









python_chapter3_爬虫(Requests进阶、cookie登录、refer防盗链、代理、网易云评论爬取)
在这里得感谢,B站up主路飞学城IT提供的优秀视频,此文章仅作为学习笔记,进行记录和分享…
python,爬虫(给兄弟们挂个🔗)
python边写边更…
1.Request进阶概述:
headers为HTTP协议的中的头,一般存放一些安全验证信息,比如常见的User-Agent,token,cookie等;
本章内容:
1.模拟浏览器登录 >>> 处理cookie;
2.防盗链处理 >>> 抓取梨视频数据;
3.代理 >>> 防止被封id;
综合训练:
抓取网易云音乐评论信息;
2.处理cookie,登录小说网:
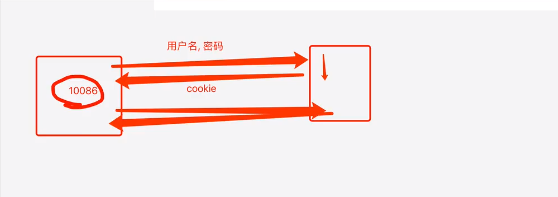
1.当你访问一个网址的时候,带着你的"用户名"和"密码";
2.服务器一端会返回cookie,交给浏览器处理;
3.cookie中会带有一串 “你看不懂的代码” ,例如10086;
4.再下次访问的时候,你拿着10086去请求…服务器端就知道是 “你” 在进行访问;
请求中用到session,在一大串请求中,cookie不会改变;
step1:
#Author:Jony c
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#登录 >>> 拿到cookie
#到着cookie 去请求到书架 url >>> 书架上的内容;
#必须得把上面的两个操作连起来
#我们可以使用session进行请求 >>> session你可以认为是一连串的请求,在这个过程中的cookie不会丢失;
import requests
#会话
session_test = requests.session()
data = {"loginName":"18614075987",
"password":"q6035945"}
#1.登录;
url = "https://passport.17k.com/ck/user/login"
resp = session_test.post(url,data = data)
resp.encoding = "utf-8"
#print(resp.text)
#print(resp.cookies),看cookie
#2.拿书架上的书;
| 操作 | 意思 |
|---|---|
| requests.session() | |
| session.post(url,data) | data = {“loginname”:“用户名”,“password”:“密码”} |

step2:
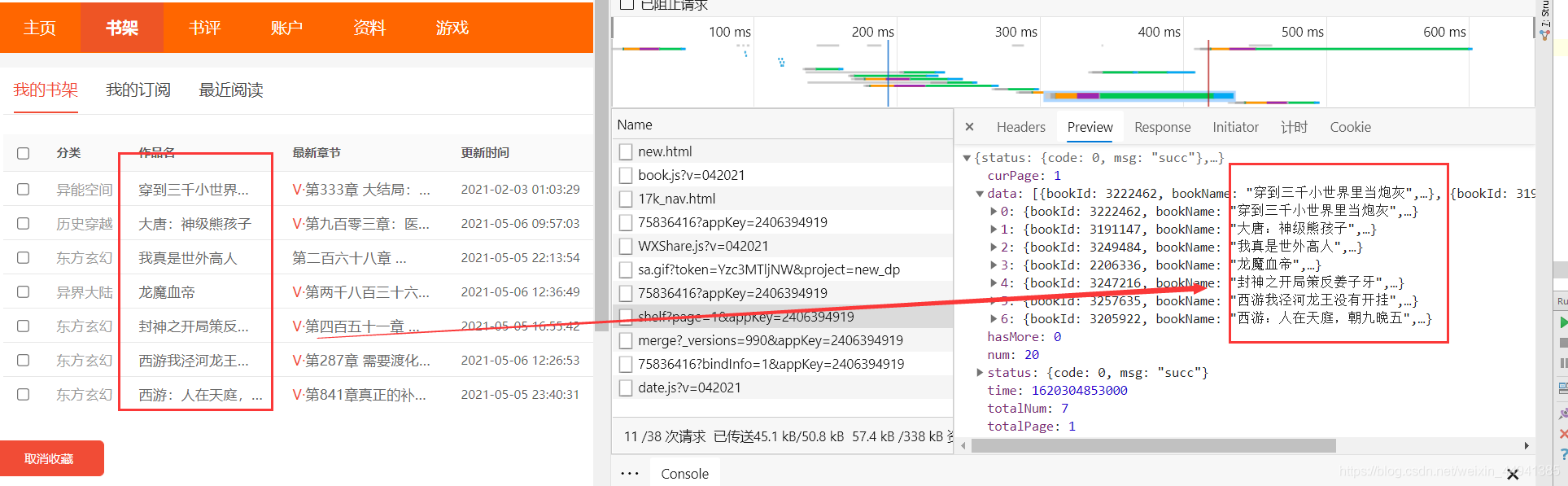
#2.拿书架上的数据;
resp_2 = session_test.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919")
print(resp_2.text)
若你用requests进行请求的时候…(会报错)…
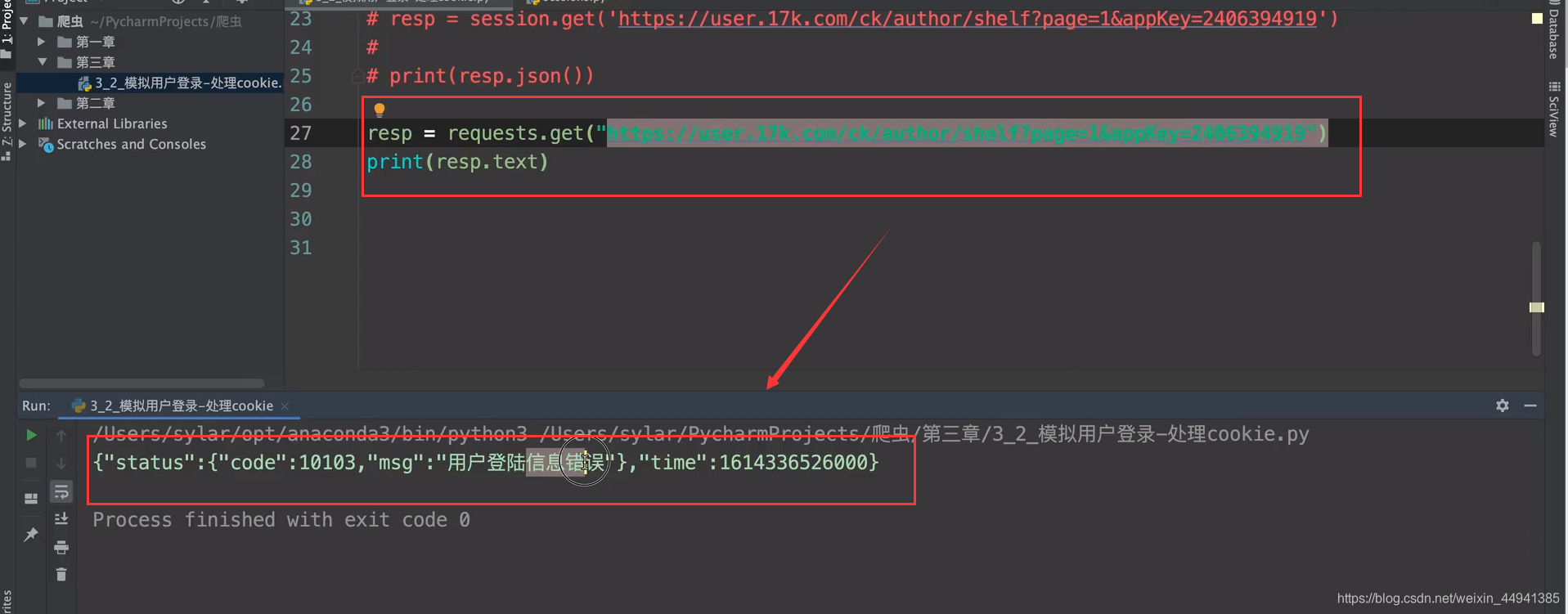
将cookie的信息,拷贝过去…用requests也可以访问…
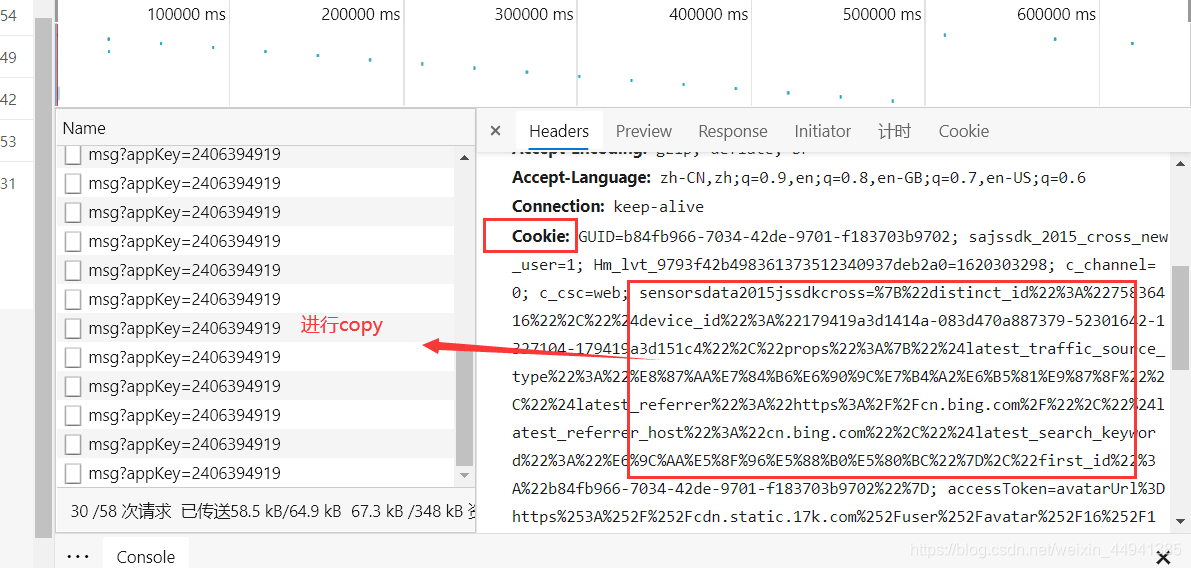
#2.拿书架上的数据;
# resp_2 = session_test.get()
# #print(resp_2.text)
# print(resp_2.json())
head = {"cookie":"GUID=b84fb966-7034-42de-9701-f183703b9702; sajssdk_2015_cross_new_user=1; Hm_lvt_9793f42b498361373512340937deb2a0=1620303298; c_channel=0; c_csc=web; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2275836416%22%2C%22%24device_id%22%3A%22179419a3d1414a-083d470a887379-52301642-1327104-179419a3d151c4%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fcn.bing.com%2F%22%2C%22%24latest_referrer_host%22%3A%22cn.bing.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22b84fb966-7034-42de-9701-f183703b9702%22%7D; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F16%252F16%252F64%252F75836416.jpg-88x88%253Fv%253D1610625030000%26id%3D75836416%26nickname%3D%25E9%25BA%25BB%25E8%25BE%25A3%25E5%2587%25A0%25E4%25B8%259D%26e%3D1635856821%26s%3D4630c67656a6ed26; Hm_lpvt_9793f42b498361373512340937deb2a0=1620304826"}
