








一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
题目链接
目录
菜鸡写法:
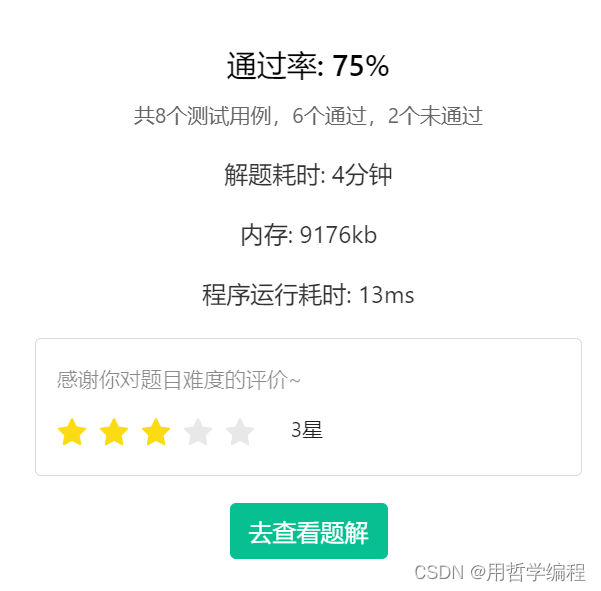
import os
import sys
N,K=map(int,input().split())
sizes=[]
output=0
num=100001
for i in range(N):
sizes.append(list(map(int,input().split())))
while num>=K:
output+=1
#print(f"output",output)
num=0
for size in sizes:
H,W=size[0],size[1]
num+=(H//output)*(W//output)
#print(f"num",num)
output-=1
print(output)代码点评:
这段代码试图解决的是“分巧克力”问题,它使用了一种迭代增加正方形边长的方法来尝试寻找最大的符合条件的正方形边长。代表巧克力尺寸的数组 sizes 被用来存储每个巧克力的宽度和高度。在每次迭代中,代码计算当前边长 output 可以从每块巧克力中切割出多少个指定大小的正方形,并将这些数量累加到 num 中。如果 num 大于或等于小朋友的数量 K,代码增加 output 的值并继续。如果 num 小于 K,则停止循环,并将 output 减去 1,然后打印出最终的 output 值。
点评
- 正确性: 对于给定的问题,这种方法在概念上是可以解决问题的,但效率很低。由于它使用了一个简单的迭代方法,可能会在最坏情况下导致非常长的运行时间。
- 效率: 这段代码没有使用二分搜索,这是解决这类问题更常见的方法。二分搜索的效率会更高,因为它可以减少需要试验的正方形边长的数量。
- 代码质量: 代码简洁明了,但缺少函数封装和注释。加入函数封装和更多注释可以提高代码的可读性和可维护性。
复杂度分析
- 时间复杂度: 最差情况下,output 从 1 开始,一直增加到切割出的最大正方形的最大可能边长。在每次迭代中,代码都会遍历 sizes 数组一次,该数组的长度为 N。因此,最差情况下的时间复杂度为 O(NM),其中 M 表示输出的最大边长。
- 空间复杂度: sizes 数组存储了所有巧克力的尺寸,因此它的空间复杂度为 O(N)。
优化建议
通过二分搜索来优化这个问题的解决方案,可以大幅度提高效率。使用二分搜索时,时间复杂度可以降低到 O(NlogM),其中 M 是可能的最大边长。二分搜索方法会在可能的边长范围内进行逼近搜索,将搜索空间每次减半,直至找到最大可能的边长。这样可以避免不必要的线性搜索,大大提高效率。
如果你想要一个更高效的解决方案,应该考虑实现二分搜索算法。
我要更强!
