









个人对2020cvpr的超分网络DRN的一些理解!
论文链接:https://arxiv.org/pdf/2003.07018.pdf
源码链接:https://github.com/fengye-lu/DRN-master
论文的出发点:**目前学习从LR到HR的映射关系的超分网络存在两个问题(1)超分是一个“病态”问题,一张LR图像可以对应多个HR图像,就是说其实LR图像可以由多个HR图像降采样得到,因此可能的映射关系的空间巨大,找到正确的对应关系很困难。虽然可以通过增加模型的复杂度来设计有效的模型,例如EDSR,DBPN和RCAN。但是,这些方法仍然存在解空间大的问题,从而导致超分辨性能有限,不会产生细致的纹理。(2)真实场景下很难获取成对的LR-HR数据,直接给出一张LR图像的话并不清楚他是如何退化而来的,而且真实LR图像和合成图像的分布也不会一致(合成图像?Bicubic降级获得的图像),意思是说在现实生活中一张低分辨率图片产生的方式有很多种,而在我们目前的研究当中,几乎所有的研究人员在训练端到端的深度学习模型时,将HR图片下采样到LR图片都通过特定的方式(比如双三次插值)所以现在的方法无法适应具体情况。因此,能处理实际场景的SR模型是非常具有挑战性的。更关键的是,如果我们将现有的SR模型直接应用于现实世界的数据,它们通常会带来严重的泛化性问题,并产生较差的性能。因此,如何有效利用未配对的数据以使SR模型适应实际应用是一个比较重要的问题。

论文的创新点:为解决上述两个问题,作者提出了****对偶回归方法。通过在LR数据上引入附加约束来减少可能的映射关系的空间:具体表现为除了学习LR到HR的原始映射,还额外学习从HR到LR的对偶映射,形成了一个LR到HR到LR的闭环。(学习一个额外的双重回归映射估计下采样内核重构LR图像形成一个闭环,提供额外的监督。)这样的对偶过程也并不依赖HR图像,可以直接从LR图像学习,所以可以解决真实数据的超分问题!
作者的意思就是针对LR到HR解空间大的问题,作者通过设计一个反向的网络,实现SR到LR的映射,以此来制约和平衡主网络(也就是LR到HR映射的网络)的训练,这里作者设置了一个类似cyclegan形式的loss进而实现平衡网络训练。而为了解决HR和LR成对训练的依赖问题,作者通过在训练集中加入不成对的LR图像,进而实现解决真实世界中数据不成对的问题,那么,LR图像没有对应的HR图像那怎么训练呢?这个问题也能通过后面作者给的损失函数来解决。
论文中给出的概要网络结构:

从上面网络结构就能知道,这篇文章的网络结构分为P网络和D网络。
其中,P网络就是图中蓝线所代表的网络,就是一个常见的LR-HR的超分网络;D网络就是作者最大的亮点贡献,也就是SR-LR的对偶回归过程,该过程不依赖HR!!!
下面来看一下作者提出的loss框架:
针对配对的训练数据,主要是通过对LR数据引入了一个附加约束,除了学习LR 到HR的映射外,本文还学习了从超分辨图像到LR图像的逆映射。实际上,作者将SR问题公式化为涉及两个回归任务的对偶回归模型。损失函数如下图所示,包含两部分,一个是P网络的损失,一个是D网络的损失,权重入推荐设置为0.1。注意这并不是作者最终使用的loss!
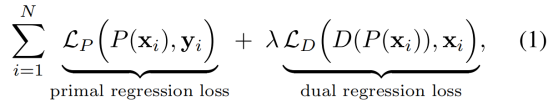
作者所用的loss是这个:
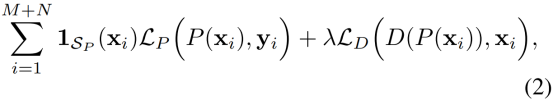
在这里,作者通过控制1sp这个参数来控制训练LR没有对应HR图像的情况下的训练损失函数,通过后面加上lamda权重的D网络损失函数,来平衡P网络的训练,以此来达到减少LR到HR解空间大的问题。
具体怎么实现呢?

如上图,输入数据包含配对和未配对两部分,当输入数据来自配对部分时参数1sp取1,当输入数据来自未配对数据时,参数1sp取0。所以当输入未配对数据时,P网络不计算loss,所以HR就没有用到。
网络的整体结构如下图:

网络讲解:网络将送入网络的数据首先Bicubic放大到目标超分大小,比如图中网络最终超分到4x,所以将输入放大到4x,再经过卷积提取特征图得到图中的绿色特征图块,再将特征块经过一个步长为2的卷积之后,缩小两倍,变成2xLR特征图,同理再变成1xLR图,在经过一堆RCAB块再依次upsample到2x和4xSR,这部分就完成了P网络的工作,然后,再对偶回归,将4xSR结果图经过一个步长为2的卷积层成为2xLR,这里生成的2xLR和原始输入的LR做一次loss,P网络生成的2xSR再下采样为1xLR再来和原始输入LR再做一次D-loss。这便是整个网络的流程。
需要注意的是,D网络中优化的损失函数不止一个,通过上图可以发现对于最后结果为4x的图像,反向进行下采样可以下采样成2x和1x的。而作者在P网络的设计中一开始Input图像(LR通过插值上采样后的)在输入时也经历了两个阶段就是下采样成2x和1x的,所以这就和D网络对应了起来。P网络的2x和D网络的2x图像形成一对,并进行损失函数优化。1x图像也是如此。如果最后的结果是8x的图像,就多一个4x的P网络和D网络的成对优化。
我们同时学习原始映射P重建HR图像和双重映射D重建LR图像。注意,双重映射可以看作是对底层降采样内核的估计。

网络中用到的RCAB是来自于RCAN网络的一个模块RCAB,结构如下:

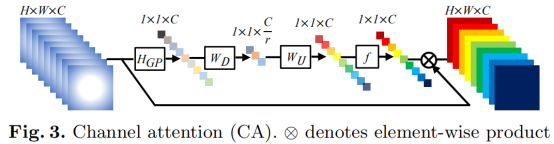
网络的细节设置:

实验:


不同分辨率下,各种方法的对比:


最后,作者对比了在真实场景下的重构效果,这里仅展示了视觉上的结果。也对比了使用不同插值方法下的效果,可发现本文的效果均是最优的。


接下来博主会继续分享自己阅读另一篇2020cvpr做超分的另一篇论文《Image Super-Resolution with Cross-Scale Non-Local Attention
and Exhaustive Self-Exemplars Mining》欢迎感兴趣的小伙伴关注共同学习进步!















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









