










总结:
对agg而言,会计算得到A,B,C公司对应的均值并直接返回,但对transform而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果;
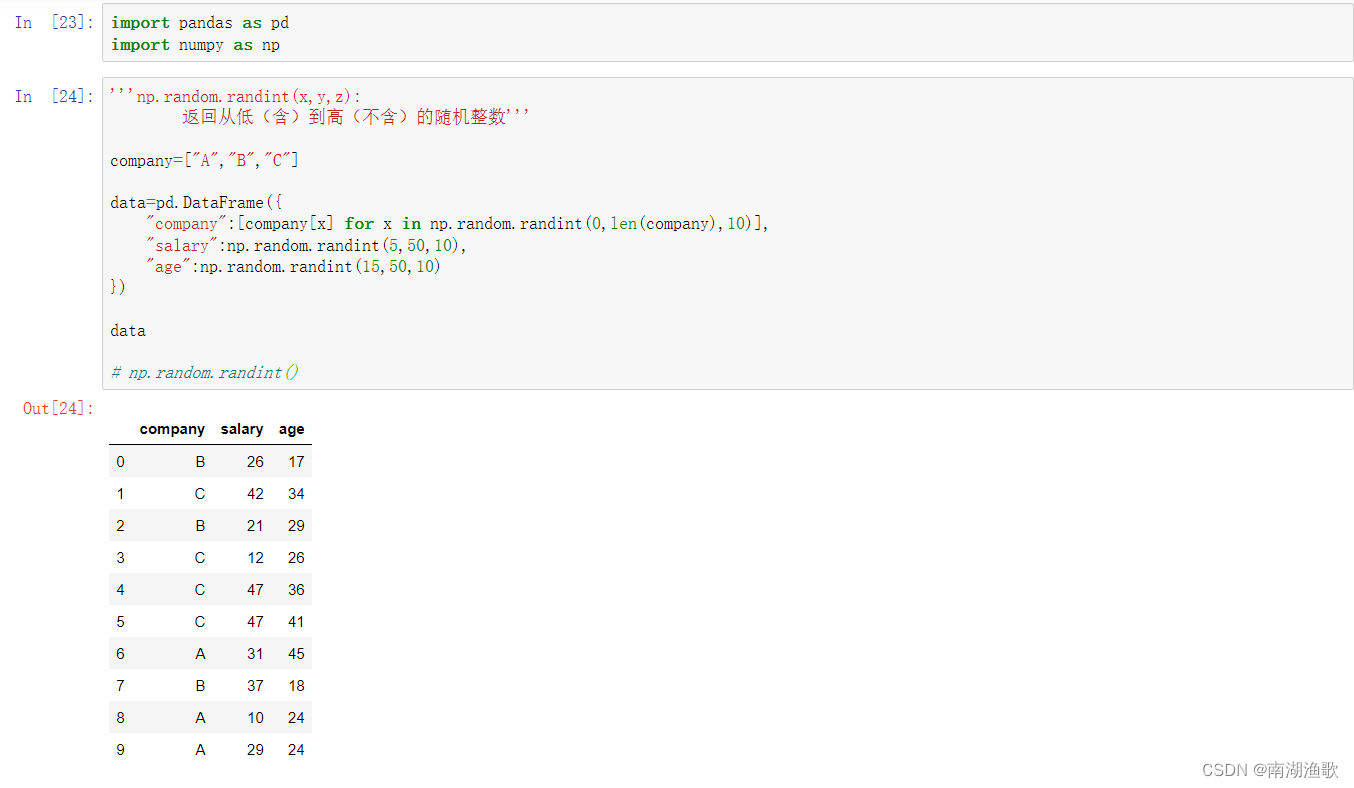
import pandas as pd
import numpy as np
'''np.random.randint(x,y,z):
返回从低(含)到高(不含)的随机整数'''
company=["A","B","C"]
data=pd.DataFrame({
"company":[company[x] for x in np.random.randint(0,len(company),10)],
"salary":np.random.randint(5,50,10),
"age":np.random.randint(15,50,10)
})
data
