







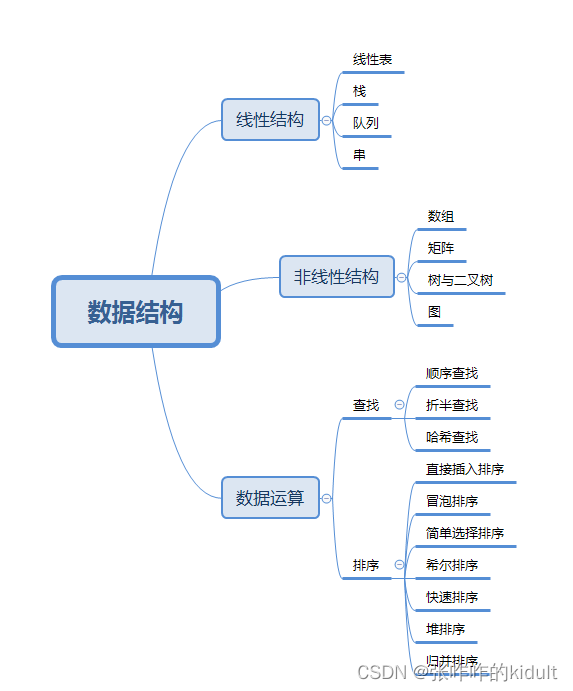
本章导图:
3.1 线性结构
3.1.1 线性表
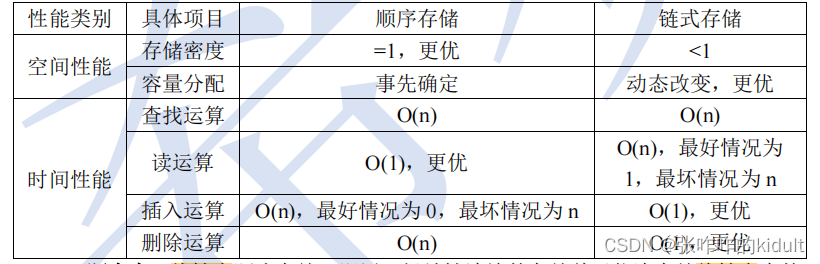
常用顺序存储和链表存储,主要的的操作是增加、删除、查找。
顺序表:线性表顺序存储,即用一组地址连续的存储单元一次存储线性表中的数据元素,从而使得逻辑上相邻的两个元素,在物理上也相邻。在存储之前,先根据线性表的长度连续分配的物理空间,因而后续不方便扩展。只需要存储数据元素,不需要存储元素的逻辑关系因此密度为1.
链表:线性表链式存储,即用通过指针链接起来的结点来存储数据元素,存储各数据元素的结点物理不要求连续,需要同时存储各方面的逻辑关系,存储密度小于1 。
3.1.2 栈和队列❤❤❤
栈:先进后出
队列:先进先出
- 循环队列:
队空条件:head=tail
队满条件:(tail+1)%size=head
3.1.3 串
是特殊的线性结构,串是仅有字符串构成的有限序列,是一种线性表,一般记号为s=“a1a2a3……an”,其中,S是串名,引号里的值是串值。
基本概念
(1)空串与空格串
空串:长度为零,不包含任何字符。
空格串:由一个或多个空格组成的串。虽然空格是一个空白字符,但它也是一个字符,在计算串长度时要将其计算在内。
(2)子串与子序列
子串:由串中任意长度的连续字符构成的序列称为子串。含有子串的串称为主串。子串在主串中的位置是指子串首次出现时,该子串的第一个字符在主串中的位置。空串是任意串的子串。
子序列:一个串的“子序列”(subsequence)是将这个串中的一些字符提取出来得到一个新串,并且不改变它们的相对位置关系。
(3)串比较与串相等
串比较:两个串比较大小时以字符的 ASCII 码值(或其他字符编码集合)作为依据。实质上,比较操作从两个的第一个字符开始进行,字符的码值大者所在的串为大;若其中一个串先结束,则以串长较大者为大。
串相等:指两个串长度相等且对应序号的字符也相同。
