






注意:默认已经配置好除selenium外的相关Python环境以及Chrome浏览器
第一步:安装 selenium
pip install selenium
第二步:更新检查Chrome版本
在设置-关于Chrome中查看版本,比如125.0.6422.61
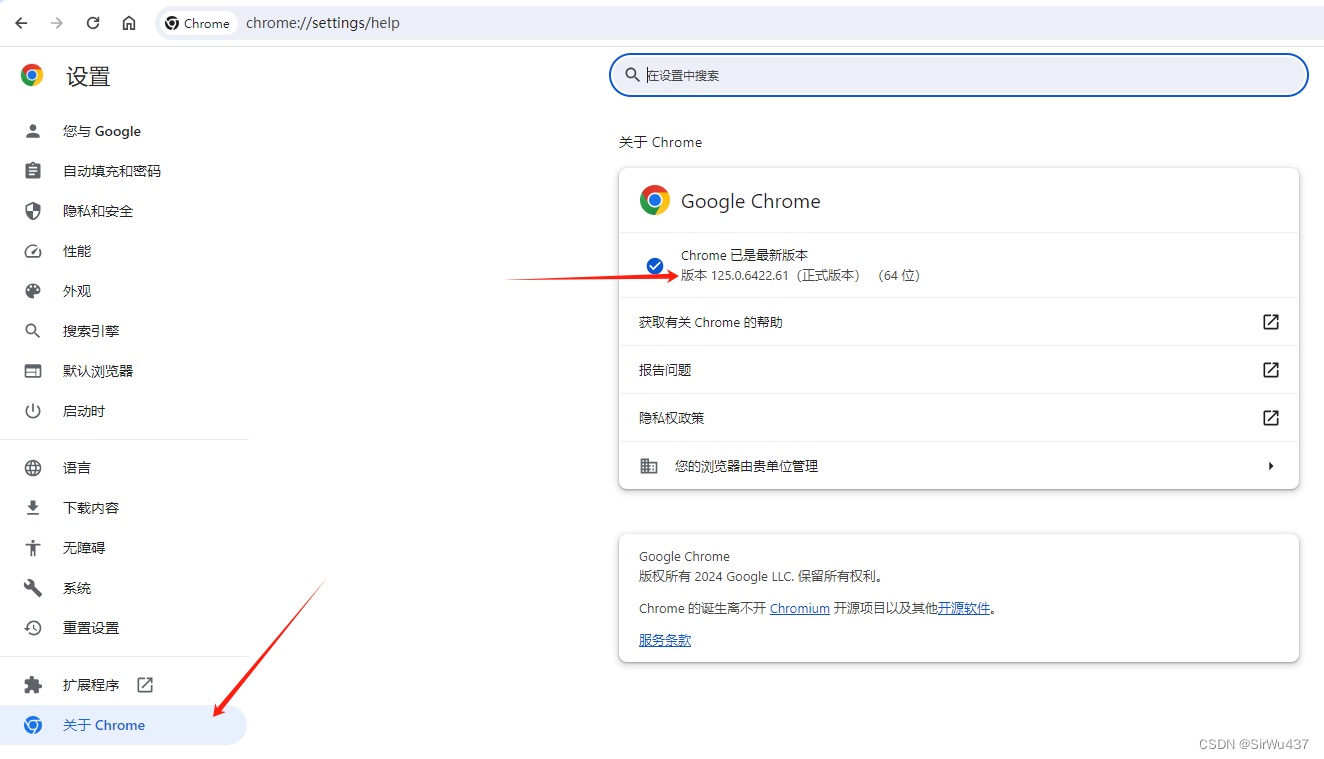
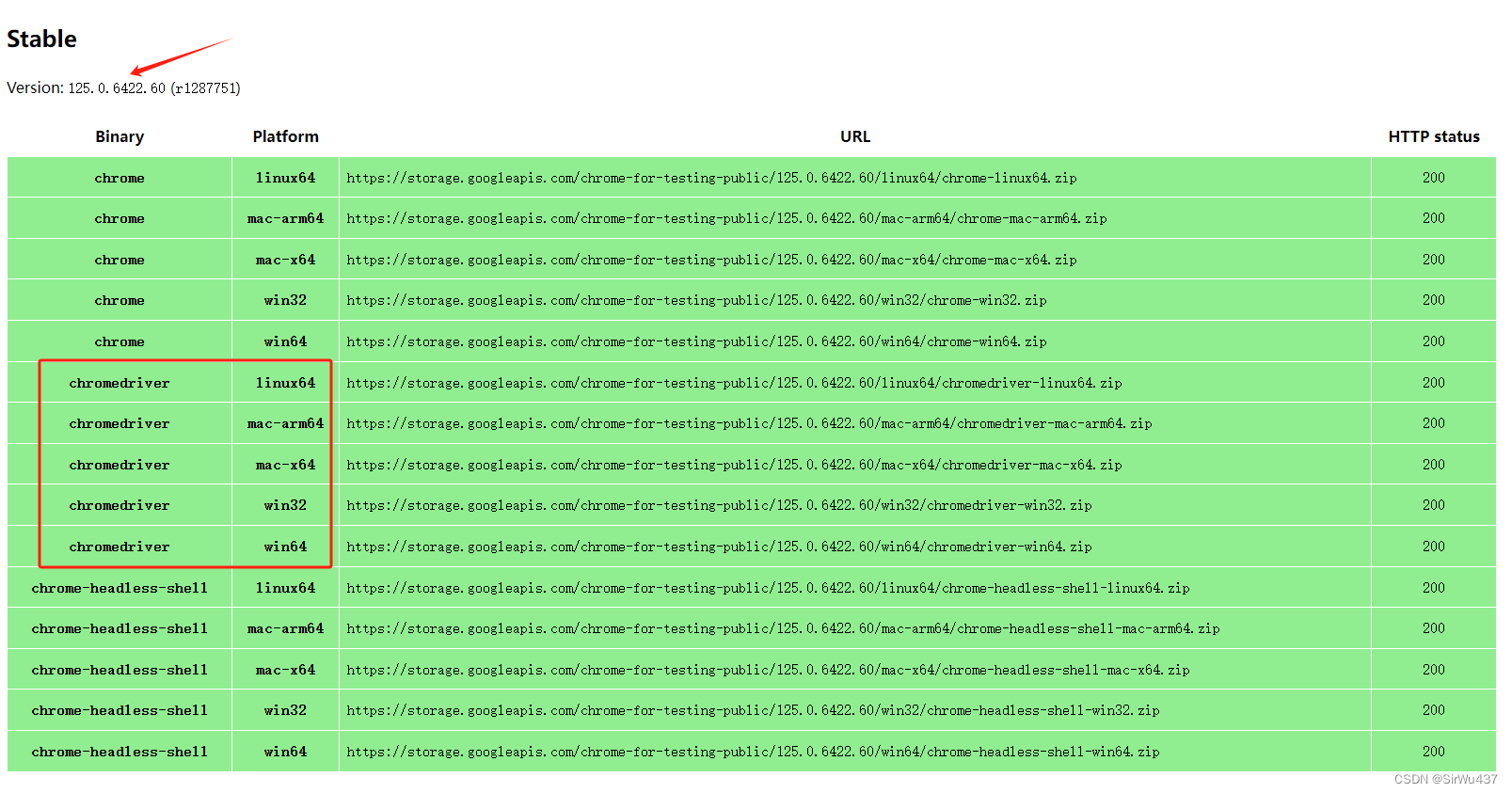
第三步:下载Chrome Driver
M114及之前Chrome版本见https://registry.npmmirror.com/binary.html?path=chromedriver/
从 M115 开始,地址移至新位置:https://googlechromelabs.github.io/chrome-for-testing/
若失效,可通过官方渠道查找:https://developer.chrome.com/docs/chromedriver?hl=zh-cn
第四步:整理需要引用的文献
将需要获取的文献题目添加到一个新建的txt文本中:(一行一篇),我新建的文件名字是:ref.txt

第五步:执行如下脚本
注意在if __name__ == "__main__":下修改成你自己的路径 driver_path,input_file_path,output_file_path
driver_path:下载的chrome driver的位置(最好别有中文)
input_file_path:输入文件路径,默认是ref.txt
output_file_path:输出文件路径,默认是ref_output.txt
Python代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from urllib import parse
import math
from time import sleep
class GG_Bibtex(object):
def __init__(self, driver_path, gg_search_url):
self.driver = None
self.paper_names = []
self.gg_search_url = gg_search_url
self.driver_path = driver_path
self.reset(driver_path)
def reset(self, driver_path):
self.service = Service(driver_path)
option = webdriver.ChromeOptions()
# option.add_argument('headless') # no show window
self.driver = webdriver.Chrome(service=self.service, options=option)
self.driver.set_window_size(800,800)
def get_bib_text(self, paper_title):
# Defines an XPath expression on the page that references a button
reference_btn_xpath = "//a[@class='gs_or_cit gs_or_btn gs_nph']"
