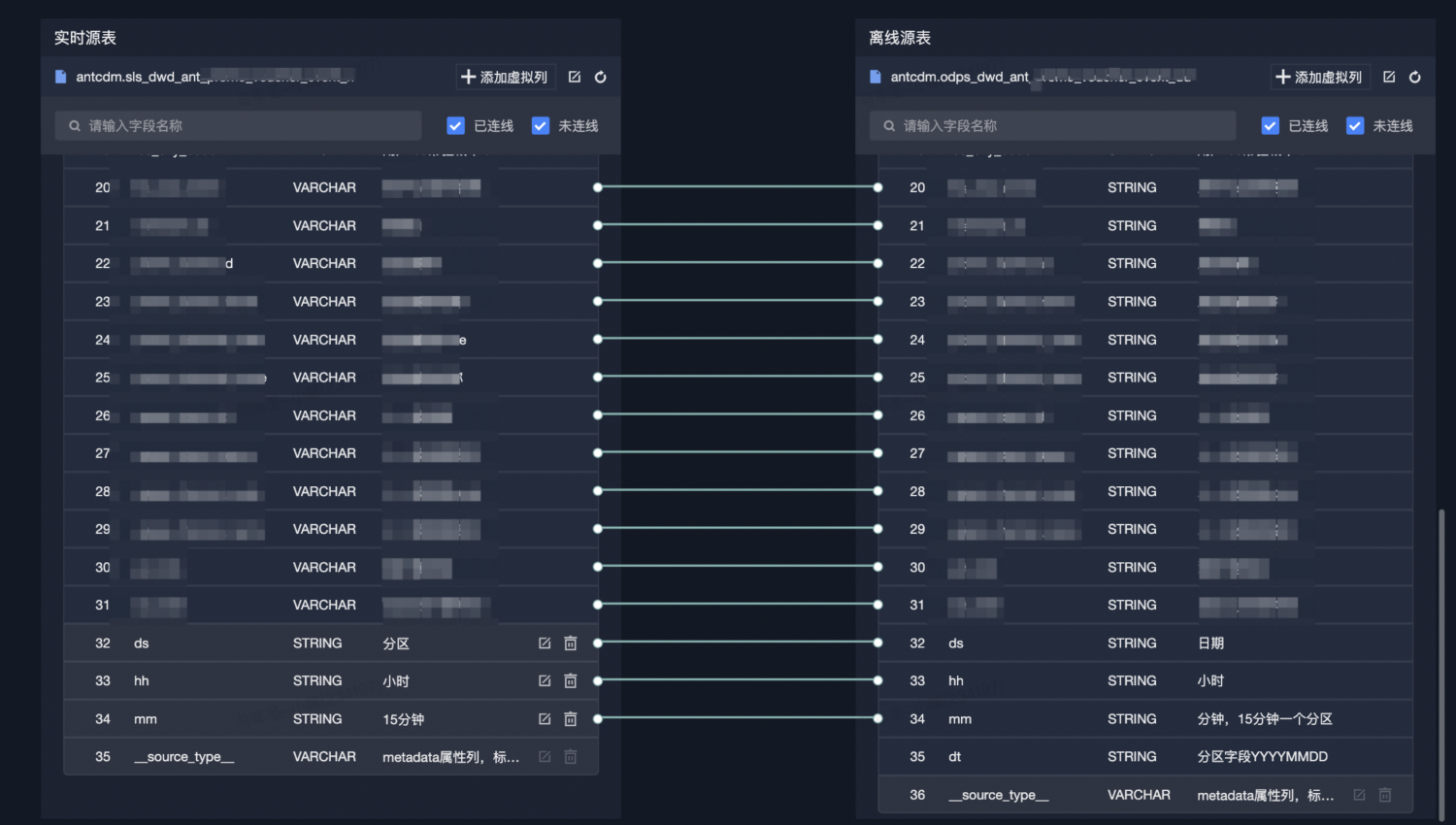
Mix 表模型
流批一体的开发形态
从用户入口上,用户只需要开发主体的 DML 逻辑,面向流表(Schema)开发。实时表和离线表对齐过程,不要求两张表的字段完全对应,会在生成的流和批任务的 SQL 最开始处,根据用户所指定的字段映射关系,插入一段视图来实现字段名不同的问题。流批源表会插入 "__source_type__" 字段并分别注入成 'bounded' 和 'unbounded' ,允许用户在代码中可以通过条件判断实现一些流批的定制逻辑、字段填充、分支逻辑等。
蚂蚁的流批一体引擎也使用到了社区的一些新功能,比如 Adaptive Batch Scheduler + Source 算子的并发推断基本实现批任务并发和资源无需配置。另外还使用了社区的 Flink Remote Shuffle Service,并在 k8s 集群上基于 stateful set + pvc 模式部署,更加云原生一些。最后还用了 HistoryServer 来查看历史批作业的执行情况。蚂蚁内部也做了一些功能优化项,比如子图复用优化、常量折叠优化、union-exchange transpose 优化、流批一体中的维表关联等。
最后,闵文俊老师还分享了一些在生产上线过程中遇到的问题和今天的工作方向。感兴趣的可以观看完整的会议视频了解更多。
Flink Batch 在 Shopee 的应用和实践
来自 Shopee 的技术专家李明昆老师,分享了 Shopee 内部 Flink Batch 的实践经验。Shopee 主要是从去年开始使用 Flink Batch 的,使用的场景主要有几个。一个是数据集成和 ETL 平台。另一个是特征生成平台,特征生成是 Flink Batch 的主要使用方,主要场景是将 Hive 数据经过离线处理后写入 HBase,之前是使用的 Spark,现在迁移到 Flink 了。还有就是数仓领域,我们主推的是 Flink + Hudi,去做 Hudi 的离线 compaction。最后使用 Flink 批作业配合 Flink 实时流作业,比如使用 Batch 任务做冷启动,数据的修正,以及 backfill 等。
李老师也收集了一些用户使用 Flink Batch 的反馈,分享了使用过程中的一些问题,包括:配置的开箱即用,文档中流批模式的行为区别,Hive Partition 过多导致的编译耗时和 GC 问题,HistoryServer 的稳定性问题等等。其中有一些社区已经解决了,有些还需继续完善。
总结 Shopee 这一年的工作,主要就是将 Flink Batch 落地使用起来了。一方面建设了平台将 Flink Batch 任务都管理起来。另一方面,引擎侧提高了任务稳定性。因为现在迁过来的用户,并不是那么关心性能,稳定性是第一位。主要是将 Remote Shuffle Service 搭建了起来,来提高任务的稳定性。
字节跳动的 Flink Batch 实践经验
来自字节跳动的技术专家、Apache Flink & Apache Calcite Committer 李本超老师,分享了字节跳动内部 Flink Batch 的实践经验。字节跳动内部主要有四种 Flink Batch 的使用场景。