串的基本操作:
(1)赋值操作 StrAssign(s,t):将串 s 的值赋给串 t。
(2)连接操作 Concat(s,t):将串 t 接续在串 s 的尾部,形成一个新的串。
(3)求串长 StrLength(s):返回串 s 的长度。
(4)串比较 StrCompare(s,t):比较两个串的大小。返回值-1、0 和 1 分别表示s<t、s=t 和 s>t 三种情况。
(5)求子串 SubString(s,start,len):返回串 S 中从 start 开始的、长度为 len 的字符序列。
模式匹配:子串的定位操作通常称为串的模式匹配。(子串也称为模式串)
KMP 算法:其改进之处在于——每当匹配过程中出现相比较的字符不相等时,不需要回退到主串的字符位置指针,而是利用已经得到的“部分匹配”结果将模式串向右“滑动”尽可能远的距离,再继续进行比较。在 KMP 算法中,依据模式串的 next函数值实现子串的滑动。若令 next[j]=k,则 next[j]表示当模式串中的 pj 与主串中相应字符不相等时,令模式串的 pnext[j]与主串的相应字符进行比较。(j=next[j])
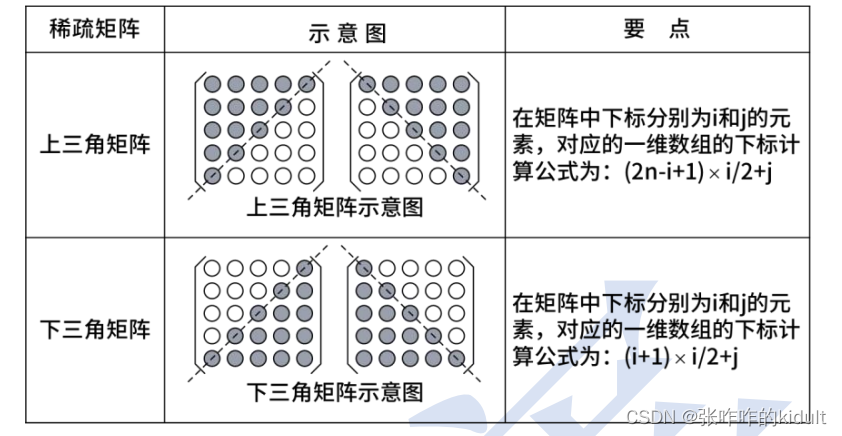
3.2 数组、矩阵和广义表
3.2.1 数组

3.2.2 矩阵
3.2.3 广义表
1、广义表是 n 个表元素组成的有限序列,是线性表的推广。
2、通常用递归的形式进行定义,记作:LS=(a0, a1,…, an)。
注:其中 LS 是表名,ai 是表元素,它可以是表(称作子表),也可以是数据元素(称为原子)。其中 n 是广义表的长度(也就是最外层包含的元素个数),n=0 的广义表为空表;而递归定义的重数就是广义表的深度,直观地说,就是定义中所含括号的重数(原子的深度为 0,空表的深度为 1)。
3、基本运算:取表头 head(Ls)和取表尾 tail(Ls)。
取表头 head(Ls),非空广义表的 Ls 的第一个元素称为表头,它可以是一个单元素,也可以是一个子表。