resp =requests.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919",headers =head)
print(resp.text)
3.防盗链,抓取梨视频:
step1:
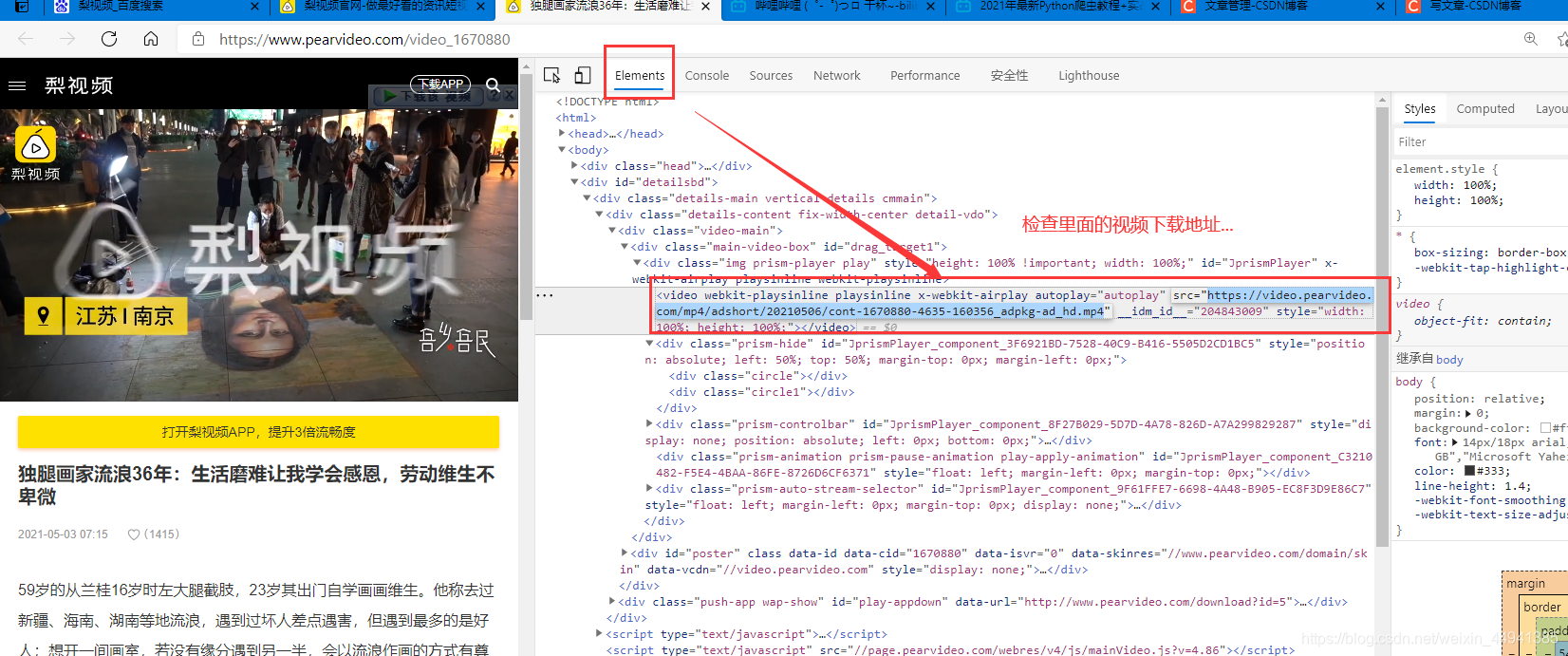
(通过视频的“检查”窗口,找到实时的页面代码…可以copy到视频下载地址;)
https://video.pearvideo.com/mp4/adshort/20210506/cont-1670880-4635-160356_adpkg-ad_hd.mp4
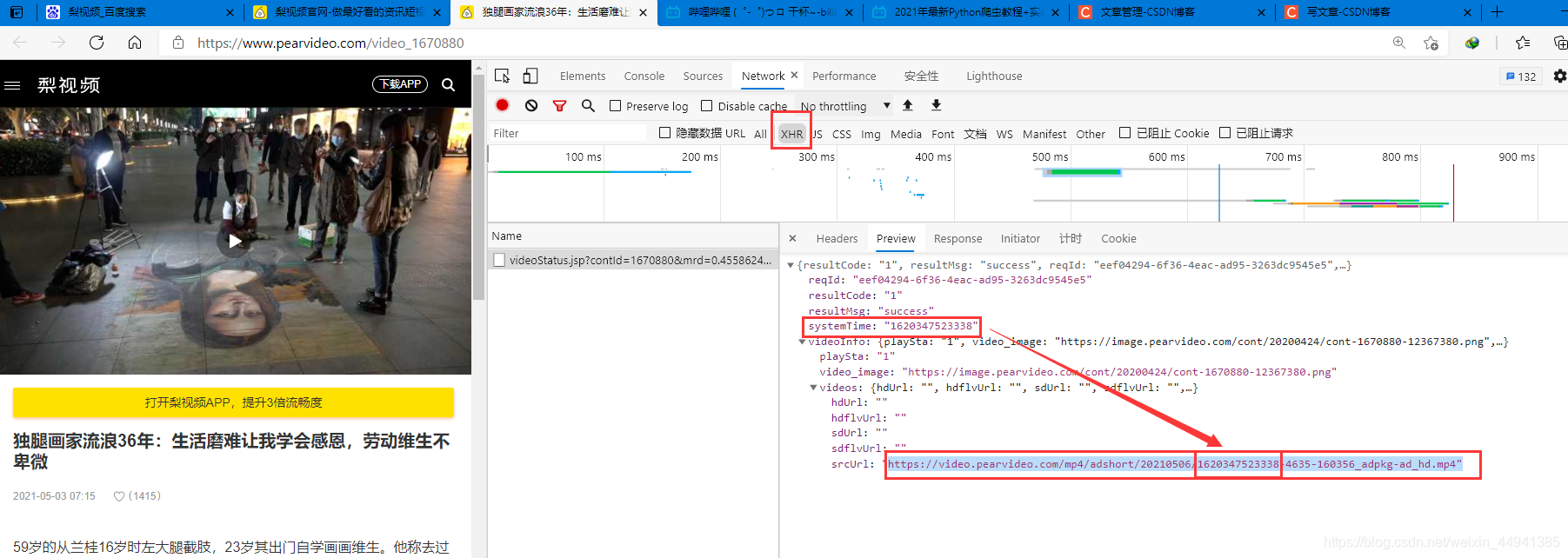
https://video.pearvideo.com/mp4/adshort/20210506/1620347523338-4635-160356_adpkg-ad_hd.mp4"

(其实我们从XHR里面爬取到的地址,在此基础上加以拼接,就可以得到我们真正的下载地址…
tip:这里的下载地址和实时的页面检查代码一样)
step2:
(下面进行拼接步骤…)
import requests
#1.在梨视频中copy你想要访问的网址;
url = "https://www.pearvideo.com/video_1670880"
cont_id = url.split("_")[1]
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={cont_id}&mrd=0.4558624470320054"
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51"}
resp = requests.get(video_url,headers = head)
print(resp.text)
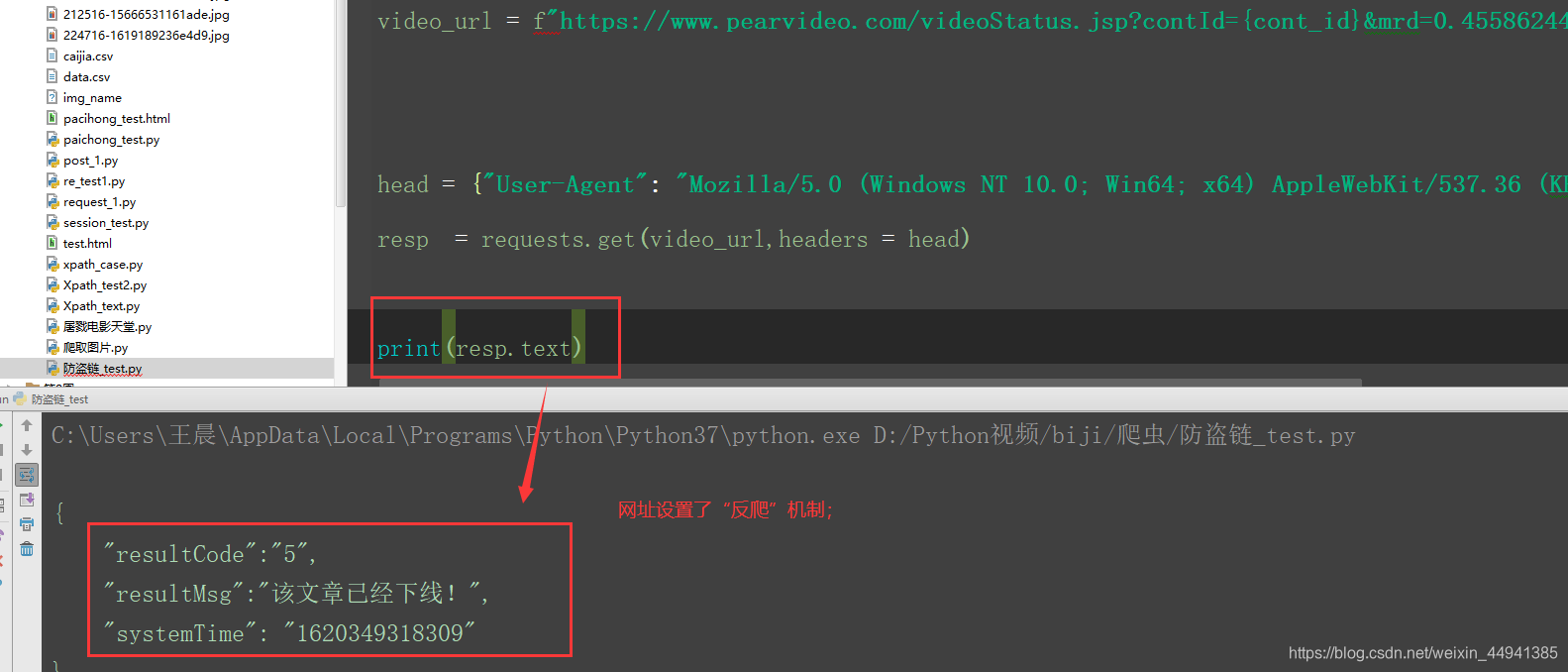
(我们这个程序,是直接访问的video_url,在这里报错的原因就是…服务器会根据请求找溯源,因为我们这个video_url是url所触犯的xhr二次链接,所以想不报错,就得加上refer防盗链,告诉服务器源头是哪…)
import requests
#1.在梨视频中copy你想要访问的网址;
url = "https://www.pearvideo.com/video_1670880"
cont_id = url.split("_")[1]
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={cont_id}&mrd=0.4558624470320054"
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51"
#防盗链,溯源,当前请求的上一级是啥...
,"Referer":url}
resp = requests.get(video_url,headers = head)
print(resp.text)
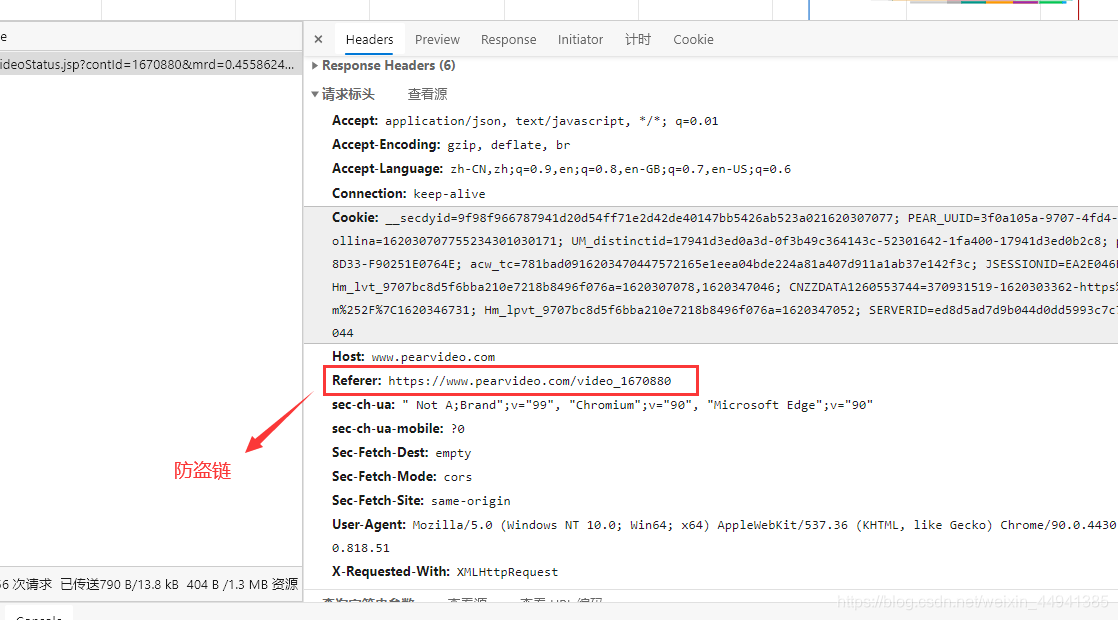

step3:
#1.拿到contid;
#2.拿到videostatus返回的json >>> srcURL;
#3.srcURL里面的内容进行修改;
#4.下载视频;
import requests
#1.在梨视频中copy你想要访问的网址;
url = "https://www.pearvideo.com/video_1670880"
cont_id = url.split("_")[1]
video_url = f"https://www.pearvideo.com/videoStatus.jsp?contId={cont_id}&mrd=0.4558624470320054"
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51"
#防盗链,溯源,当前请求的上一级是啥...