elements_xpath = {
'qoute_btn':'/html/body/div/div[10]/div[2]/div[3]/div[2]/div/div[2]/div[5]/a[2]',
'bibtex_btn':'/html/body/div/div[4]/div/div[2]/div/div[2]/a[1]',
'bib_text':'/html/body/pre'
}
strto_pn=parse.quote(paper_title)
url = self.gg_search_url + strto_pn
self.driver.get(url)
sleep(1)
qoute_btns = self.driver.find_elements(By.XPATH, reference_btn_xpath)
if len(qoute_btns)>1: #prevents error reporting when there are multiple documents on the page
qoute_btn = qoute_btns[0]
else:
qoute_btn = WebDriverWait(self.driver, 15, 0.1).until(
EC.presence_of_element_located((By.XPATH, elements_xpath['qoute_btn']))
)
qoute_btn = qoute_btn[0] # Select the first button in the list (index 0)
qoute_btn.click()
bibtex_btn = WebDriverWait(self.driver, 15, 0.1).until(
EC.presence_of_element_located((By.XPATH, elements_xpath['bibtex_btn']))
)
bibtex_btn.click()
bib_text = WebDriverWait(self.driver, 15, 0.1).until(
EC.presence_of_element_located((By.XPATH, elements_xpath['bib_text']))
)
bib_text = bib_text.text
return bib_text
def _quit_driver(self, ):
self.driver.quit()
self.service.stop()
def results_writter(self, results, output_file_path = 'output.txt'):
wtf = []
for re_key in results.keys():
context = results[re_key]
# wtf.append(re_key + '\n')
wtf.append(context + '\n\n')
with open(output_file_path, 'w') as f:
f.writelines(wtf)
def run(self, paper_names, output_file_path, reset_len = 10):
"""
@params:
paper_names: [LIST], your paper names.
