







现实世界的嵌入数据集通常包含隐藏在向量空间中的冗余。例如,当向量聚集在多维空间中的某些中心点周围时,它会揭示一个可利用的结构。通过减少这种冗余,我们可以在对精度影响最小的情况下节省内存和性能。自 0.7.0 版以来,pgvector 中引入了几种利用这一想法的方法:
- float16 向量表示
- 稀疏向量
- 位向量
Float16向量
当 HNSW 索引适合共享内存并避免因并发操作而被逐出时,其效率最高,Postgres 执行此操作以最大限度地减少昂贵的 I/O 操作。从历史上看,pgvector 仅支持 32 位向量。在 0.7.0 版本中,pgvector 引入了 16 位浮点 HNSW 索引,其占用的内存恰好是原来的一半。内存的减少使操作保持最佳性能,并且时间延长了一倍。
使用 float16 向量时有两个选项:
- 索引使用 float16,但底层表继续使用 float32
- 索引和底层表都使用 float16。此选项占用 50% 的磁盘空间,并且需要的共享内存减少 50% 才能高效运行。由于单个 Postgres 页面中可以容纳更多向量,并且并发操作导致的页面驱逐更少,因此性能得到进一步提升。
要将现有的 float32 嵌入表复制到 float16 嵌入表:
create table embedding_half (
id serial,
vector halfvec(1536),
primary key (id)
);
insert into embedding_half (vector)
select
vector::halfvec(1536)
from
embedding_full;
对于 900K OpenAI 1536 维向量,表大小为 3.5Gb。相比之下,embedding_full需要 7Gb。
然后我们可以构建一个 float16 HNSW 索引:
create index on embedding_half using hnsw (vector halfvec_l2_ops);
为了测试索引创建的性能,我们选择了c7g.metal128Gb内存的实例,其参数如下:
shared_buffers = 50000MB
maintenance_work_mem = 30000MB
max_parallel_maintenance_workers = {0-63}
wal_level=minimal
max_wal_size = 10GB
autovacuum = off
full_page_writes = off
fsync = off
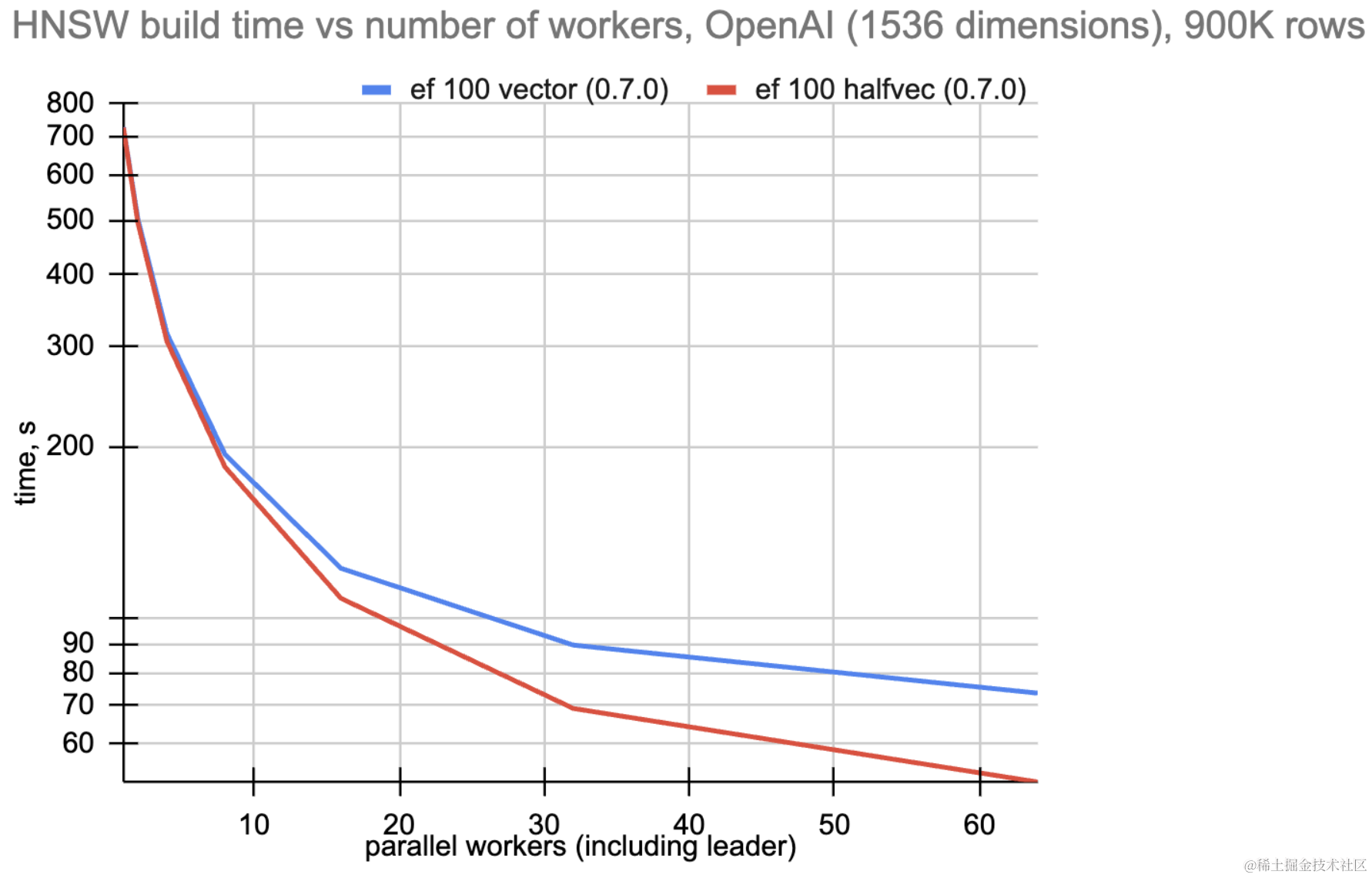
HNSW 构建时间在 0.6.2 版本中经历了逐步改善,引入了并行构建。具有 halfvec(float16)功能的 0.7.0 版本将速度进一步提高了 30%。
请注意,ARM 架构上的 float16 向量算法与 float32 相同,因此串行构建时间(使用一个并行工作器)没有改善。但是,由于页面和 I/O 利用率更高,并行构建存在显著差异。另请注意,此测试不使用预热或其他人工增强功能。
与之前的 float32 相比,float16 的堆和 HNSW 关系仅占用一半的空间。
有一项提案建议在将来通过在 ARM 架构上使用 SVE 内部函数来进一步加快速度(参见:https://github.com/pgvector/pgvector/pull/536)。
Jonathan Katz使用 (64 vCPU、512GiB RAM) 对 HNSW 性能进行了测量r7gd.16xlarge,结果甚至更好。对于 float16,HNSW 构建时间最多快 3 倍。对于 select 的性能,ANN 基准测试结果表明,精度不会随着位数的降低而改变,并且每秒查询数 (QPS) 与内存中的情况相似。但是,当实际机器查询使用 I/O 或由于并发连接导致某些 HNSW 页面从内存中被逐出时,就会出现明显的差异。只需要一半的内存即可容纳相同的 HNSW 索引,相同性能和精度的成本也显著降低。
| 矢量/矢量 | 向量/HalfVec | |
|---|---|---|
| 索引大小 (MB) | 7734 | 3867 |
| 索引建立时间(秒) | 264 | 90 |
| 回想一下@ef_search=10 | 0.819 | 0.809 |
| QPS @ ef_search=10 | 1231 | 1219 |