,"Referer":url}
resp = requests.get(video_url,headers = head)
#拿到srcurl;
dic = resp.json()
srcurl = dic["videoInfo"]["videos"]["srcUrl"]#拿到srcurl;
systemtime = dic["systemTime"]
#修改srcurl里面的内容;
srcurl = srcurl.replace(systemtime,f"cont-{cont_id}")
print(srcurl)
#下载视频;
with open("video.mp4",mode = "wb") as f :
f.write(requests.get(srcurl).content)
4.代理:
(假如你访问b站,1秒钟访问1000+,b站肯定觉得你不对劲…就会封你的IP,把你的号封掉…此时你可以代理1000台服务器帮你访问,每个访问1次…达到一样的效果…)
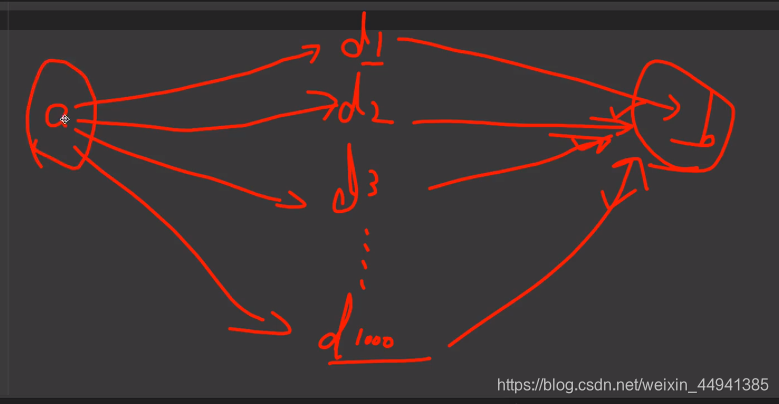
(首先,随便找个免费ip代理网站…)
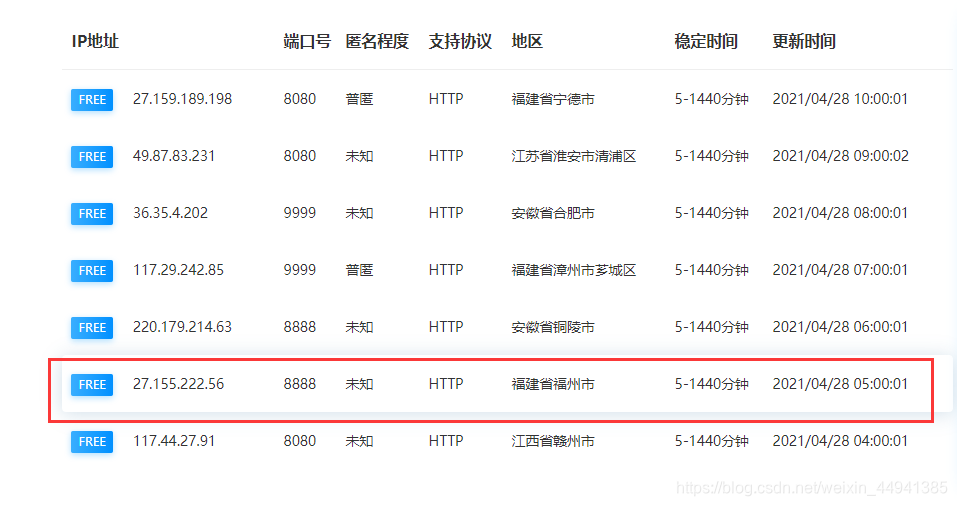
import requests
proxies = {"https":"https://175.43.32.39:9999"}
url = "https://www.baidu.com"
resp = requests.get(url,proxies = proxies)#加上代理
print(resp.text)
5.综合训练:
(网易云评论爬取…)
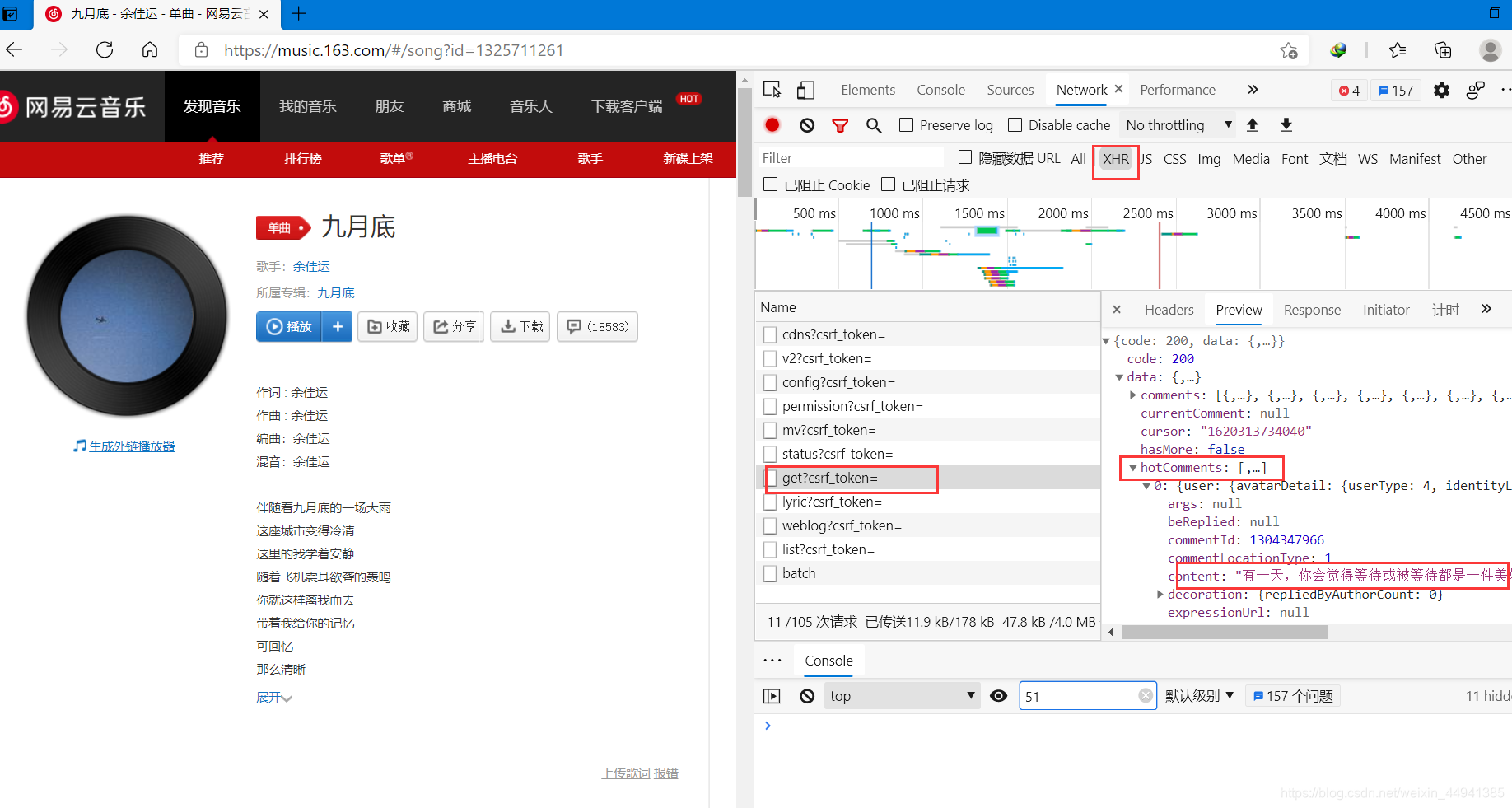

(但是他们的传的参数…都是进行了加密…我们需要得知其加密方式,变成自己的python代码;然后对参数进行加密…然后传给网易服务器)
总之,干两件事情:
1.找到 加密前的参数;
2.详细其 加密过程;
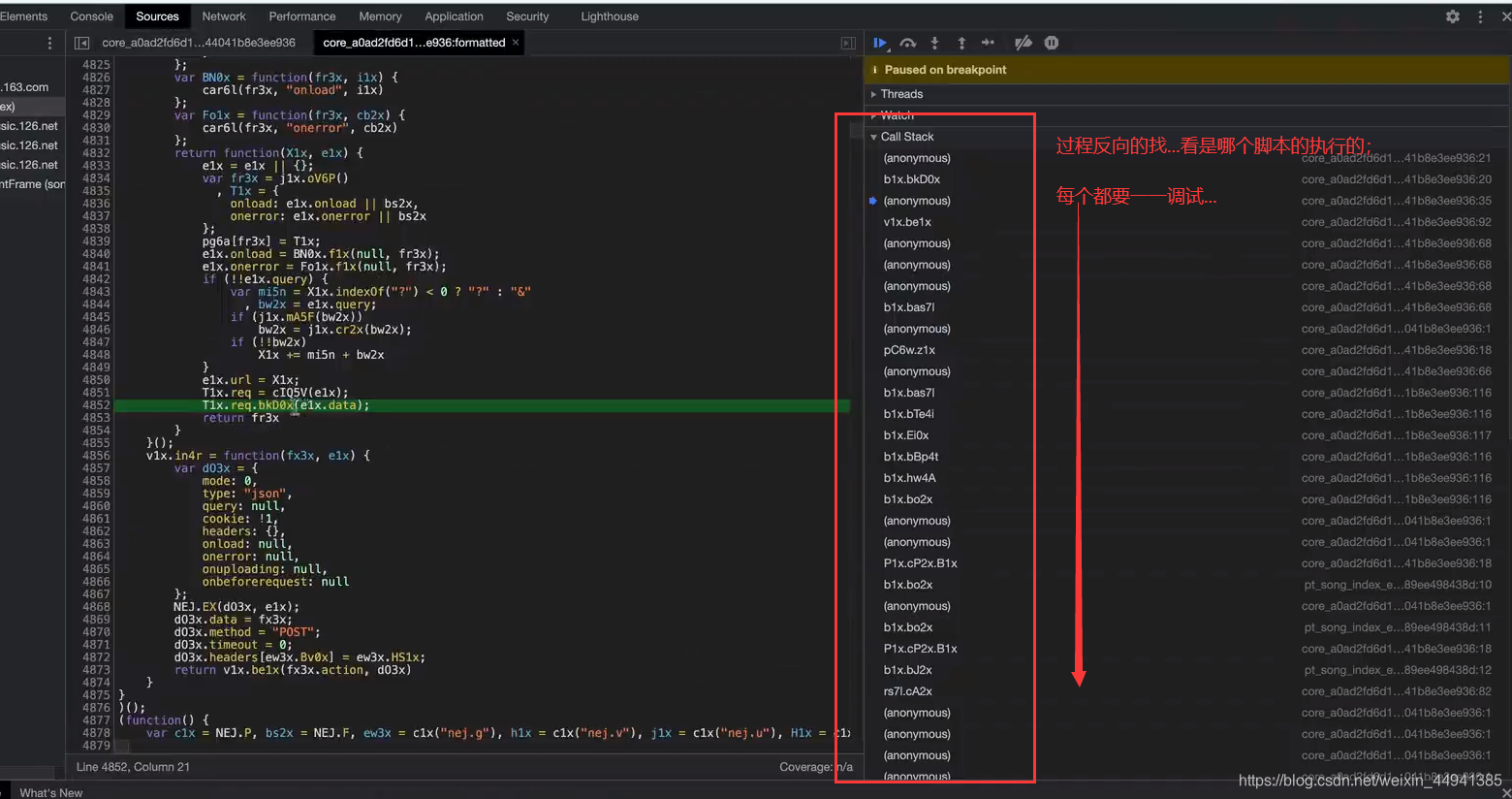
step1:

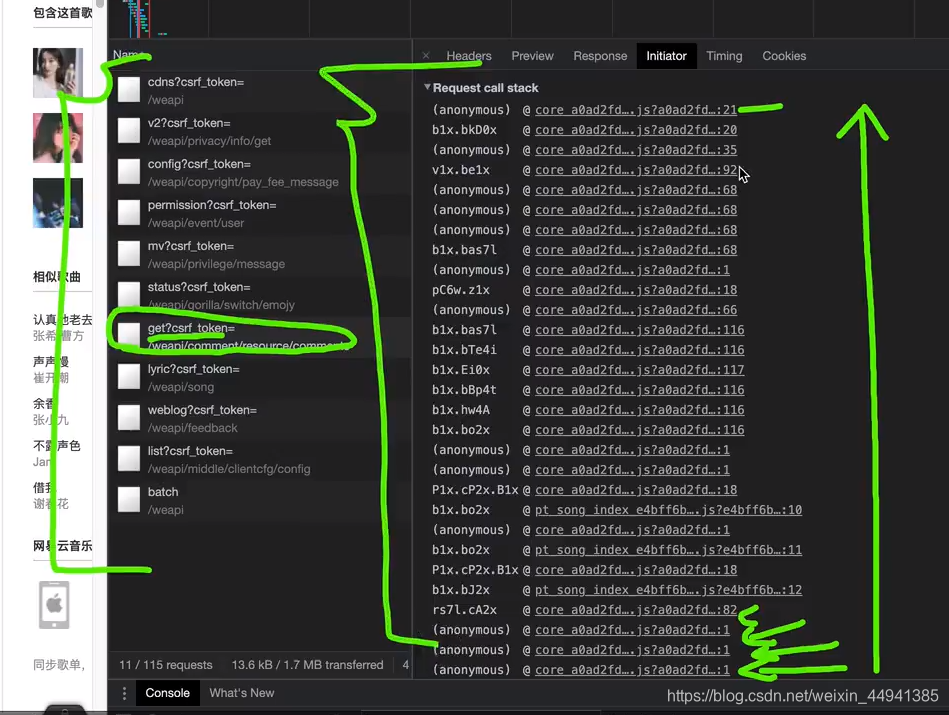
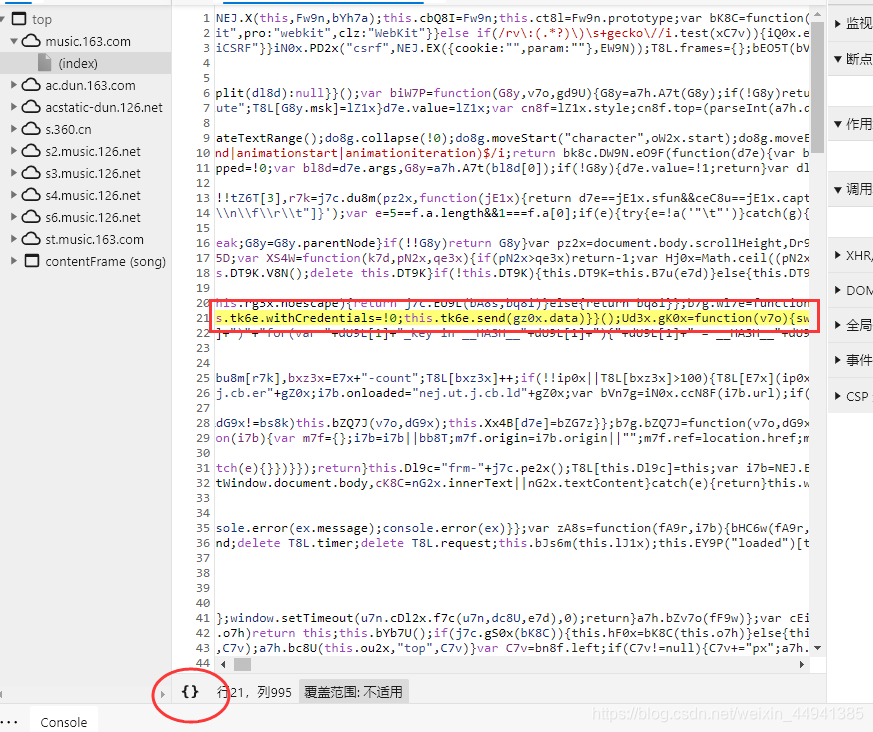
这里是发生这个“请求”,所要执行的所有脚本…从下往上执行

(在这里点击最后一个…执行脚本…)
step2:
step3:
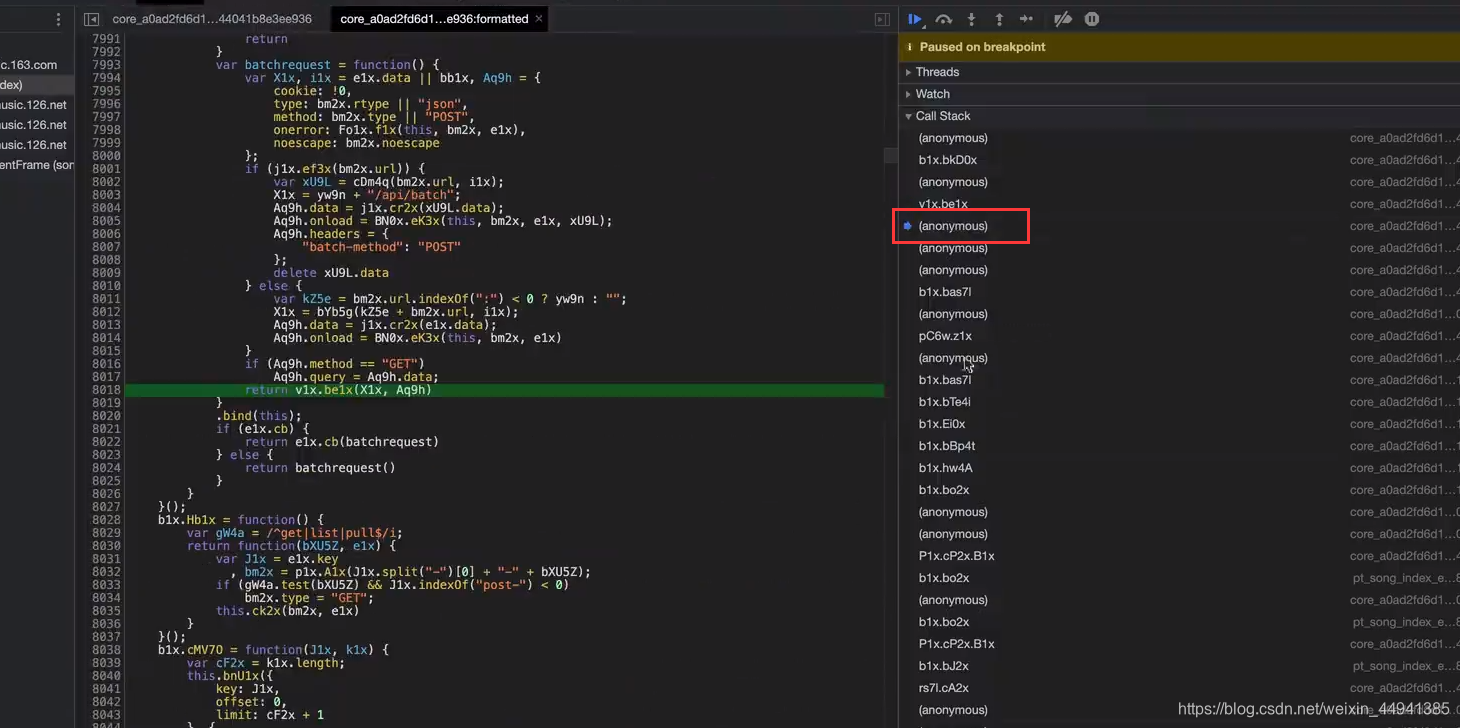
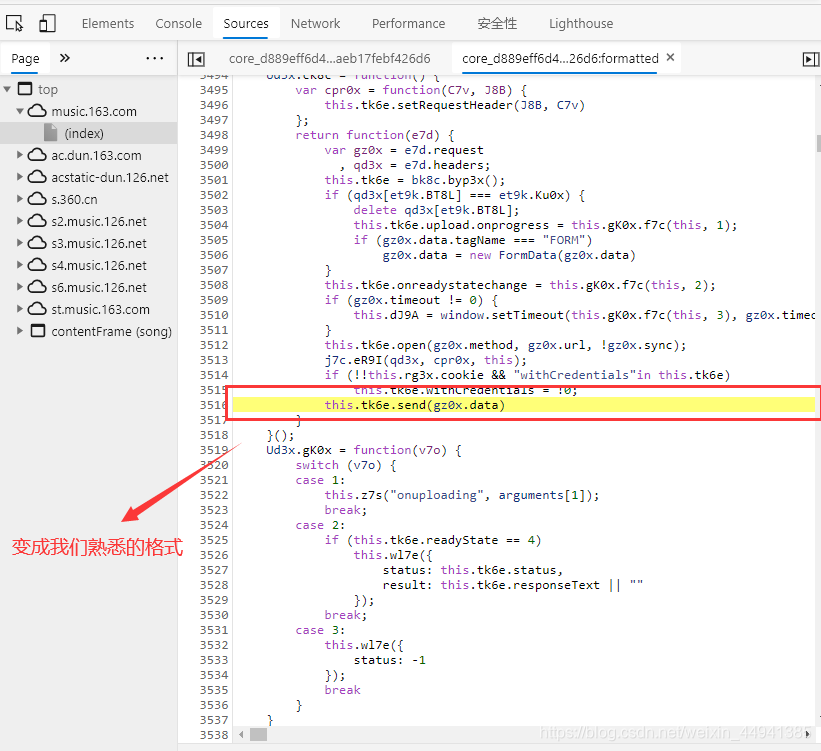
这个脚本之前,还是没被加密的…
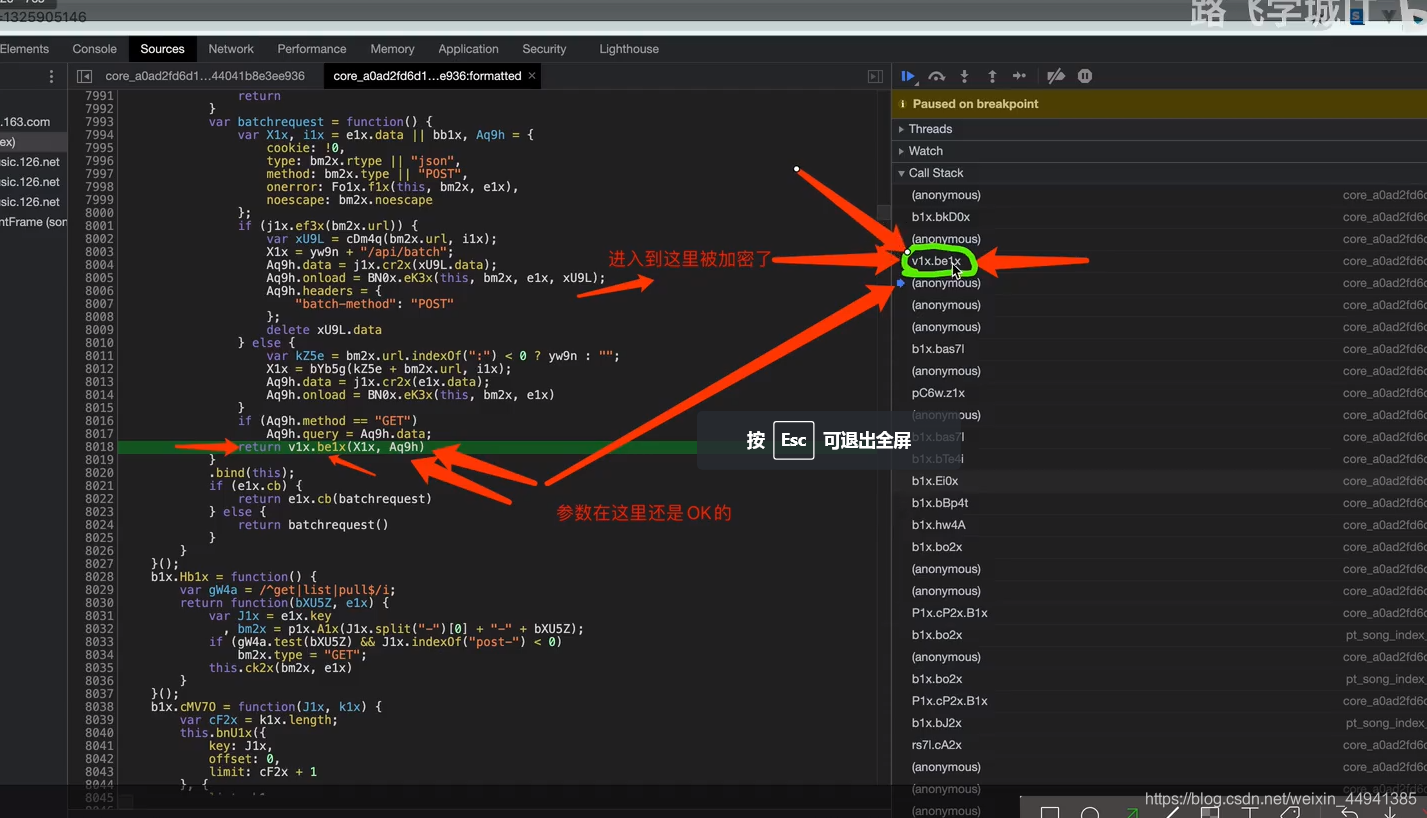
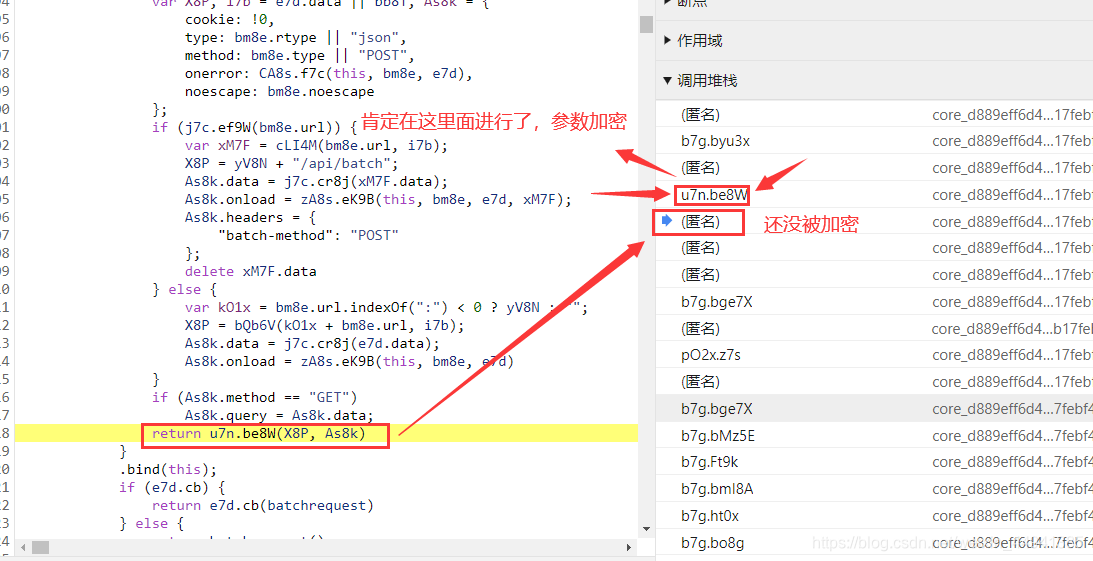
step4:
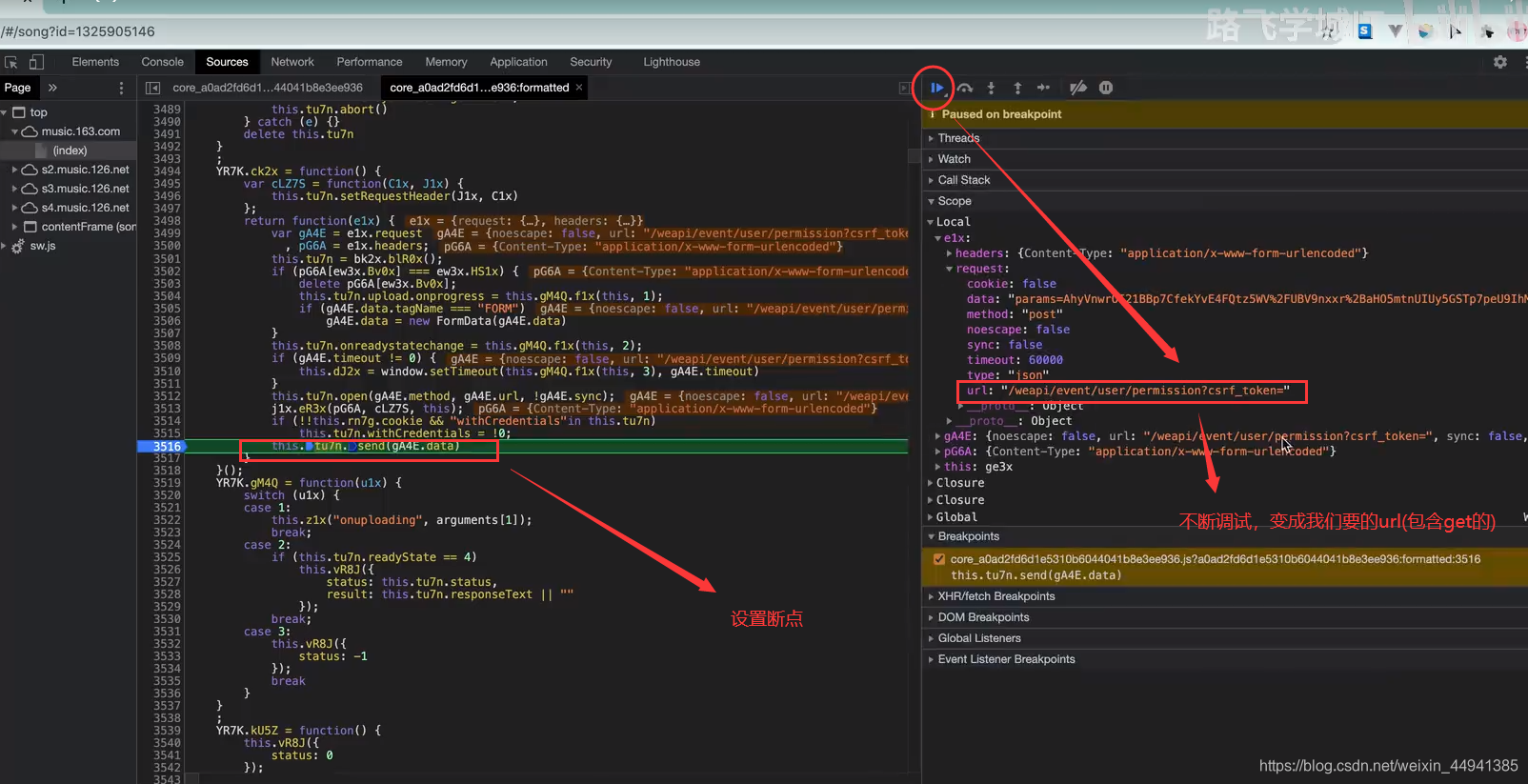
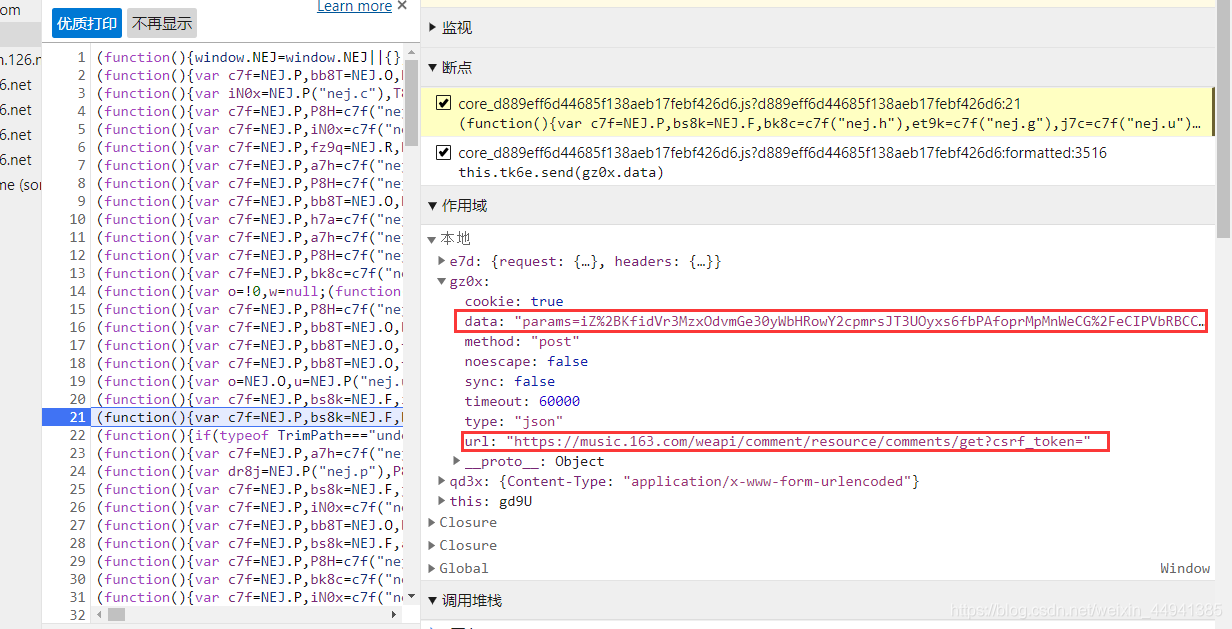
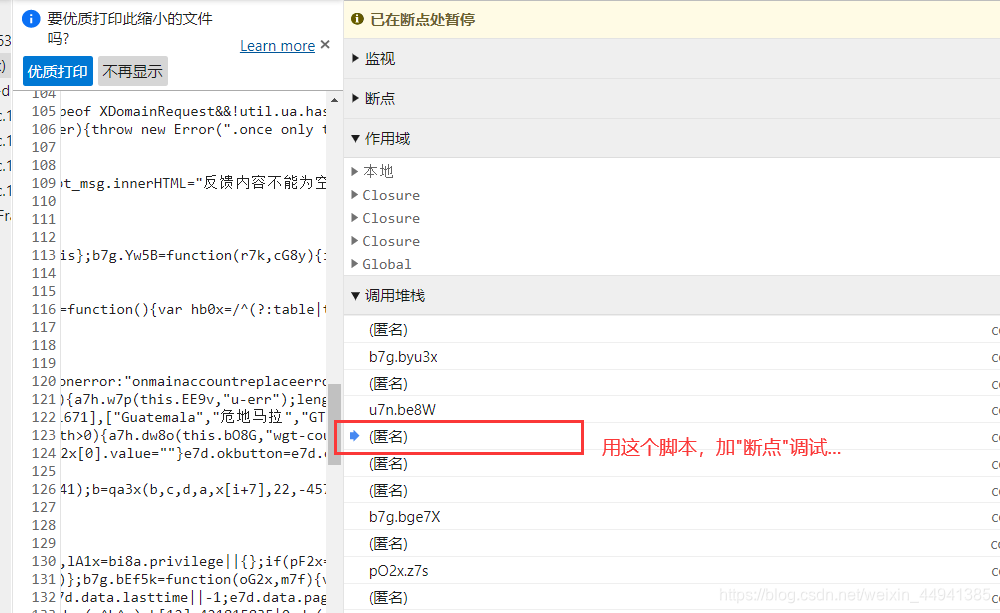
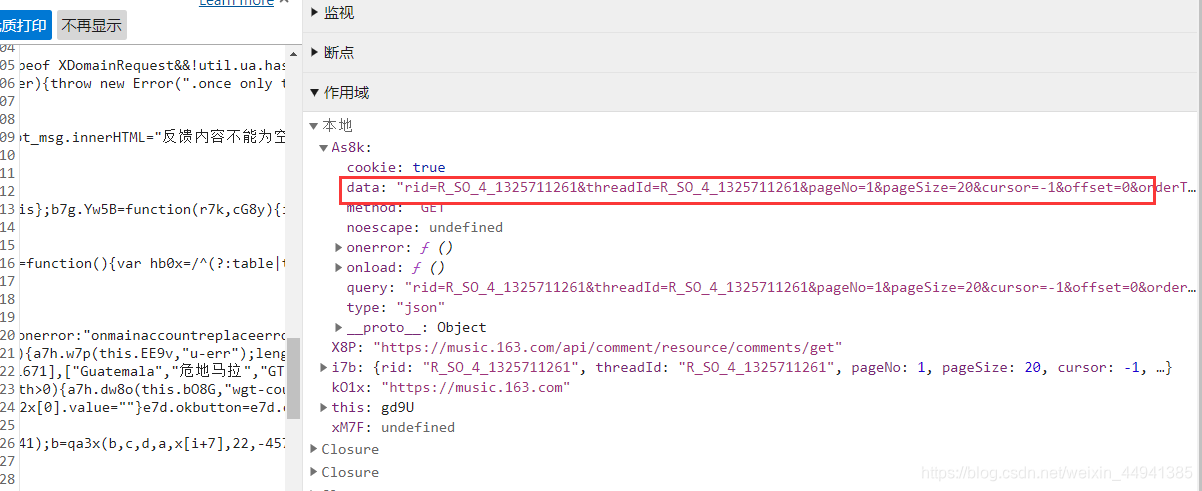
确认参数:
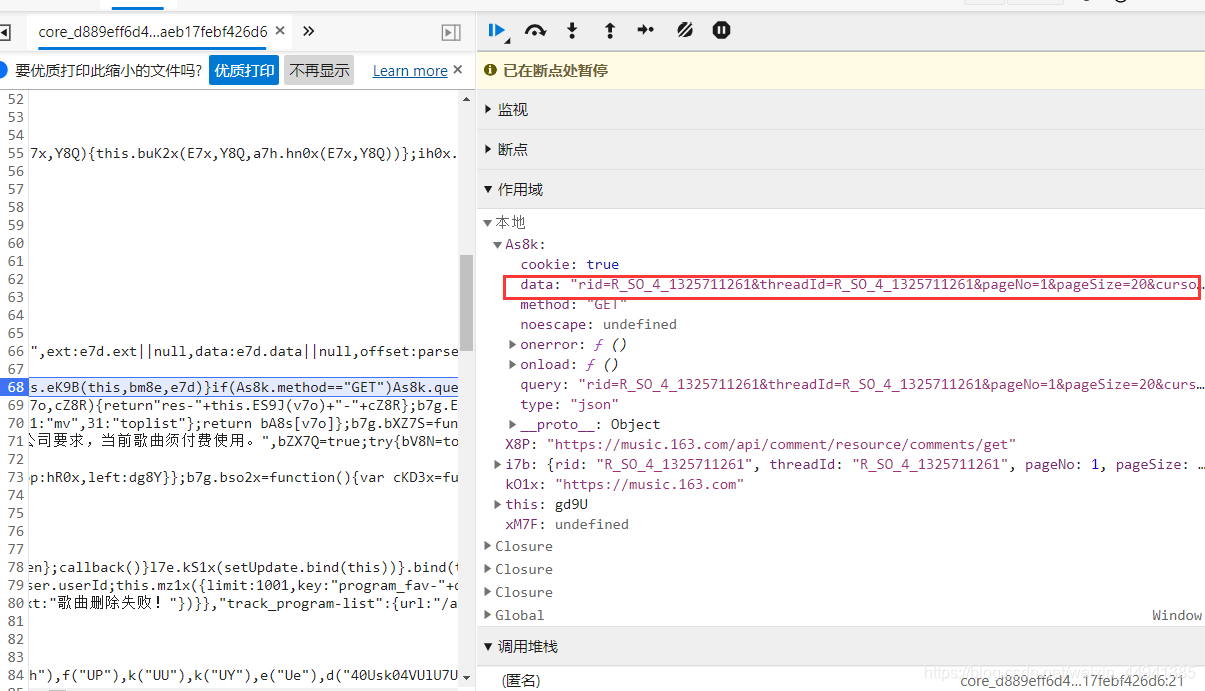