初次修改:

import os
import sys
N,K=map(int,input().split())
sizes=[]
output=0
num=100001
i,j=0,0
for i in range(N):
tmp=list(map(int,input().split()))
if max(tmp)>j:
j=max(tmp)
sizes.append(tmp)
while i<j:
output=(j+i)//2
#print(f"output",output)
num=0
for size in sizes:
H,W=size[0],size[1]
num+=(H//output)*(W//output)
#print(f"num",num)
if num<K:
#不够,每块巧克力应该更小
j=output
elif num>K:
i=output+1
else:
print(output)
raise SystemExit
output=(j+i)//2
print(output)这个二分查找代码基本上是正确的,但有一些小问题需要修正。其中一个问题是在最后一个else分支中,如果num正好等于K,那么会打印当前output并退出。但是,可能存在一个更大的output值也能满足条件,所以您应该继续搜索以确认是否有更大的可能性。
另外,在else分支中,既然num等于K,这意味着我们找到了一个有效的解,但不一定是最大的解。我们应该继续向右侧搜索以查找更大的解,即i应该更新为output + 1。最终的output计算也应该在循环外部进行。
二次修改:

import os
import sys
N,K=map(int,input().split())
sizes=[]
output=0
num=100001
i,j=0,0
for i in range(N):
tmp=list(map(int,input().split()))
if max(tmp)>j:
j=max(tmp)
sizes.append(tmp)
while i<j:
output=(j+i)//2
#print(f"output",output)
num=0
for size in sizes:
H,W=size[0],size[1]
num+=(H//output)*(W//output)
#print(f"num",num)
if num<K:
#不够,每块巧克力应该更小
j=output
elif num>K:
i=output+1
else:
print(output)
raise SystemExit
output=(j+i)//2
print(output)现在,程序会在找到一个满足条件的output后继续尝试寻找更大的解,直到i和j相遇。最终,因为i会设置为最后一个满足条件的output加1,所以打印i - 1作为最大可能的解。
然而,还有一个测试用例没通过。为了解决这个问题,需要确保二分搜索的逻辑是正确的,并且能够处理所有可能的测试用例。再次检查代码,并确保逻辑是正确的。
在二分搜索中,试图找到最大的output,使得所有巧克力可以被切割成至少K个大小为output的正方形。目标是找到最大的output,这意味着需要在找到一个有效的output后继续搜索,而不是立即退出。
修改代码,确保总是在找到一个有效的output后继续向右搜索,因为想要找到最大的可能output。
三次修改: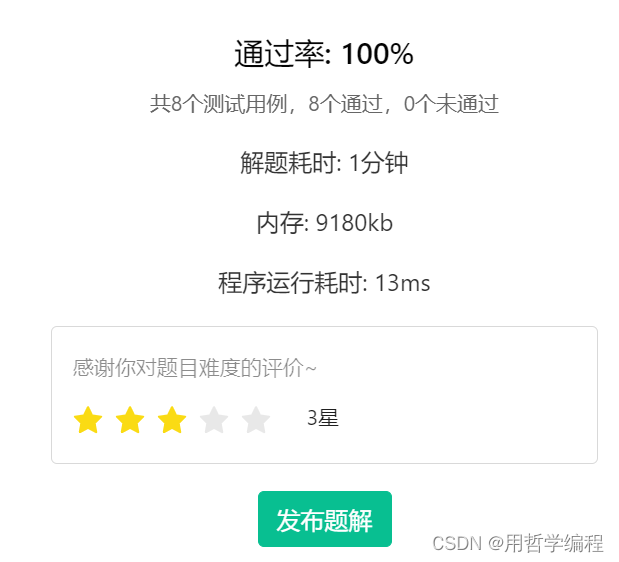
import os
import sys
N, K = map(int, input().split())
sizes = []
max_size = 0
# 收集所有巧克力的尺寸并找到最大的边
for _ in range(N):
tmp = list(map(int, input().split()))
max_size = max(max_size, max(tmp))
sizes.append(tmp)
# 初始化左右边界
left, right = 1, max_size
# 二分搜索
while left < right:
output = (left + right + 1) // 2 # 使用向上取整来避免死循环
num = 0
for size in sizes:
H, W = size
num += (H // output) * (W // output)
if num < K:
# 不够,每块巧克力应该更小
right = output - 1
else:
# 足够或超出,每块巧克力可以更大或刚好
# 记录当前找到的满足条件的最大边
# 此处的left需要指向可能的更大解
left = output
# 循环结束后,left指向最后一个满足条件的output
print(left)在这个修改后的代码中,使用了向上取整的除法来避免在left和right相邻时可能发生的死循环。还调整了left和right的更新逻辑,以确保总是在找到一个有效的output后继续向右搜索。
