






对于老程序员来说,ASCII,GBK,UNICODE,UTF-8,UTF-32都是耳熟能详的词汇。但对于新手程序员来说,就可能是略知一二了。本来就来介绍一下这几个词汇的含义,对于初级程序员来说,看完本文的介绍就基本够用了。
一、ASCII
(American Standard Code for Information Interchange)美国信息交换标准代码,实际上是使用一个字节来存储字符的,首位是0,总共可以表示128个字符。
二、GBK
中文字符太多,使用ASCII无法表示出来(用中国人的话来说:还不够我塞牙缝),于是就有了GBK。汉字内存扩展规范(也称国标码),包含2万多个汉字字符,GBK中一个中文字符编码成两个字节(也就是16位)的形式存储。GBK兼容了ASCII字符集(在GBK中,ASCII也是采用一个字节编码)。
例如:我a你,在GBK中的存储形式如下:

三、Unicode字符集
对于中文来说,GBK基本够用了,可以表示
个字符。但是世界上有那么多的国家,GBK对于世界上那么多的国家来说,也不够塞牙缝,于是就有人发明出了Unicode字符集。Unicode叫统一码,也叫万国码。它是国际组织制定的,可以容纳世界上所有的文字、符号的字符集。
1.UTF-32
utf-32是最早的编码方案,用四个字节表示一个字符。它也兼容ASCII码,但是它跟GBK不一样。它用4个字节表示ASCII码,其中,低八位的值为ASCII码,高位用0补齐。
虽然UTF-32的容量大,但是,太奢侈了。它占用的存储空间非常的大,而且它的通信效率也会变低。比如,只是想传递一个ASCII符号的数据,如果采用ASCII字符集,一个字节就够了。但如果用UTF-32编码,就需要四个字节,整整多了三倍空间,通信效率也会慢三倍。
如果想传送一个汉字,使用GBK字符集,只需要两个字节;使用UTF-32,就需要4个字节,比GBK多出了一倍。

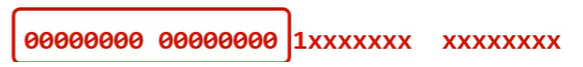
2.UTF-8
为了解决utf-32的缺点,有人发明出了utf-8的编码方案。这是一套新的为unicode设计的编码方案。
utf-8采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节。英文字符、数字等只占1个字节(兼容标准ASCII编码),汉字字符占用3个字节。
utf-8的编码方式如下:
如果是一字节的编码,那就以0开头;如果是二字节的编码,那么,第一个字节以110开头,第二个字节,以10开头;如果是三字节编码,那么第一个字节以1110开头,剩下的字节以10开头;如果是四字节编码,那么第一个字节以11110开头,剩下的字节以10开头。

比如“a我m”这个字符串,在utf-8中,a对应的编码为97(
),“我”对应的编码为25105(
),m对应的编码为109(
)。对于“我”来说,其二进制编码



四、总结
ASCII字符集:只有英文、数字、符号等,占一个字节。
GBK字符集:汉字只占2个字节,英文、数字占一个字节。
unicode字符集:目前使用较多的编码规则是utf-8(也称utf-8字符集),汉字占3个字节,英文、数字占1个字节。
字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会乱码。
英文数字一般不会乱码,因为很多字符集都兼容了ASCII编码。
编码:把字符按照指定字符集编码成字节。
解码:把字节按照指定字符集解码成字符。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