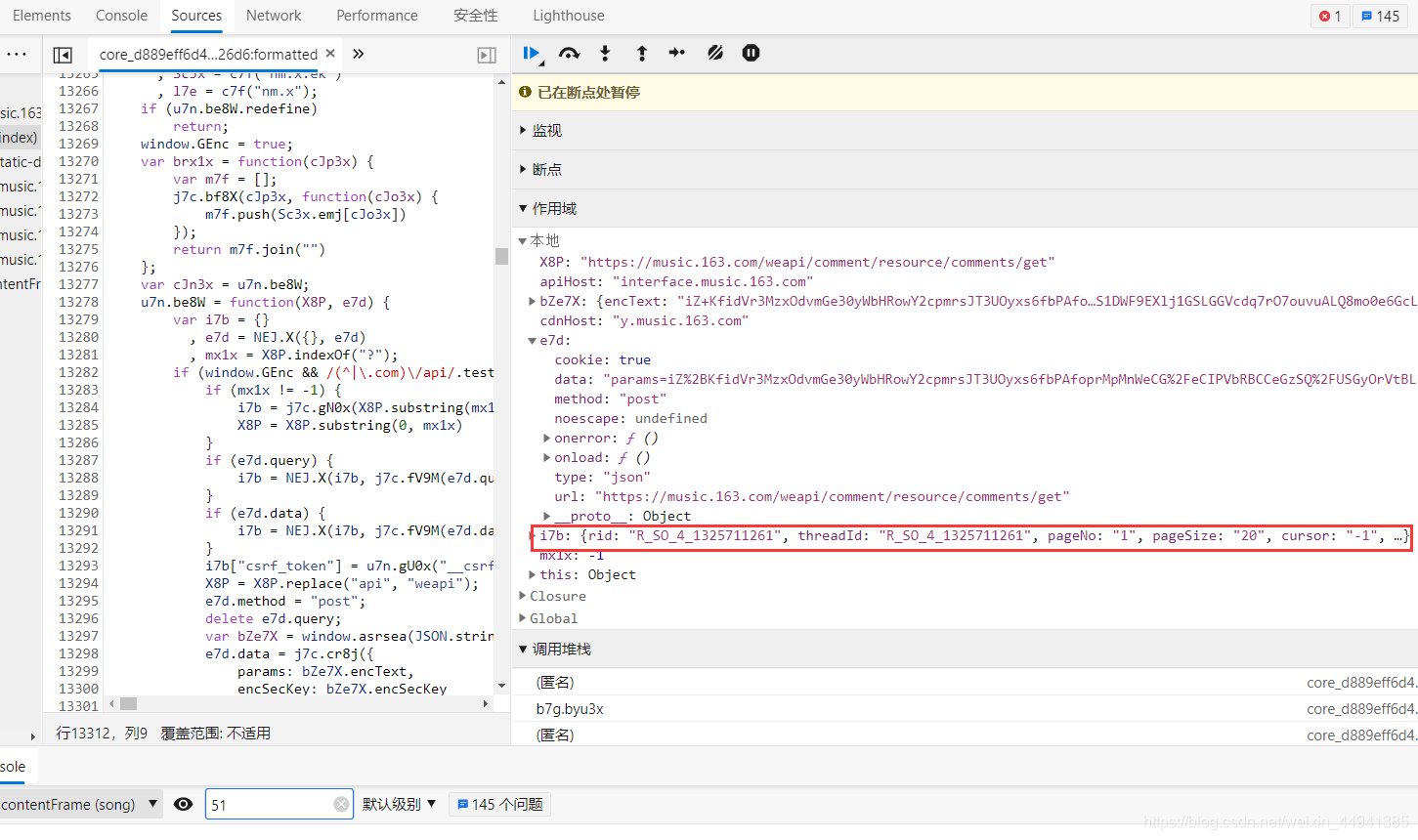
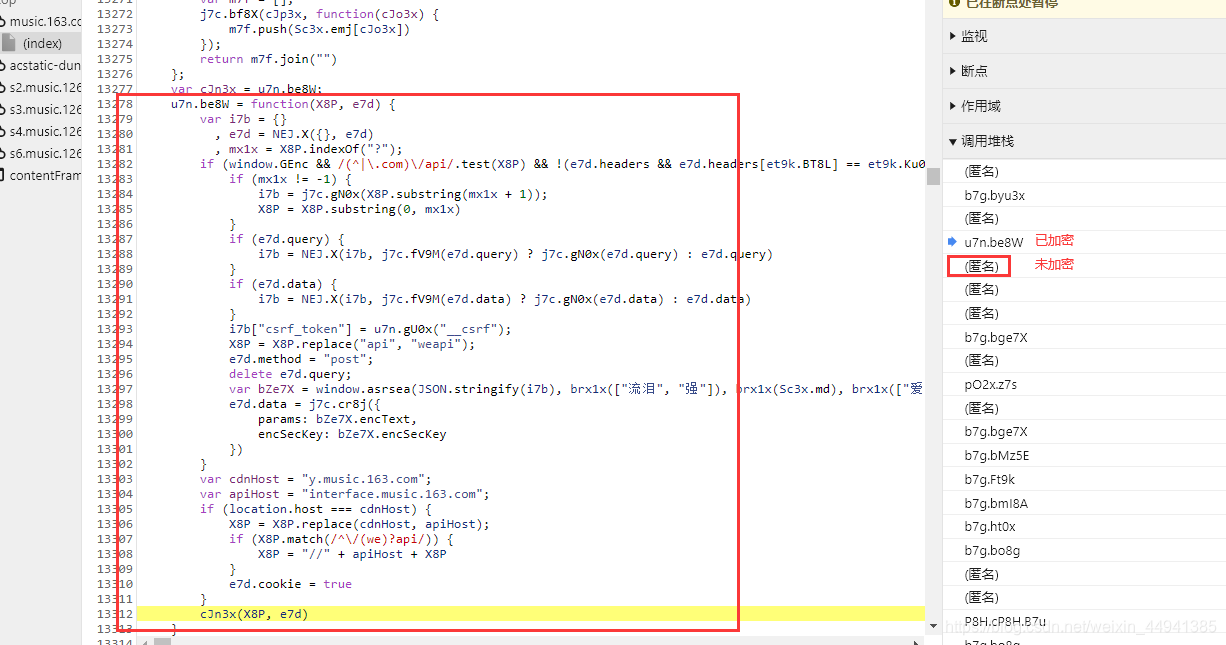
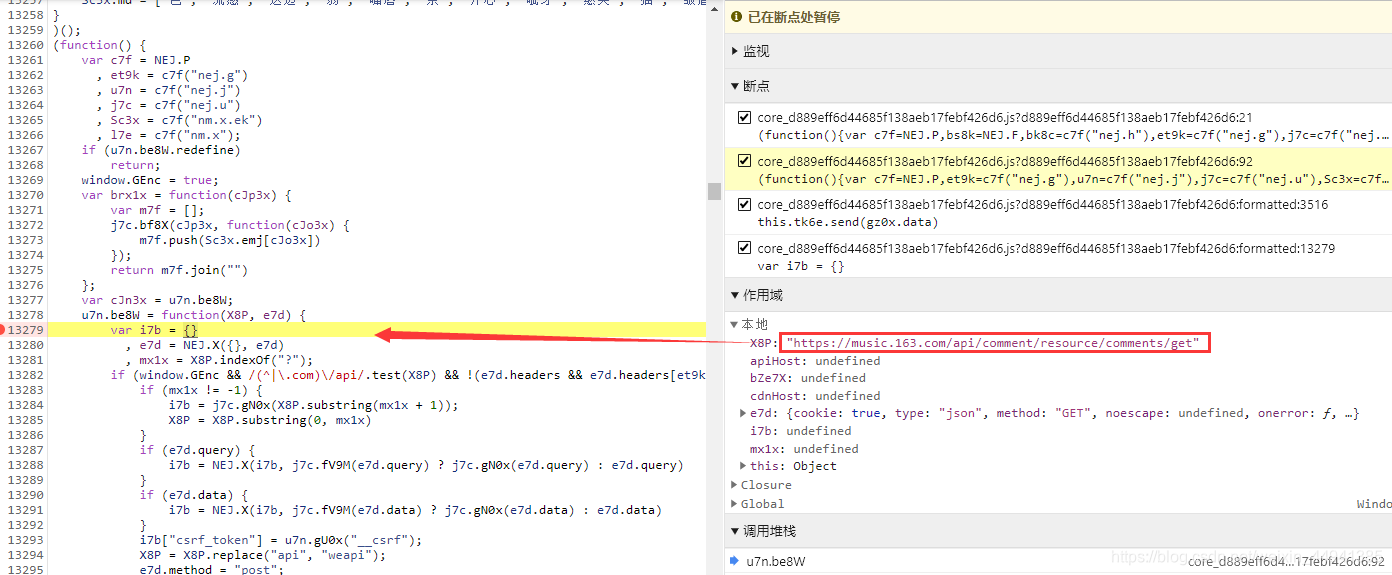
(在执行函数处加断点,调试刷到我们需要的comment_url)
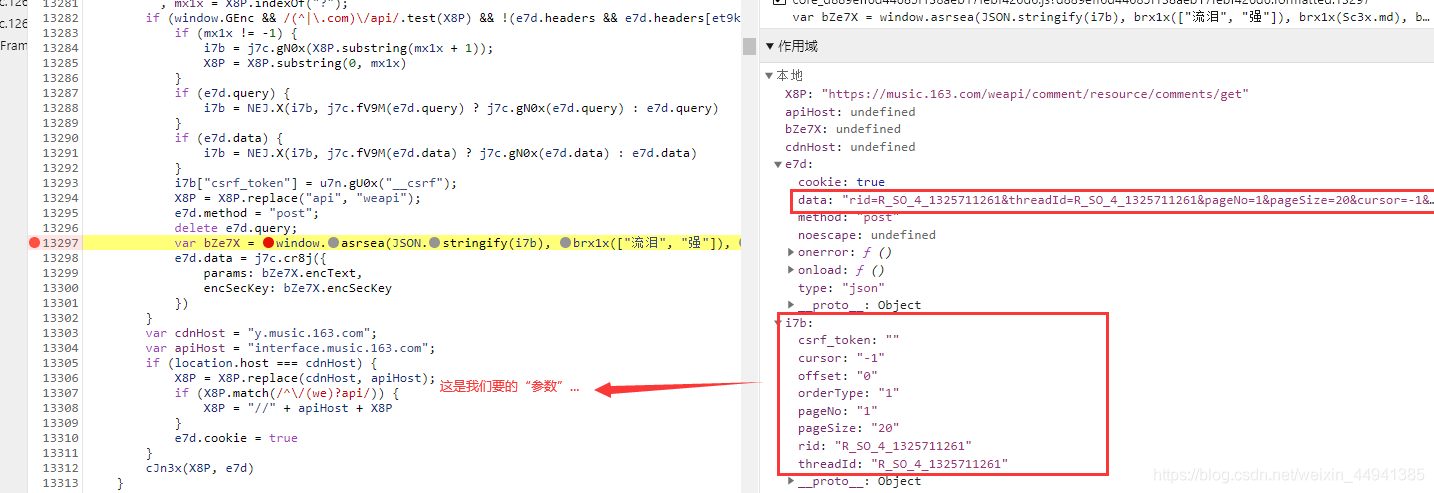
(向下执行…)
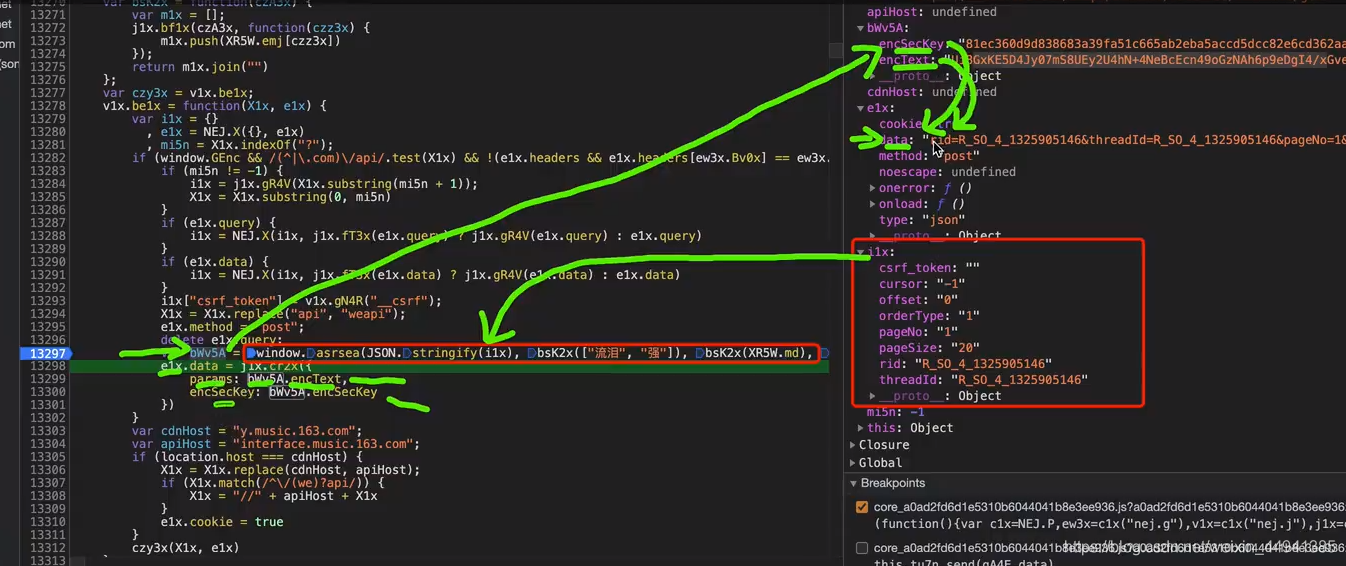
step5:
我们就知道我们的加密过程,是在window.asrsea里面完成的;
页面中搜索 >>> "ctrl + f "
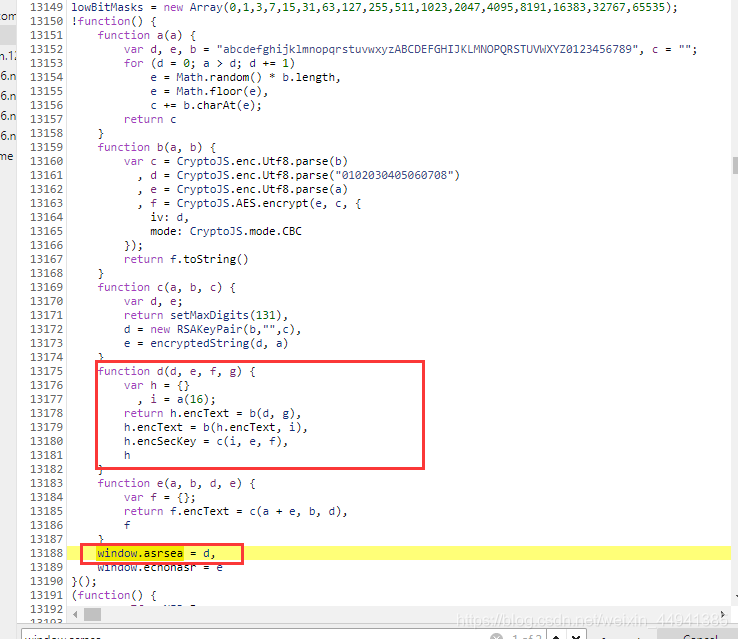
(执行的windows.asrsea,其实是在执行,d函数;)
step6:
(下面对funtion d 函数进行 “解析”)
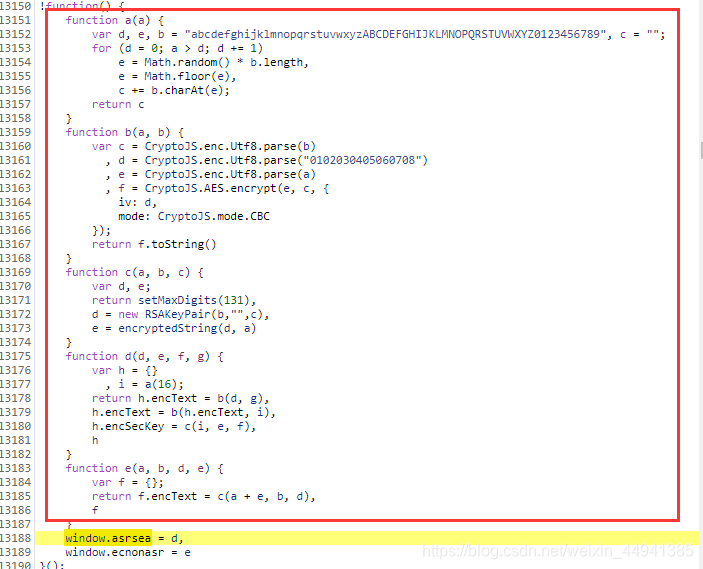
function d(d, e, f, g)
window.asrsea(JSON.stringify(i7b), brx1x(["流泪", "强"]), brx1x(Sc3x.md), brx1x(["爱心", "女孩", "惊恐", "大笑"]));
<1>d 就是数据
<2>e,在console里面执行,就是我们的 “010001”,是固定值;
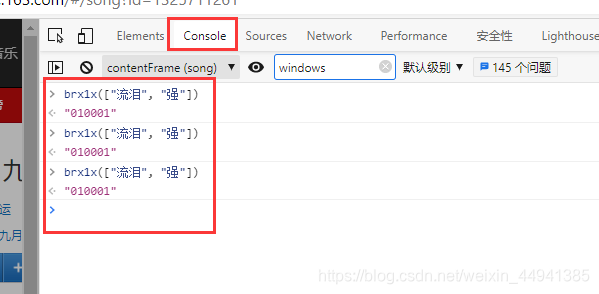
<3>f,在console里面执行,就是我们的(如下),是固定值;
00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7
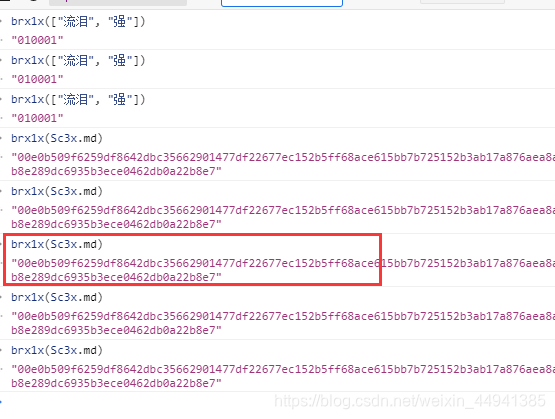
<4>g,在console里面执行,就是我们的(如下),是固定值;
0CoJUm6Qyw8W8jud

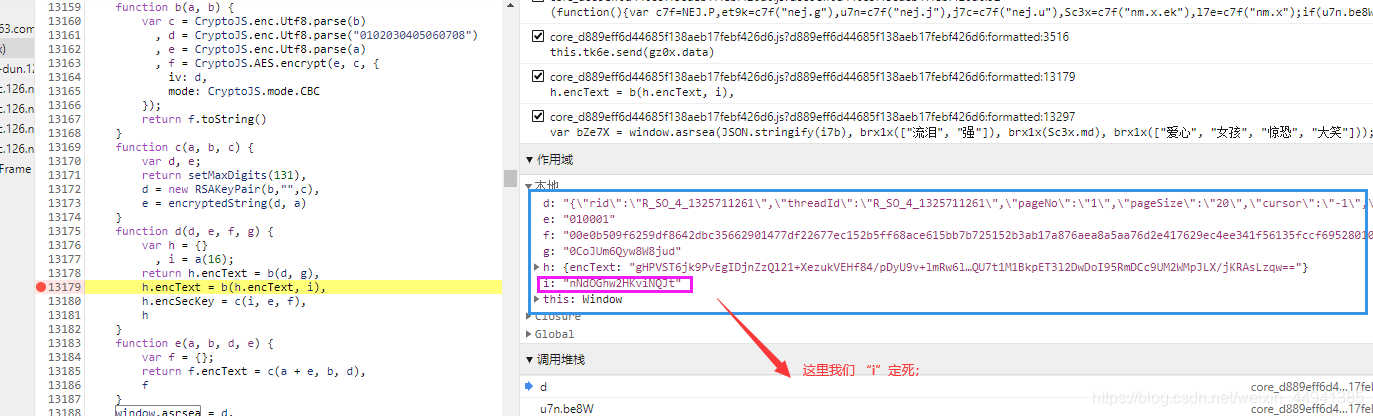
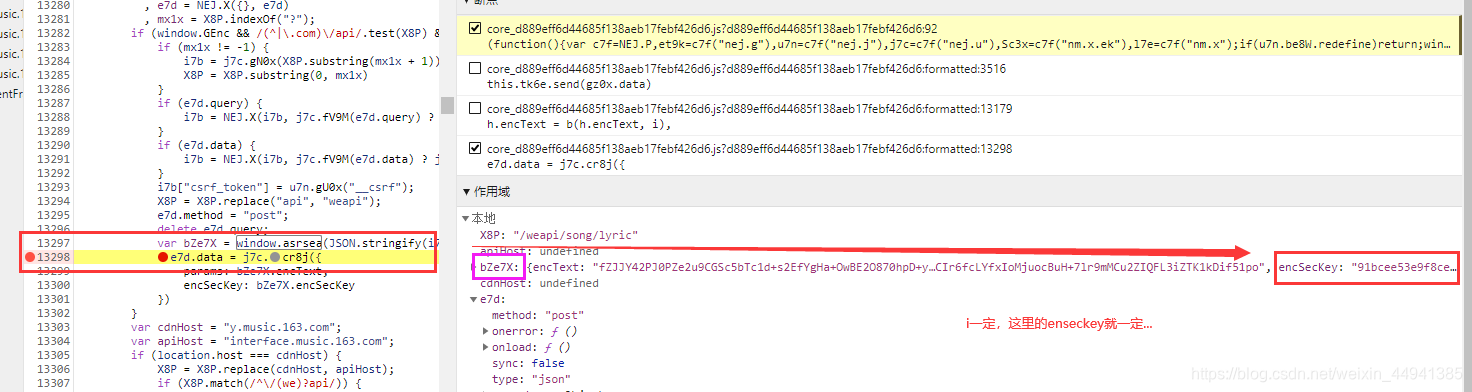
step7:
(加密过程分析…)
#1.找到未加密参数;
#2.想办法把参数进行加密(必须参考网易的逻辑),params >>> encText,encSeckey >>> encSecKey;
#3.请求到网易,拿到评论信息;
url = "https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
#请求方式POST
data = {
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_1325711261",
"threadId": "R_SO_4_1325711261"
}
f= "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46" \
"bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
i ="nNdOGhw2HKviNQJt"
e = 01001,g = "0CoJUm6Qyw8W8jud"
def get_encSecKey():# i 一定,ensekey一定;