第一类是流批一体的场景,这个场景我们定义批是流的一个补充或校验。流批一体场景的作业已经上线比较久了,现在线上有大概有 4000 多个任务,但是其中有大概 300 个以上是常规调度运行,其他的都是一次性或者手工去触发执行。
第二个场景是数据同步场景。非 SQL 场景都是用的 Flink Batch 做的数据同步。SQL 场景主要分为两类,一类是单纯的表同步,比如说从 Hive 表同步的某 KV 系统。像这种任务大概有 1 万多个,目前全部迁移到了 Flink Batch 上。另一类是在迁移中间会有一个复杂的 SQL 加工,也就是 ETL 任务,整体是有 3 万多个,目前已经完成了 2000 多任务的迁移。这个场景里主要面临的问题是目前的 Hive SQL 兼容无法支持某些 Spark 语法的兼容,这是目前正在努力解决的一个问题。在稳定性方面,因为有推测执行、单点 Failover、Shuffle Servcie、黑名单等功能,所以任务的稳定性整体还不错。
第三个场景是特征计算场景。这个场景的特点是数据量会比较大,任务数量相对来讲不会特别多。目前大概有 200 多个任务,比较大的单个任务可能会有上百 T 左右的数据处理,这块字节内部也针对大规模数据处理任务的性能优化。
第四个场景是 OLAP 场景。字节跳动在 FFA 2022 上也有几个演讲分享了 Flink 在 OLAP 方向上的改进。字节跳动在自建的 ByteHTAP 系统里面,用的就是 Flink Batch 的能力去做的 OLAP 查询。当前可以做到单集群的 200QPS 以上的吞吐。这个场景一般都是使用的 pipeline 模式。相对来讲 Query 的数据量不会超大,但是对 QPS 和响应延迟要求比较高。这里边我们做了很多 SQL 的优化,包括像 AGG 的下推、CodeGen Cache、Runtime Filter 等等。
邀请 | 第二场 Flink Batch 社区开发者会议
为了进一步促进社区与用户的交流,让更多的开发者参与到 Flink Batch 的建设中来,我们将于 2 月 22 日组织下一场的 Flink Batch 社区开发者会议,将重点讨论 Flink Batch Roadmap 以及下个版本的工作重点,欢迎大家在 Roadmap 文档中添加您认为重要的功能需求,欢迎届时积极讨论,也欢迎提交其他讨论议题。
会议时间
2 月 22 日 (周三)晚上 19:00 到 20:00。
日程邀请
加入 https://groups.google.com/g/flink-sync Google 群组获取日程邀请。
会议议题
- Flink Batch Roadmap 讨论
- (欢迎提交其他讨论议题)
参会方式
本次会议采用 AliMeeting,点击链接即可入会,无需安装软件:alimeeting
欢迎所有社区开发者和用户加入,一起分享讨论,一起打造一款世界级的流批一体计算引擎!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