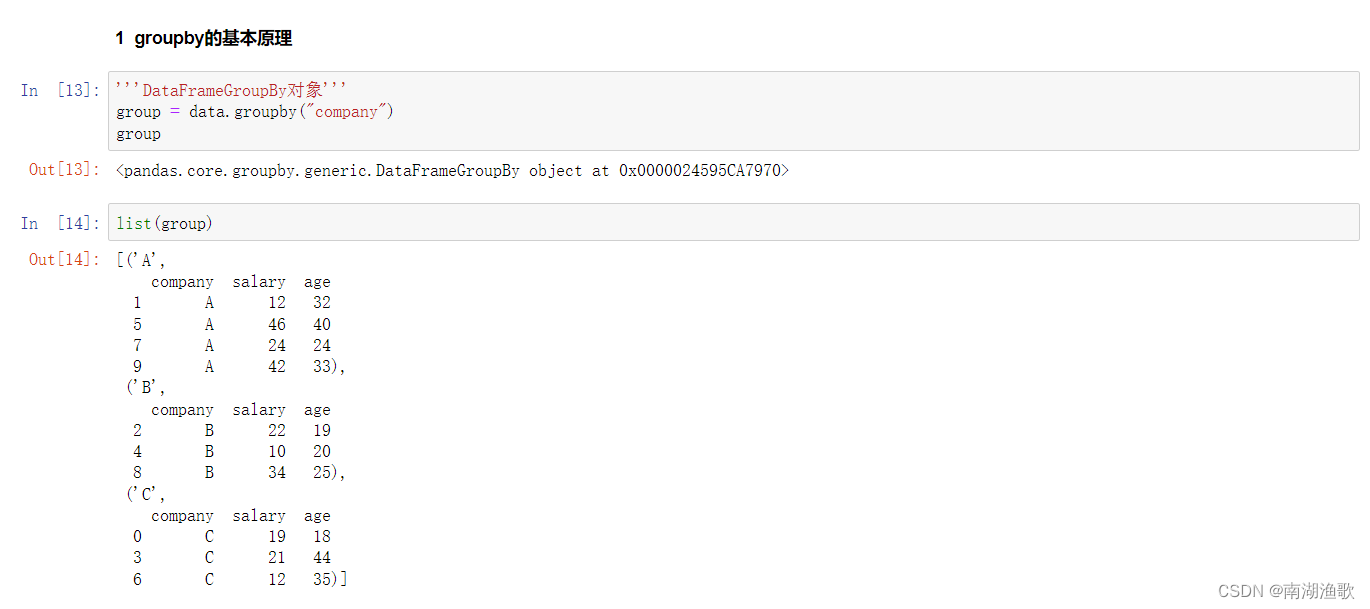
#### groupby的基本原理
'''DataFrameGroupBy对象'''
group = data.groupby("company")
group
list(group)
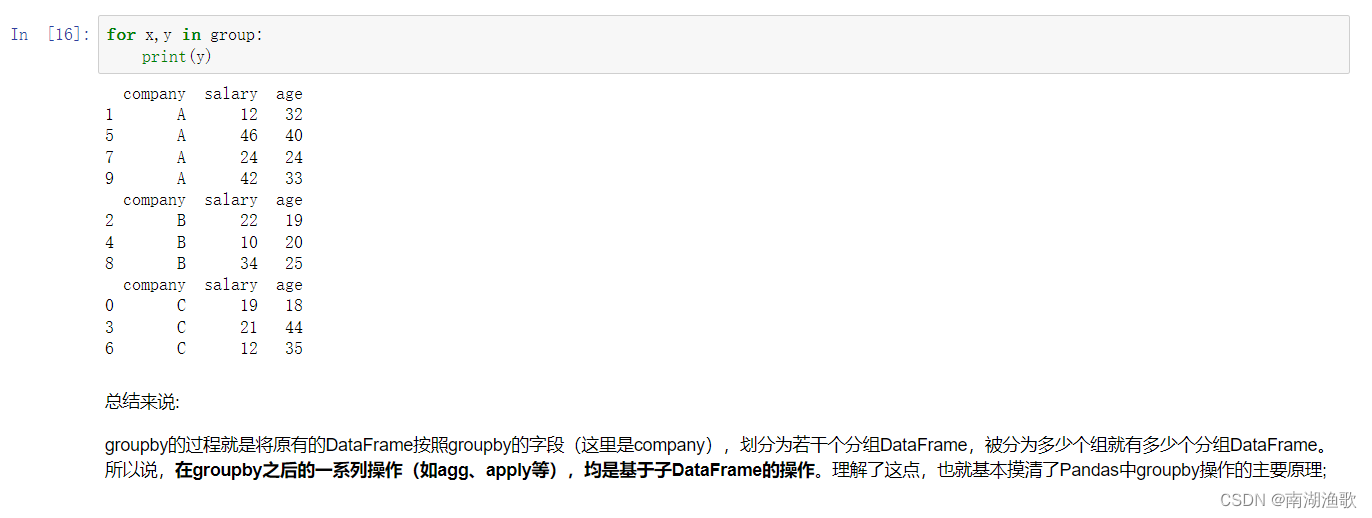
for x,y in group:
print(y)
# 总结来说:
# groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,**在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作**。理解了这点,也就基本摸清了Pandas中groupby操作的主要原理;
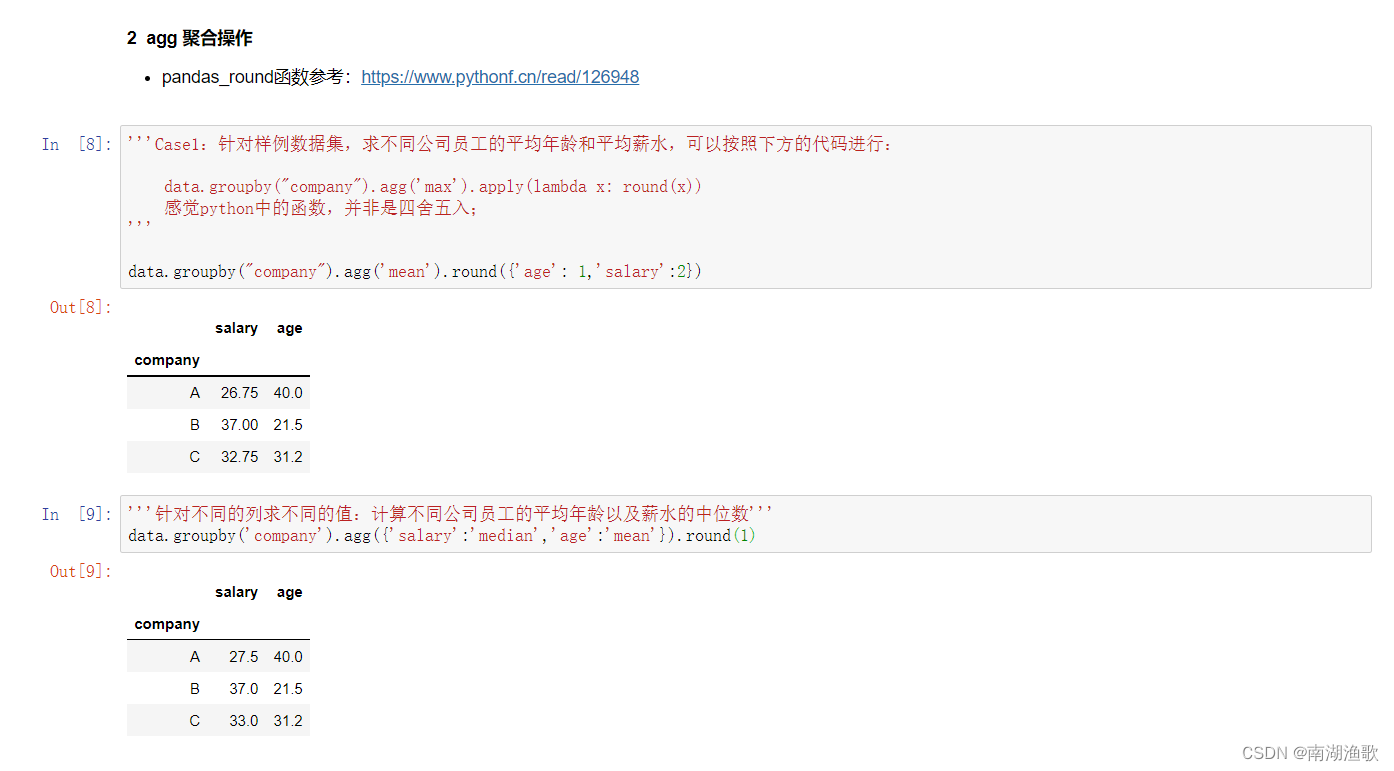
#### agg 聚合操作
- pandas_round函数参考:https://www.pythonf.cn/read/126948
'''Case1:针对样例数据集,求不同公司员工的平均年龄和平均薪水,可以按照下方的代码进行:
data.groupby("company").agg('max').apply(lambda x: round(x))
感觉python中的函数,并非是四舍五入;
'''
data.groupby("company").agg('mean').round({'age': 1,'salary':2})
'''针对不同的列求不同的值:计算不同公司员工的平均年龄以及薪水的中位数'''
data.groupby('company').agg({'salary':'median','age':'mean'}).round(1)
#### transform
#在上面的agg中,我们学会了如何求不同公司员工的平均薪水,如果现在需要在原数据集中新增一列avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?