return "91bcee53e9f8ce8ce143b35e4b8a4114081201ecb0c7a5d3ed0c4e3beade32460da9a6867edfc0b3addaaf3b39f59308ae6729494b5357c28588dd9a8b66c3be816a2df5ffe5ff4746198fd1de9d9db56595f0c91580cae5a34e8aac61e07bb99a7ad91262e0efdb15b798a599f29dce5faea2d810417d62bc349a166fcc6d48"
def get_parames(data): #默认接收到是字符串
first = enc_paramers(data,g)
second = enc_paramers(first,i)
return second
def enc_paramers(data,key):#加密过程
pass
#处理加密过程:
"""function a(a) { >>> 产生随机16位的字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1) #循环16次;
e = Math.random() * b.length, # 随机数 1.256
e = Math.floor(e), #取整 , 1
c += b.charAt(e); #去字符串中的xxx位置;取b
return c
}
function b(a, b) { # a 是要加密的内容,
var c = CryptoJS.enc.Utf8.parse(b) # c 是加密的密钥, >>> b 是加密的密钥;
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) # e 是数据
, f = CryptoJS.AES.encrypt(e, c, {
iv: d, # aes加密中的偏移量;
mode: CryptoJS.mode.CBC # 模式:cbc
});
return f.toString()
}
function c(a, b, c) { #c里面不产生随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) { d:就是数据i7b e:01001 f:很长 g : "0CoJUm6Qyw8W8jud"
var h = {} #空对象
, i = a(16); #回去看“a”,i就是一个随机的16位的随机值;tip:把i设置为定值;
h.encText = b(d, g), # g是密钥(固定的)
h.encText = b(h.encText, i), #返回的就是 params ,i也是密钥u(固定的);
h.encSecKey = c(i, e, f), #得到的就是encSecKey,e和f是定死的,如果此时我把i固定
return h
}#两此加密 data + g >>> b >>>第一次加密 >>> 第一次加密结果 + i >>> b >>> 第二次加密 >>> parames
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
"""
step8(加密过程):
(python要想用AES加密的话,需要安装 “pycrypto”)
pip install pycryptodome
#1.找到未加密参数;