取表尾 tail(Ls),非空广义表 Ls,除表头元素之外,由其余元素所构成的表称为表尾。非空广义表的表尾必定是一个表。
若有:LS1=(a,(b,c),(d,e))
head(LS1)=a
tail(LS1)=((b,c),(d,e))
3.3 树
3.3.1 树与二叉树的定义
(1)树的概念:
- 双亲、孩子和兄弟:结点的子树的根称为该结点的孩子;相应地,该结点称为其子结点的双亲。具有相同双亲的结点互为兄弟。
(这里涉及到 2 个层次,第一个层次的子树,这棵子树的根是第一层结点的孩子结点,第一层结点是其子节点的双亲节点/父节点)。 - 结点的度:一个结点的子树的个数记为该结点的度
- 叶子节点:也称为终端结点,指度为 0 的结点
- 内部结点:指度不为 0 的结点,也称为分支节点或非终端节点。除根结点之外,分支结点也称为内部结点。
- 结点的层次:根为第一层,根的孩子为第二层,依次类推,若某节点在第 i 层,则其孩子结点在第 i+1 层
- 树的高度:一颗树的最大层次数记为树的高度(深度)
(2)二叉树的重要特性:
- 在二叉树的第 i 层上最多有 2i-1 个结点(i≥1);
- 深度为 k 的二叉树最多有 2k-1 个结点(k≥1);
- 对任何一棵二叉树,如果其叶子结点数为 n0,度为 2 的结点数为 n2,则n0=n2+1。
- 如果对一棵有 n 个结点的完全二叉树的结点按层序编号(从第 1 层到⌊𝑙𝑜𝑔2 𝑛⌋ + 1层,每层从左到右),则对任一结点 i(1≤i≤n),有:
如果 i=1,则结点 i 无父结点,是二叉树的根;如果 i>1,则父结点是i/2 ;
如果 2i>n,则结点 i 为叶子结点,无左子结点;否则,其左子结点是结点 2i;
如果 2i+1>n,则结点 i 无右子叶点,否则,其右子结点是结点 2i+1。
3.3.2 二叉树的性质与存储结构
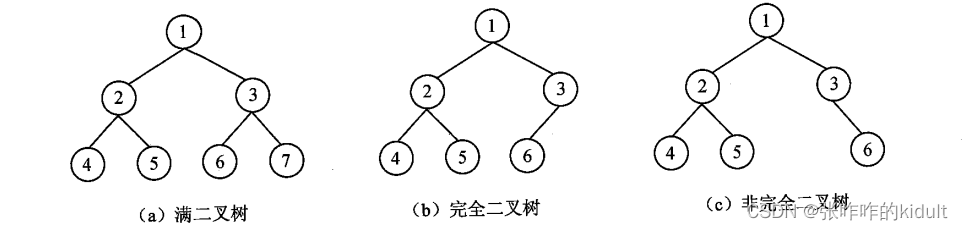
