







代码链接:GitHub - cv516Buaa/tph-yolov5
如果进入不了github,就在这里下载,没有权重(免费的): https://download.csdn.net/download/weixin_44911037/86823848
这是一篇针对无人机小目标算法比赛后写的论文,无人机捕获场景下的目标检测是近年来的热门课题。由于无人机总是在不同的高度上飞行,目标尺度变化剧烈,给网络优化带来了负担。此外,高速和低空飞行会使密集的物体产生运动模糊,这对目标识别带来了很大的挑战,如下图所示是无人机拍摄的场景,我们可以看出无人机拍摄的图片尺度变化确实非常大。

在VisDrone2021测试挑战数据集上,提出的TPH-YOLOv5达到39.18% (AP),比DPNetV3(之前的SOTA方法)高出1.81%。在VisDrone2021 DET挑战赛中,TPH-YOLOv5获得第5名,与第一名相比差距不大。
这篇文章所做的贡献在于:1、增加了一个检测头,用于更好地检测小目标,这是很多学者解决小目标的基本操作,但是这种操作会给模型行整体增加计算量。2、利用Transformer来更改原来yolov5的检测头,个人认为这部分是这篇比赛论文比较大的创新点,算是把Transformer和CNN结合起来。3、引入CBAM注意力机制模块,这部分算是一个比较常规的操作,毕竟注意力机制在目标检测中的作用还是比较大的,当然要放在合适的地方。4、提供了一些有用的策略,比如说数据增强,例如数据增强,多尺度测试(这种方法在第一定程度会增加最终的mAP)、使用了额外的分类器。5.使用了自训练分类器来提高对一些混淆类别的分类能力(这是针对相似车但是属于不同的类)。
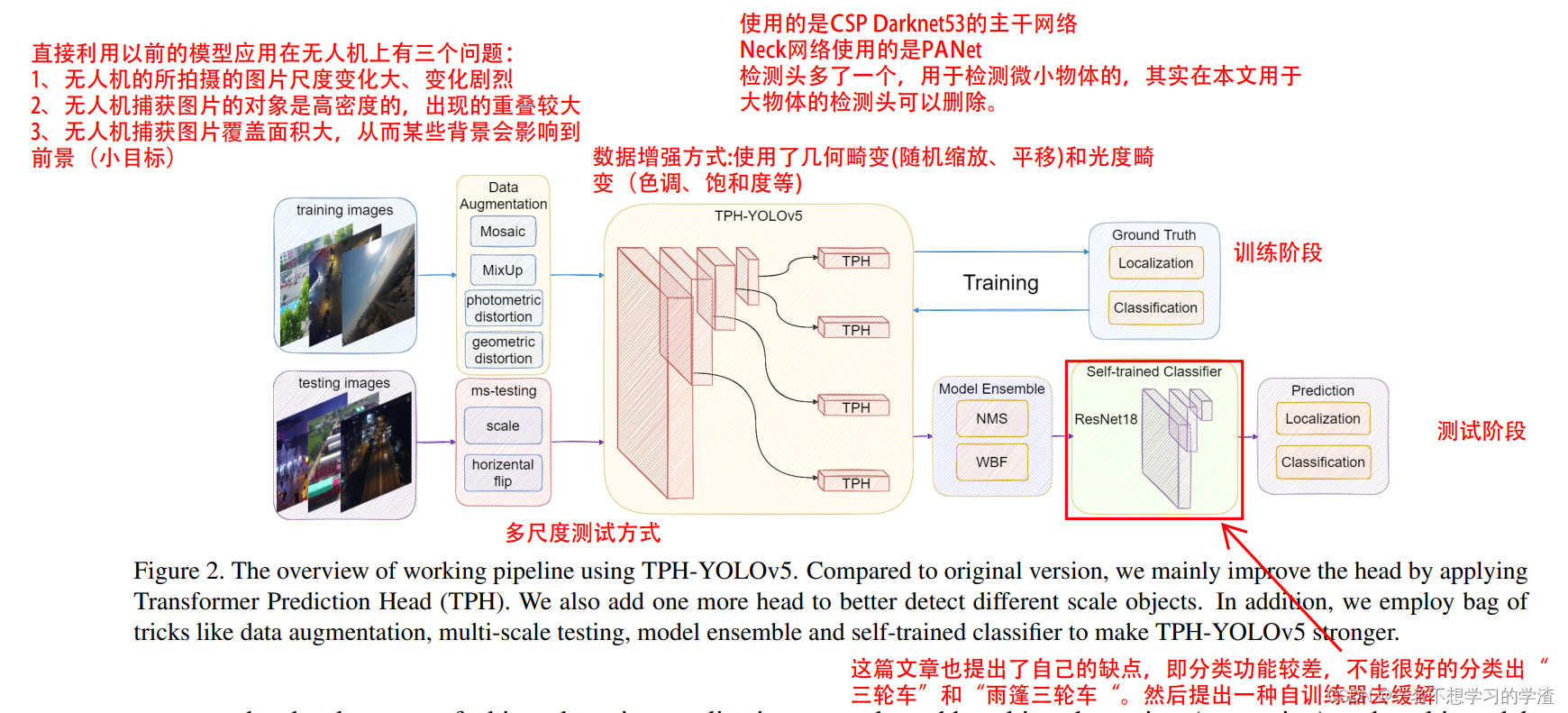
在这篇文章中,对于最后预测后处理使用集成的方式,我们可以从图中可以看出,他使用WBF和NMS的集成方式,对于WBF我在下图给出解释,相当于另外生成一种加权后的预测框,想了解更深可以看论文:https://arxiv.org/abs/1910.13302,当然具体怎么集成的还是需要看代码才能准确知道,后面有时间再看。
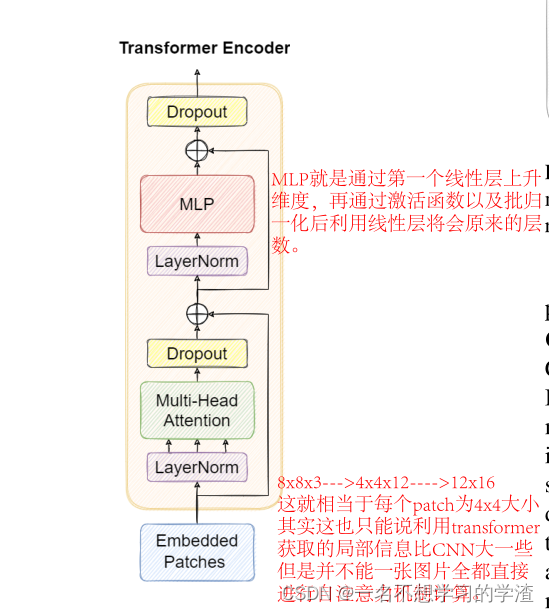
 至于网络模型的具体结构,如上图所示,在特征增强(NECK)中使用了Transfromer 的结构,因为transformer能够获得更大的感受。其实在一部分我还是比较困惑的,就是将3维的特征变成二维再转变成3维的不嫌麻烦吗?又或者这里面的结构数据会不会发生某种变化,当然这是我一直困惑的事情,我后面好好看看代码,看看它的模型结构。具体代码就是下面的。将特征层转成向量再转成特征层。
