







Selenium爬虫——part1
因为毕业项目data collection的需要,6月份的时候使用python的selenium包进行了一些爬虫,主要专注于3个网站,难度不高,但也颇有收获,在此进行总结以便以后的进步。
(6月底结束之后一直要来总结,但由于重度拖延症…眼看今年就要结束,一定要爬起来把这篇总结敲完)
1. Selenium 介绍
先贴一个selenium的官方文档:
https://selenium-python.readthedocs.io/installation.html
以下是百度中Selenium的基本介绍:
“Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。”
而对于爬虫来说,相比于其他的包,Selenium不仅可以爬取动态网站,其最大的好处就是可以像真正的用户在操作一样,进行点击,滑动,甚至输入用户名密码等操作,并且可以实时看到它的操作,为工作带来了很大的便捷性。下面对于selenium的使用进行简单的介绍:
2. 安装chromedriver
我们此处运用google chrome作为浏览器,使用之前我们需要下载chromedriver。
第一步:查看google chrome的版本(因为google是自动更新的,而chromedriver的版本必须与浏览器的一样才可以进行后续操作)


第二步:在https://chromedriver.chromium.org/downloads中下载对应版本和对应电脑系统的chromedriver即可。
第三步:将下载好的文件解压到一个路径下,这个路径需要记住,在以后的爬虫中都会用到。
3. 使用流程&常用函数
先下载selenium: pip install selenium
再获取网页:
from selenium import webdriver
driver_path = r'C:\chromedriver.exe' #the path of 'chromedriver.exe'
driver = webdriver.Chrome(driver_path)
page_to_scrap = 'https://www.baidu.com'
driver.get(page_to_scrap)
需要注意的是这里driver_path就是我们之前下载的chromedriver.exe的路径,而page_to_scrap是我们要爬取的网址,此处以百度为例。
如果运行成功,电脑会弹出一个新的窗口打开我们要爬取的网址,就像一个人在操作一样。
现在我们就可以利用selenium中的函数获取网页中需要的内容。介绍selenium的常用函数之前,我们先来简单看一下网页结构。在想要获取的内容处右击鼠标,选择“检查”,可以看到网页的代码类似这样:

这个源码看起来比较复杂,但我们不用理会,只需要注重其中一些点就好。
其中紫色的字符,比如div, a, 我们称作tag; 橙色的字符,比如class, href, 我们称作attribute, 而class = 后的字符串我们称为class name, 类似的,id = 后的字符串称为id name。
像“喜迎冰雪盛会 一起向未来”这样黑色的字符称为text,如果我们要获取这一段text, 可以查看它的所属结构,前面有个class叫做“undertips-link-text”,Ctrl+F5搜索这个 class name: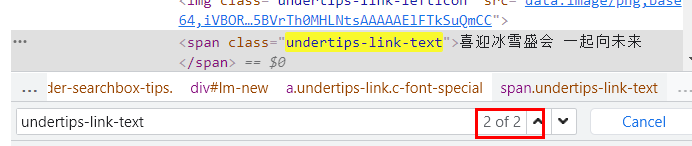
得知虽然有两处,但作为class name存在的只有这一处,这是唯一的标识,所以我们就可以通过这个class name找到这一段text:
driver.find_element_by_class_name('undertips-link-text').text
# Output: '喜迎冰雪盛会 一起向未来'
当然不是class name是唯一的才可以,若有多个同样的class name,find_element_by_class_name()找出的是一个list, 选出对应的那一部分就好。除此之外, 还有很多其他的函数可以让我们更快捷地定位我们想查找的内容。
内容定位常用函数:
| 函数 | 含义 |
|---|---|
| find_element_by_id(element_id) | 通过Id查找元素 |
| find_element_by_name(element_name) | 通过name查找元素 |
| find_element_by_xpath(xpath)* | 通过Xpath查找元素 |
| find_element_by_tag_name(tag_name) | 通过tag name查找元素 |
*通过Xpath定位是比较直接准确的方法,例子:driver.find_element_by_xpath("//div[@id=‘menuContainer’]/div/div/ul/li[4]/a")
更多的定位方法可以进入官方文档的Locating Elements一章中查看。
我们前面找到的’喜迎冰雪盛会 一起向未来’这一段文字是一个超链接,所以找到这一段文字后,我们还可以通过selenium去点击,进入一个新的网页:
driver.find_element_by_class_name('undertips-link-text').click()

在selenium控制的浏览器中,可以看到一个新的网页被打开,在同一窗口的第二个标签。还可以设置这个窗口的最大标签页数,或关闭其中一个或多个标签页。这样类似让selenium可以像人一样去操作网页的函数还有很多。
网页操作常用函数:
| 函数 | 操作 |
|---|---|
| driver.switch_to_window(driver.window_handles[1]) | 切换到新窗口 |
| sel1=driver.find_element_by_id();Select(sel1).select_by_value(“1”) | 下拉列表选择 |
| driver.find_element_by_id(“form1”).submit() | 表单的提交 |
更多的网页操作相关函数可以进入官网文档查看。
4. 实际应用
学习了selenium的基本操作后,就可以利用它进行一些数据的爬取,让selenium成为自己的手下工作起来 ^_^

后面对于几个我们熟悉的网站进行数据爬取,也记录了一些常见的问题,比如验证码的拦截等,请持续关注后续文章。















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