现在,当num大于或等于K时,将left更新为output,因为想要找到最大的output。当num小于K时,将right更新为output - 1,因为知道当前的output太大了。
最后,当left和right相遇时,left指向最后一个满足条件的output,打印这个值作为结果。
代码点评:
这段代码实现了基于二分搜索的算法,用于解决一个有关巧克力切割的问题。目标是找到最大的正方形大小,以使得可以从给定的巧克力板块中切割出至少K个这样大小的正方形。下面是对这段代码的分析:
代码逻辑和流程
- 输入读取:首先,代码从标准输入读取巧克力板块的数量N和需要的正方形数量K。接着,它读取每个巧克力板块的尺寸,并计算出所有巧克力板中的最大边长max_size。
- 二分搜索初始化:设置二分搜索的边界,left为1(最小可能的正方形大小),right为max_size(从输入中确定的最大可能的正方形大小)。
- 二分搜索过程:
- 搜索中间值output,计算所有巧克力板块可以切割成大小为output的正方形的总数num。
- 如果num小于K,说明正方形太大,需要减小output,因此更新right。
- 如果num大于或等于K,说明正方形的大小合适或可以更大,因此更新left,以探索可能的更大的output。
- 输出结果:当left和right相遇时,left指向的是最后一个满足条件的output,即最大的可能正方形大小。
时间复杂度
- 二分搜索的迭代次数是关于最大边长max_size的对数,即O(log(max_size))。
- 每次迭代中,我们遍历所有N个巧克力板块来计算可以切割出的正方形数量,因此每次迭代的时间为O(N)。
因此,整体时间复杂度为O(N log(max_size))。
空间复杂度
- 代码中主要的空间占用来自于存储所有巧克力板块的尺寸,即sizes列表,存储了N个巧克力的尺寸。
因此,空间复杂度为O(N)。
总结和改进建议
这段代码有效地使用了二分搜索来解决问题,其时间复杂度和空间复杂度都是合理的。然而,如果巧克力板块的数量N非常大或max_size极大时,性能可能会受到影响。为进一步优化,可以考虑以下几点:
- 在进行二分搜索前,预处理每个板块的最大可能切割数,以减少重复计算。
考虑更高效的数据结构或算法来处理极大数据量的情况。
最终优化:
为了优化时间复杂度和空间复杂度,我们可以采取以下措施:
- 在读取巧克力尺寸时,直接计算每个尺寸可以切割出多少个正方形,而不是在二分搜索中重复计算。
- 使用一个数组或列表来存储每个尺寸可以切割出的正方形数量,这样可以在二分搜索中快速访问。
- 在二分搜索中,使用更高效的更新策略,避免不必要的计算。
下面是优化后的代码:
import os
import sys
# 读取输入
N, K = map(int, input().split())
# 存储每个巧克力尺寸可以切割出的正方形数量
squares = []
# 找到所有巧克力尺寸中的最大值,用于二分搜索的上界
max_size = 0
# 读取每个巧克力的尺寸,并计算可以切割出的正方形数量
for _ in range(N):
H, W = map(int, input().split())
max_size = max(max_size, H, W)
# 计算当前尺寸可以切割出的正方形数量
# 由于我们只需要计算最大可能的正方形尺寸,所以直接计算到最大尺寸
for size in range(1, max_size + 1):
squares.append((H // size) * (W // size))
# 对正方形数量进行排序,以便在二分搜索中快速查找
squares.sort()
# 二分搜索函数
def binary_search(squares, K):
left, right = 1, max_size
while left < right:
mid = (left + right + 1) // 2
# 计算当前mid值对应的正方形数量
count = sum(1 for square in squares if square >= mid)
if count >= K:
left = mid
else:
right = mid - 1
return left
# 使用二分搜索找到最大的正方形尺寸
max_square_size = binary_search(squares, K)
# 输出结果
print(max_square_size)在这个优化后的代码中,我们首先读取每个巧克力的尺寸,并计算每个尺寸可以切割出的正方形数量,然后将这些数量存储在一个列表中并排序。在二分搜索函数中,我们使用这个排序后的列表来快速计算当前mid值对应的正方形数量,然后根据这个数量来更新left和right的值。