至于网络模型的具体结构,如上图所示,在特征增强(NECK)中使用了Transfromer 的结构,因为transformer能够获得更大的感受。其实在一部分我还是比较困惑的,就是将3维的特征变成二维再转变成3维的不嫌麻烦吗?又或者这里面的结构数据会不会发生某种变化,当然这是我一直困惑的事情,我后面好好看看代码,看看它的模型结构。具体代码就是下面的。将特征层转成向量再转成特征层。
class TransformerBlock(nn.Module):
# Vision Transformer https://arxiv.org/abs/2010.11929
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
b, _, w, h = x.shape
p = x.flatten(2).unsqueeze(0).transpose(0, 3).squeeze(3)
return self.tr(p + self.linear(p)).unsqueeze(3).transpose(0, 3).reshape(b, self.c2, w, h)下面是就是一般的Transformer的编码结构。
总体来说,这篇文章给我的一些参考意见就是使用Transformer来对小目标检测。
class TransformerLayer(nn.Module):
def __init__(self, c, num_heads):
super().__init__()
self.ln1 = nn.LayerNorm(c)
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.ln2 = nn.LayerNorm(c)
self.fc1 = nn.Linear(c, 4*c, bias=False)
self.fc2 = nn.Linear(4*c, c, bias=False)
self.dropout = nn.Dropout(0.1)
self.act = nn.ReLU(True)
def forward(self, x):
x_ = self.ln1(x)
x = self.dropout(self.ma(self.q(x_), self.k(x_), self.v(x_))[0]) + x
x_ = self.ln2(x)
x_ = self.fc2(self.dropout(self.act(self.fc1(x_))))
x = x + self.dropout(x_)
return x














 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