avg_salary_dict = data.groupby('company')['salary'].mean().to_dict()
avg_salary_dict
'''map(avg_salary_dict) ——> 实现映射'''
data['avg_salary'] = data['company'].map(avg_salary_dict)
# 方法1:
data['avg_salary'] = data['company'].map(avg_salary_dict)
data.round(2)
# 方法2:
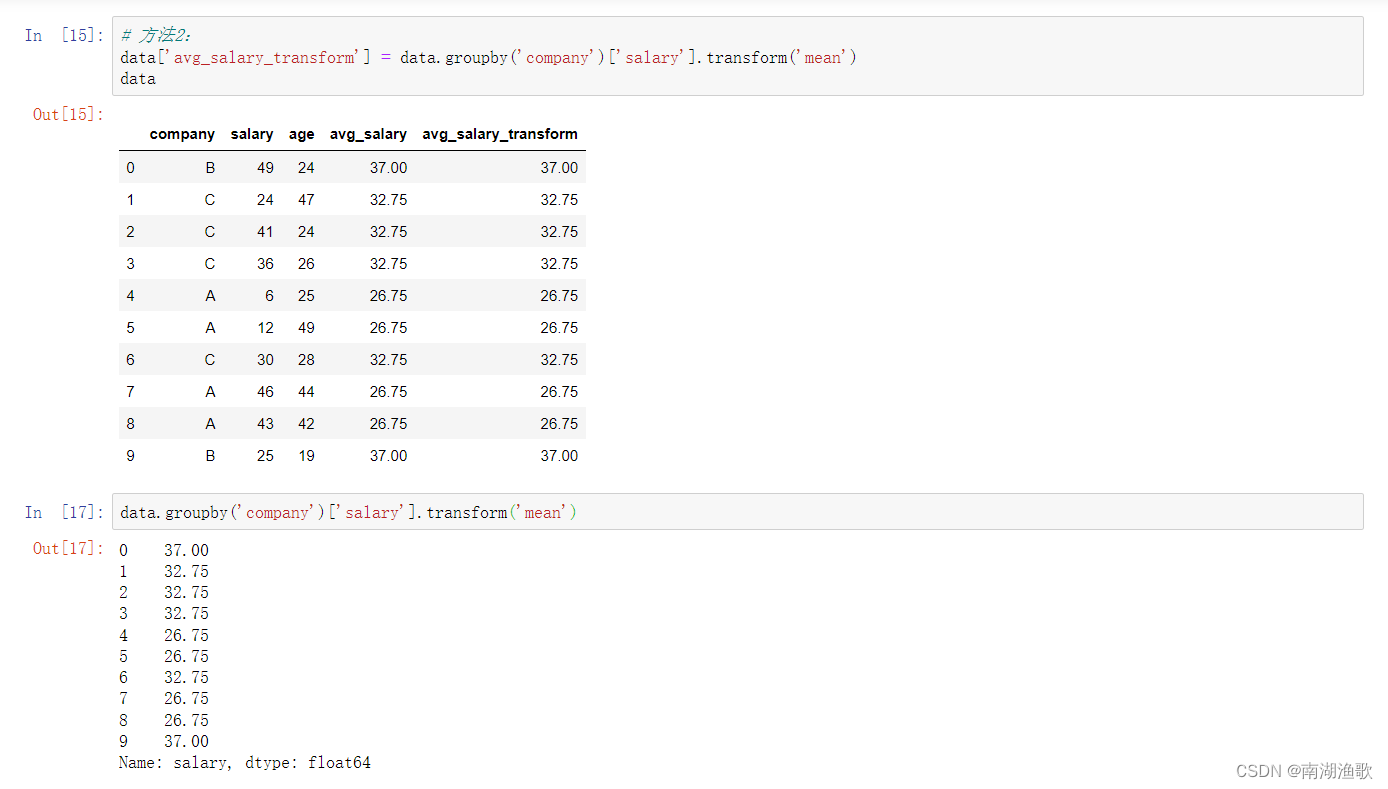
data['avg_salary_transform'] = data.groupby('company')['salary'].transform('mean')
data
data.groupby('company')['salary'].transform('mean')
#总结:
#对agg而言,会计算得到A,B,C公司对应的均值并直接返回,但对transform而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果;