#2.想办法把参数进行加密(必须参考网易的逻辑),params >>> encText,encSeckey >>> encSecKey;
#3.请求到网易,拿到评论信息;
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json
url = "https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
#请求方式POST
data = {
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_1325711261",
"threadId": "R_SO_4_1325711261"
}
f= "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
i ="KXqki4E5DWK4LKaD"
g = "0CoJUm6Qyw8W8jud"
def get_encSecKey():# i 一定,ensekey一定;
return "5cc0aa65a4494b3277714ddaf2013357017010e0a89a5352b4498b4542efda5561f232ebc32c1fbd8d53c3077d35f7b79df3c81c3ac275e54a490d2ef2de0a1fba519dc1545f551e5a4494005618bd90c6ad1b9478b4d1fda7ebd5bf396855fd7224c4abad3519a380267ea2cdc5aa5fcdc132820dce694976fdd15a5e4096c8"
def get_parames(data):
first = enc_paramers(data,g)
second = enc_paramers(first,i)
return second #返回的就是paramers
def to_16(data):
pad = 16 - len(data)%16
data += chr(pad)*pad
return data
def enc_paramers(data,key):#加密过程
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key = key.encode("utf-8"),IV=iv.encode("utf-8"),mode=AES.MODE_CBC) #创建加密器(密钥、偏移量、模式)
result = aes.encrypt(data.encode("utf-8"))#进行数据加密,加密内容的长度必须是16的倍数,“123456789abcchr(4)chr(4)chr(4)chr(4)”
# (补齐机制,你缺x个,就拿char(x)去补齐...)
#需要把加密的字节 >>> 字符串,但是“utf-8”无法识别加密之后的结果,导入一个"b64encode"
return str(b64encode(result),"utf-8")#转化为字符串返回;
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51","referer":"https://music.163.com/song?id=1325711261"}
resp = requests.post(url,data={