reset_len: [INT], for avoid the robot checking, you need to reset the driver for more times, default is 10 papers
"""
self.paper_names = paper_names
paper_len = len(paper_names)
rest = paper_len % reset_len
task_packs = []
if paper_len > reset_len:
groups_len = int(math.floor(paper_len / reset_len))
for i in range(groups_len):
sub_names = paper_names[(i)*reset_len:(i+1)*reset_len]
task_packs.append(sub_names)
task_packs.append(paper_names[-1*rest:])
results = {}
for ti in task_packs:
for pn in ti:
if len(pn) < 3:
continue
print('\n---> Searching paper: {} ---> \n'.format(pn))
bibtex = self.get_bib_text(pn)
print(bibtex)
results[pn] = bibtex
self._quit_driver()
sleep(1)
self.reset(self.driver_path)
print('-'*10+'\n Reset for avoiding robot check')
self.results_writter(results, output_file_path)
return results
if __name__ == "__main__":
driver_path = r"D:/Documents/chromedriver-win64/chromedriver.exe"
""
input_file_path = 'ref.txt'
output_file_path = 'ref_output.txt'
gg_search_url = r'https://scholar.google.com.hk/scholar?hl=zh-CN&as_sdt=0%2C5&q='
ggb = GG_Bibtex(driver_path = driver_path, gg_search_url = gg_search_url)
paper_names = []
with open(input_file_path, 'r') as f:
paper_names = f.readlines()
paper_names = [pn.replace('\n', '') for pn in paper_names]
results = ggb.run(paper_names = paper_names, output_file_path = output_file_path)
输出结果修改一下后缀名,就能直接作为bib文件使用。
注:本文继承自2023最新 - 谷歌学术文献Bibtex批量获取脚本,本文基于最新进展及使用体验稍加改良,感谢原作者。
















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