#### apply
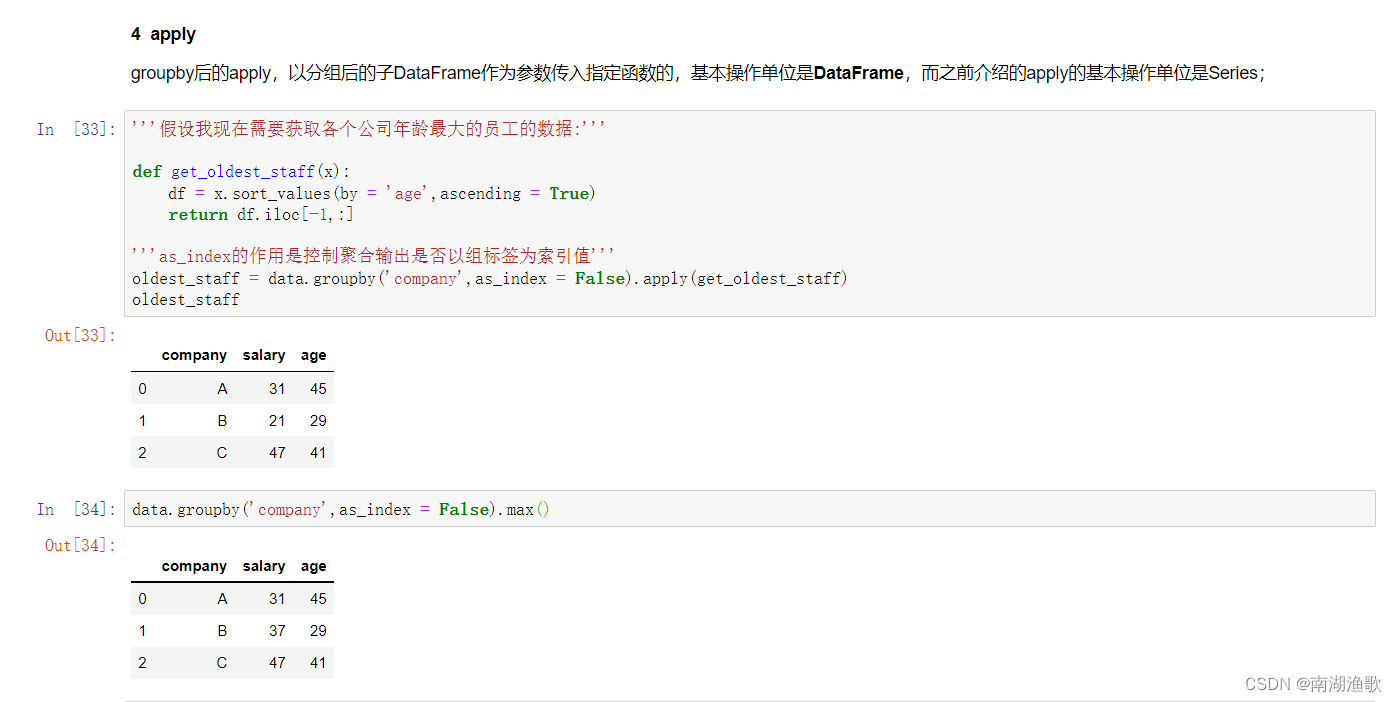
# groupby后的apply,以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是**DataFrame**,而之前介绍的apply的基本操作单位是Series;
'''假设我现在需要获取各个公司年龄最大的员工的数据:'''
def get_oldest_staff(x):
df = x.sort_values(by = 'age',ascending = True)
return df.iloc[-1,:]
'''as_index的作用是控制聚合输出是否以组标签为索引值'''
oldest_staff = data.groupby('company',as_index = False).apply(get_oldest_staff)
oldest_staff
data.groupby('company',as_index = False).max()















 3384
3384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