"params":get_parames(json.dumps(data)),
"encSecKey":get_encSecKey()
},headers =head)
print(resp.text)
#处理加密过程:
"""function a(a) { >>> 产生随机16位的字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1) #循环16次;
e = Math.random() * b.length, # 随机数 1.256
e = Math.floor(e), #取整 , 1
c += b.charAt(e); #去字符串中的xxx位置;取b
return c
}
function b(a, b) { # a 是要加密的内容,
var c = CryptoJS.enc.Utf8.parse(b) # c 是加密的密钥, >>> b 是加密的密钥;
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) # e 是数据
, f = CryptoJS.AES.encrypt(e, c, {
iv: d, # aes加密中的偏移量;
mode: CryptoJS.mode.CBC # 模式:cbc
});
return f.toString()
}
function c(a, b, c) { #c里面不产生随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) { d:就是数据i7b e:01001 f:很长 g : "0CoJUm6Qyw8W8jud"
var h = {} #空对象
, i = a(16); #回去看“a”,i就是一个随机的16位的随机值;tip:把i设置为定值;
h.encText = b(d, g), # g是密钥(固定的)
h.encText = b(h.encText, i), #返回的就是 params ,i也是密钥u(固定的);
h.encSecKey = c(i, e, f), #得到的就是encSecKey,e和f是定死的,如果此时我把i固定
return h
}#两此加密 data + g >>> b >>>第一次加密 >>> 第一次加密结果 + i >>> b >>> 第二次加密 >>> parames
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
"""
step8:(re正则筛选…)
#1.找到未加密参数;
#2.想办法把参数进行加密(必须参考网易的逻辑),params >>> encText,encSeckey >>> encSecKey;
#3.请求到网易,拿到评论信息;
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json,re
url = "https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
#请求方式POST
data = {
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_1325711261",
"threadId": "R_SO_4_1325711261"
}