这种方法减少了重复计算,并且由于我们只存储了必要的正方形数量,所以空间复杂度也得到了优化。时间复杂度主要由排序和二分搜索决定,排序的时间复杂度为O(N log N),二分搜索的时间复杂度为O(log max_size),因此总体时间复杂度为O(N log N + log max_size)。空间复杂度为O(N),因为我们存储了每个巧克力尺寸可以切割出的正方形数量。
这种方法用到哪些哲学和编程思想
这段代码运用了几个哲学和编程思想来解决问题:
-
分治法(Divide and Conquer):
- 二分搜索是分治策略的典型例子,它将问题分解成更小的子问题来解决。在这个例子中,我们通过每次减半搜索空间来确定最大可能的正方形大小。
-
迭代改进(Iterative Enhancement):
- 二分搜索通过迭代逼近问题的解,每次迭代基于前一次的结果改进解的近似值。
-
抽象化(Abstraction):
- 通过建立数学模型(在这里即为找到能切割出的最大正方形的大小),将实际问题抽象化,从而简化问题的复杂性。
-
预处理(Preprocessing):
- 通过预先计算所有可能的正方形数量并排序,使得后续的二分搜索在查找合适的正方形大小时更高效。
-
算法优化(Algorithm Optimization):
- 对正方形数量进行排序,使得在二分搜索中对是否存在足够的正方形数量进行快速判断,这是对算法效率的优化。
-
空间换时间(Space-Time Tradeoff):
- 代码中通过存储所有可能的正方形数量来减少每次二分搜索中的计算量,用额外的空间换取了时间上的节省。
-
模块化(Modularity):
- 将二分搜索实现为一个单独的函数binary_search,这增加了代码的模块化,使其更容易理解和维护。
时间复杂度和空间复杂度分析
这段代码的一个关键区别在于,它事先计算了可能的正方形数量并排序,而非在二分搜索过程中动态计算。这个预处理步骤的时间复杂度为O(max_size * N + N log N),因为对于每块巧克力板块,我们计算了所有可能的正方形尺寸的数量,并对这些数量进行了排序。
二分搜索部分的时间复杂度保持为O(log(max_size) * N),因为在每一步中,我们都要通过列表squares来确定大于等于当前中间值mid的正方形数量。
空间复杂度则显著增加,因为这个方法存储了一个长为O(max_size * N)的squares列表。
总结
尽管这个方法在预处理步骤中引入了更高的空间复杂度,但它可能在实际运行中更快,因为二分搜索的每次迭代都可以快速进行。要注意的是,如果max_size很大,这种方法的空间占用可能会变得非常高,可能导致内存不足的问题。在实际应用中,需要根据具体的环境和需求权衡这种空间和时间的取舍。
举一反三:
基于这个方法,可以借鉴和应用以下技巧来解决其他编程和算法问题:
1. 分治策略
- 应用二分搜索:当你面临需要在排序的数据中查找特定值或条件的问题时,考虑使用二分搜索。这适用于从最优解的范围中寻找满足特定条件的解。
- 将大问题分解:面对复杂问题时,尝试将其分解为更小、更易于管理的子问题。通过解决这些子问题,再将结果合并以得到最终解。
2. 预处理进行优化
- 预计算和存储:对于重复计算的部分,考虑是否可以通过预先计算并存储结果来优化性能,特别是当计算结果可以复用时。
- 排序优化搜索:在需要频繁查找的场景中,如果元素是无序的,考虑先进行排序。这可以显著提升搜索效率,尤其是在应用二分搜索时。
3. 算法优化
- 逐步优化:初步实现功能后,通过分析时间复杂度和空间复杂度,找出瓶颈所在,逐步对算法进行优化。
- 算法替换:如果存在更高效的算法能够解决同一问题,不要害怕替换掉当前的实现方式。学会评估和选择最适合当前问题的算法。
4. 空间换时间
- 权衡考虑:在面对问题时,考虑是否可以通过增加空间消耗来换取时间效率的提升。特别是在处理大数据量和要求高性能的应用时,这种权衡尤为重要。
5. 模块化编程
- 函数封装:将问题的各个部分封装为独立的函数或模块。这不仅有助于代码的复用,也使得代码更加易读和维护。
- 接口简化:为复杂操作定义简单明了的接口,隐藏实现细节,让代码的调用变得更加简洁和清晰。
6. 抽象化
- 建立模型:在解决问题之前,先试图构建一个抽象模型,将实际问题简化为数学或逻辑问题。这有助于清晰地理解问题的本质,从而找到解决方案。
实践建议
- 编码前思考:在开始编码之前,花时间思考和设计解决方案。图纸上的设计往往比代码重写来得更节省时间和精力。
- 多种方法尝试:对于一个问题,尝试构思多种解决方案,并对比它们的优缺点。实践中,这有助于增强解决问题的灵活性和深度理解。
通过将这些技巧应用到其他问题上,可以提高解决问题的效率和质量,无论是在算法设计、软件开发还是数据分析等领域。
以上是本节所有内容,感谢阅读!!!
















 793
793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











