







1. 向量加法
- 通过初始化 2 24 2^{24} 224大小的向量A,B;将其相加,并且对于使用CPU计算以及使用GPU并行计算的时间效率。
- 首先,nelem= 2 24 2^{24} 224,即向量的大小为16M
- 在使用gpu并行时,设置了 2 24 / 1024 = 16384 2^{24}/1024=16384 224/1024=16384个块,每个块的大小都为1024.
- 即设置dim3 block(1024);grid(16384);
- 最后对比CPU和GPU的运行效率
主要执行步骤:
- 设置向量大小,分配host内存,并进行数据的初始化
- 在host上进行向量加法运算,计算运行时间
- 分配device内存,将数据从host拷贝到device
- 调用CUDA的核函数在device上完成向量加法运算,计算运算时间
- 然后将device的运算结果拷贝到host
- 对比host和device上得到的结果是否一致(代码中只打印了前10个和)
- 最后记得释放device和host上分配的内存空间
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<stdio.h>
#pragma once
#include<malloc.h>
#include<time.h>
#include<windows.h>
#define N 1<<24
__global__ void addOnGPU(int* a, int* b, int* c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
void addOnCpu(int* a, int* b, int* hostRef, const int n) {
for (int idx = 0; idx < n; idx++) {
hostRef[idx] = a[idx] + b[idx];
}
}
int main() {
int nelem = N;
size_t nBytes = nelem * sizeof(int);
int* h_A, * h_B, * hostRef, * gpuRef;
h_A = (int *)malloc(nBytes);
h_B = (int *)malloc(nBytes);
hostRef = (int*)malloc(nBytes);
gpuRef = (int*)malloc(nBytes);
clock_t iStart = clock();
double iElaps;
iStart = clock();
for (int i = 0; i < nelem; i++) {
h_A[i] = i;
}
for (int i = 0; i < nelem; i++) {
h_B[i] = i;
}
clock_t iEnd = clock();
iElaps = (double)(iEnd-iStart)/CLOCKS_PER_SEC;
printf("初始化用时:%f\n", iElaps);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
//在cpu上做向量的加法
iStart = clock();
//printf("istart %f\n", (double)iStart/CLOCKS_PER_SEC*10000000000);
addOnCpu(h_A, h_B, hostRef, nelem);
iEnd = clock();
//printf("iend %f\n", (double)iEnd/CLOCKS_PER_SEC*10000000000);
iElaps = (double)(iEnd - iStart) / CLOCKS_PER_SEC;
printf("cpu向量用时:%f\n", iElaps);
//开辟gpu的内存
int* d_a, *d_b, *d_c;
cudaMalloc((int**)&d_a, nBytes);
cudaMalloc((int**)&d_b, nBytes);
cudaMalloc((int**)&d_c, nBytes);
//将数据从gpu复制到cpu运行
cudaMemcpy(d_a, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_B, nBytes, cudaMemcpyHostToDevice);
//调用核函数
iStart = clock();
int iLen = 1024;
dim3 block(iLen);
dim3 grid((nelem + block.x - 1) / block.x);
addOnGPU << <grid, block >> > (d_a, d_b, d_c);
cudaDeviceSynchronize();//因为CPU和GPU是异步的,为了能够等待GPU的运行结果之后,CPU再进行下一步操作,使用此函数
iEnd = clock();
iElaps = (double)(iEnd - iStart) / CLOCKS_PER_SEC;
printf("gpu向量用时:%f\n", iElaps);
//将gpu结果从gpu拷贝到cpu
cudaMemcpy(gpuRef, d_c, nBytes, cudaMemcpyDeviceToHost);
//验证cpu和gpu得到的结果是否相同
printf("cpu result:");
for (int i = 0; i < 10; i++) {
printf("%d ", hostRef[i]);
}
printf("\n gpu result:");
for (int i = 0; i < 10; i++) {
printf("%d ", gpuRef[i]);
}
//最后释放相关的cpu和gpu的内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return 0;
}
运行结果:
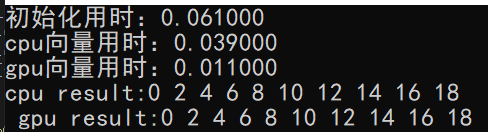
可以看到,在16M的数据集下,此时gpu的运行效率是cpu的3.5倍左右















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