f= "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
i ="KXqki4E5DWK4LKaD"
g = "0CoJUm6Qyw8W8jud"
def get_encSecKey():# i 一定,ensekey一定;
return "5cc0aa65a4494b3277714ddaf2013357017010e0a89a5352b4498b4542efda5561f232ebc32c1fbd8d53c3077d35f7b79df3c81c3ac275e54a490d2ef2de0a1fba519dc1545f551e5a4494005618bd90c6ad1b9478b4d1fda7ebd5bf396855fd7224c4abad3519a380267ea2cdc5aa5fcdc132820dce694976fdd15a5e4096c8"
def get_parames(data):
first = enc_paramers(data,g)
second = enc_paramers(first,i)
return second #返回的就是paramers
def to_16(data):
pad = 16 - len(data)%16
data += chr(pad)*pad
return data
def enc_paramers(data,key):#加密过程
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key = key.encode("utf-8"),IV=iv.encode("utf-8"),mode=AES.MODE_CBC) #创建加密器(密钥、偏移量、模式)
result = aes.encrypt(data.encode("utf-8"))#进行数据加密,加密内容的长度必须是16的倍数,“123456789abcchr(4)chr(4)chr(4)chr(4)”
# (补齐机制,你缺x个,就拿char(x)去补齐...)
#需要把加密的字节 >>> 字符串,但是“utf-8”无法识别加密之后的结果,导入一个"b64encode"
return str(b64encode(result),"utf-8")#转化为字符串返回;
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51","referer":"https://music.163.com/song?id=1325711261"}
resp = requests.post(url,data={
"params":get_parames(json.dumps(data)),
"encSecKey":get_encSecKey()
},headers =head)
#print(resp.text)
#用re提取到我们想要的数据,它不是标签语言:
#生成一个re预编译对象;
obj = re.compile('.*?"content":"(?P<content>.*?)".*? ',re.S)
contents = obj.finditer(resp.text)
for i in contents:
print(i.group("content"))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









