







第一步 :分析数据,对数据进行处理(合并训练集和测试集一起处理)
- 1.去除重复值 data.drop_duplicates(inplace=True)
- 2.缺失值处理(平均数等、随机森林填补、删掉缺失值(一般不怎用,除非数很少))
- 3.把字符串转变成数值型
- (可选可不选)4.二值化,分段(分箱,连续型变量)
二、数据预处理常用到的
# 查看数据详情
test=pd.read_csv('test.csv')
train=pd.read_csv('train.csv')
train = pd.read_csv("train.csv", index_col=0,encoding='utf-8')
train.info()
train.shape
train.head()
#描述
train.describe()
# 去重复值
train.drop_duplicates(inplace=True) #inplace=True是直接对原dataFrame进行操作
# s = t.drop_duplicates(inplace=False) 则,t的内容不发生改变,s的内容是去除重复后的内容
#恢复索引
train.index=range(train.shape[0])
# 合并训练集和测试集
data = pd.concat([train, test])
#提取特征(或者选取某一列)
y=df.iloc[:,-1]
#这一列中没有nan的所有行都提取出来
data[data['loan_default'].notnull()]
#这一列中是nan的所有行都提取出来
data[data['loan_default'].isnull()
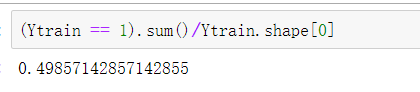
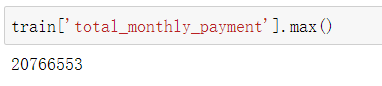
1.查看某一数占总数的比例 和 某一列最大数
某一列最大数
2.查看里面的类别

3.删除两列

5.提取两行


4.pd.cut()和pd.qcut() 分箱
pd.cut() 将指定序列 x,按指定数量等间距的划分(根据值本身而不是这些值的频率选择均匀分布的bins),或按照指定间距划分
pd.qcut() 将指定序列 x,划分为 q 个区间,使落在每个区间的记录数一致
[In] ll = [1,2,3,5,3,4,1, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