| 回想一下@ef_search=40 | 0.945 | 0.945 |
| QPS @ ef_search=40 | 627 | 642 |
| 回想一下@ef_search=200 | 0.987 | 0.987 |
| QPS @ ef_search=200 | 191 | 190 |
有关不同数据集的完整结果,请参阅此 GitHub 问题。
稀疏向量
如果向量包含许多零分量,则稀疏向量表示可以节省大量存储空间。例如,要填充稀疏向量:
create embedding_sparse (
id serial,
vector sparsevec(1536),
primary key (id)
)
insert into embedding_sparse (embedding) values ('{1:0.1,3:0.2,5:0.3}/1536'), ('{1:0.4,3:0.5,5:0.6}/1536');
稀疏向量仅占用非零分量的存储空间。在本例中,1536 个向量中有 3 个值。
请注意稀疏向量表示的新向量语法{1:3,3:1,5:2}/1536:
select * from embedding_sparse order by vector <-> '{1:3,3:1,5:2}/1536' limit 5;
位向量
使用二进制量化,我们可以将浮点向量表示为二进制空间中的向量。这大大减少了存储大小,旨在作为一种在子集内执行额外搜索之前快速从数据集中“预选”的方法。如果参数化得当,即使没有索引,二次选择也可以非常快。
create index on embedding
using hnsw ((binary_quantize(vector)::bit(1000)) bit_hamming_ops);
select
*
from
embedding
order by
binary_quantize(vector)::bit(3) <~> binary_quantize('[1,-2,3]')
limit 5;
要使用二进制量化 HNSW 索引从更大的数据集中预先选择,然后从结果子集中进行快速选择,无需索引:
select * from (
select
*
from
embedding
order by
binary_quantize(vector)::bit(3) <~> binary_quantize('[1,-2,3]')
limit 20
)
order by
vector <=> '[1,-2,3]'
limit 5;
它允许为选择、插入或更新操作构建小型且快速的 HNSW 索引,同时仍具有快速向量搜索。子句的确切配置limit取决于数据,因此您需要直接在自己的数据集上试验子选择的大小和最终结果的数量。
新的距离[函数]
pgvector 0.7.0 还增加了对 L1 距离算子的支持<+>。
以及用于索引的新距离类型:
L1 distance- 在 0.7.0 版中添加
create index on items using hnsw (embedding vector_l1_ops);
Hamming distance- 在 0.7.0 版中添加
create index on items using hnsw (embedding bit_hamming_ops);
Jaccard distance 在 0.7.0 版中添加
create index on vector using hnsw (vector bit_jaccard_ops);
结论
在过去的一年里,pgvector 在功能和性能方面都有了显著的发展,包括 HNSW 索引、并行构建和许多其他选项。随着半向量 (float16)、稀疏向量和位向量的引入,我们现在看到的速度比一年前提高了 100 倍以上。
要更全面地比较去年 pgvector 的性能,请查看Jonathan Katz 的这篇文章。
在 MemFire Cloud 中使用[v0.7.0]
所有新项目都附带 pgvector v0.7.0(或更高版本)。如果尚未启用扩展,请务必启用它:
create extension if not exists vector
with
schema extensions;
如果您不确定项目使用的是哪个版本的 pgvector,请在MemFire Cloud扩展页面vector上搜索。















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