- 二叉树:二叉树是每个结点最多有两个孩子的有序数,可以为空树,可以只有一个结点。
- 满二叉树:任何结点,或者是树叶,或者恰有两棵非空子树。
- 完全二叉树:最多只有最小面的两层结点的度可以小于 2,并且最下面一层的结点全都集中在该层左侧的若干位置。
- 平衡二叉树:树中任一结点的左右子树高度之差不超过 1。
- 查找二叉树:又称之为排序二叉树。任一结点的权值,大于其左孩子结点,小于其右孩子结点。
- 线索二叉树:在每个结点中增加两个指针域来存放遍历时得到的前驱和后继信息。
3.3.3 二叉树的遍历 ❤❤❤
- 前序遍历:又称为先序遍历,按根左右的顺序进行遍历。
- 后序遍历:按左–>右–>根的顺序进行遍历。
- 中序遍历:按左–>根–>右的顺序进行遍历。
- 层次遍历:按层次顺序进行遍历。
3.3.4 线索二叉树
线索二叉树:在每个结点中增加两个指针域来存放遍历时得到的前驱和后继信息。
3.3.5 最优二叉树 ❤❤
最优二叉树:又称为哈弗曼树,它是一类带权路径长度最短的树。
- 路径是从树中一个结点到另一个结点之间的通路,路径上的分支数目称为路径长度。
- 树的路径长度是从树根到每一个叶子之间的路径长度之和。结点的带权路径长度为从该结点到树根之间的- 路径长度与该结点权值的乘积。
- 树的带权路径长度为树中所有叶子结点的带权路径长度之和。
- 哈弗曼树的构造:
(1)根据给定的权值集合,找出最小的两个权值,构造一棵子树将这两个权值作为其孩子结点,二者权值之和作为根结点;
(2)在原集合中删除这两个结点的权值,并引入根节点的权值;
(3)重复步骤(1)和步骤(2),直到原权值集合为空。 - 哈夫曼编码:根据哈夫曼树进行边长编码,编码长度与路径长度相关,左侧分支编码为 0(或 1),右侧分支编码为 1(或 0),从根结点到对应叶子结点所有路径分支上的编码记录下来,即为该叶子结点的编码。
3.3.6 树和森林
3.4 图
3.4.1 图的定义与存储
1、完全图
在无向图中,若每对顶点之间都有一条边相连,则称该图为完全图(complete graph)。
在有向图中,若每对顶点之间都有二条有向边相互连接,则称该图为完全图。
2、图的邻接矩阵表示:用一个 n 阶方阵 R 来存放图中各结点的关联信息,其矩阵元素 Rij 定义为:
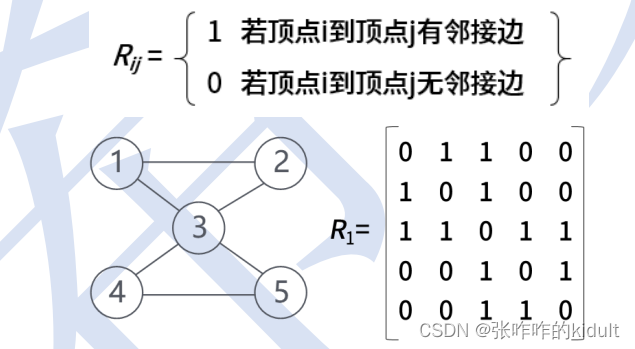
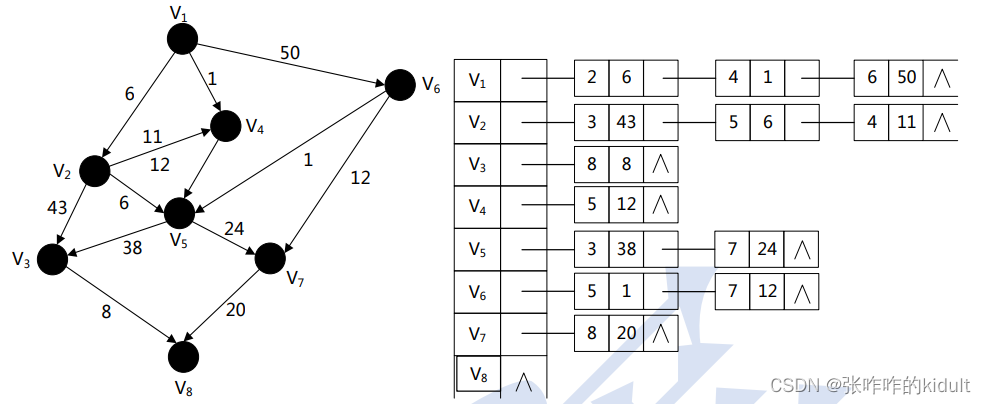
3、图的邻接表表示:首先把每个顶点的邻接顶点用链表示出来,然后用一个一维
数组来顺序存储上面每个链表的头指针。
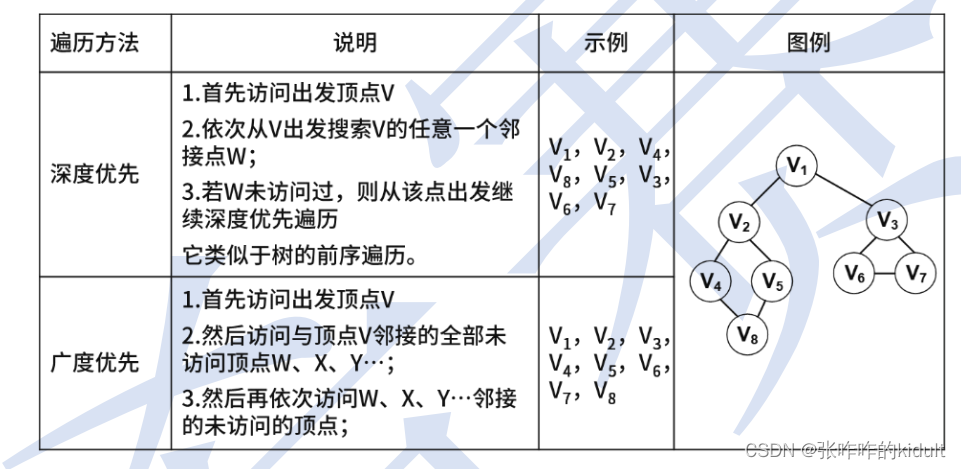
3.4.2 图的遍历
3.4.3 生成树及最小生成树
贪心策略
3.4.4 拓扑排序和关键路径
拓扑排序是将 AOV 网中的所有顶点排成一个线性序列的过程,并且该序列满足:若在 AOV 网点中从顶点 Vi 到 Vj 有一条路径,则在该线性序列中,顶点 Vi 必然在顶点 Vj 之前。
3.4.5 最短路径
3.5 查找
3.5.1 查找的基本概念
查找是一种基本的查找运算。
3.5.2 静态查找表的查找方法
顺序查找
折半查找
分块查找
3.5.3 动态查找表
1、二叉排序树:
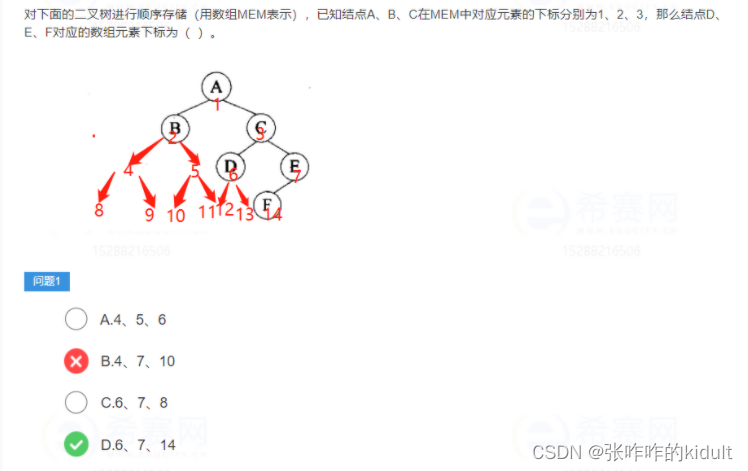
二叉树的顺序存储,就是用一组连续的存储单元存放二叉树中的结点;把二叉树的所有结点安排成为一个恰当的序列,反映出节点中的逻辑关系;用编号的方法从树根起,自上层至下层,每层自左至右地给所有结点编号。
2、平衡二叉树
- 平衡二叉树:树中任一结点的左右子树高度之差不超过 1。
3.5.4 哈希表
常用:线性探测法发生冲突的解决方式。
3.6 排序 ❤❤❤❤
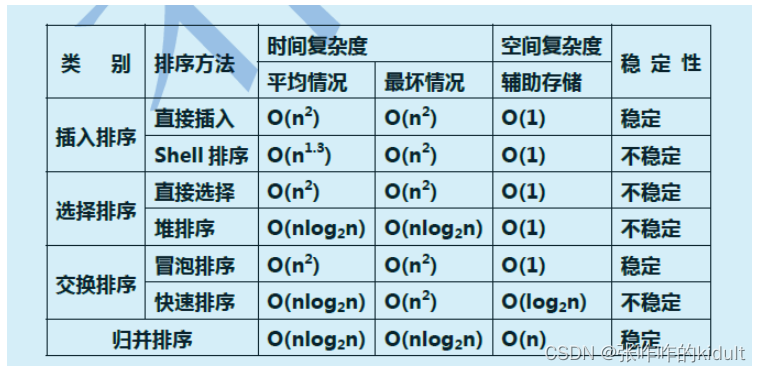
具体的内容可以看这篇文章:一篇厉害的排序文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









