







来源 学习统计科学,要学会打开上帝视角
1. 从玩色子看假设检验到底在干嘛
看完周润发的《赌神》之后,朋友小金也来到赌场赌色子,一个色子,买单双号:1、3、5为单,2、4、6为双。小金玩了100把,但是就只有4次买中,气的小金直跺脚,直呼运气太背……
难道小金的运气就这么差吗?咱们回头看看,是否哪里有猫腻。你肯定已经想到,每一把小金就算瞎猜,也会有50%的可能性猜对,这样重复玩100把,平均而言有50把的机会能买中,现在他只买中4把,这怎么可能呢?那原因在哪?很简单,问题出在色子上,我们说平均会有50把买中是建立在一个假设上的:色子是均匀的,没有人动手脚。但现在的情况是,他确实只买中了4把,而如果色子是均匀的,那么这种情况发生的概率及其微小,接近0,概率接近0的事情一般在一次试验(这100把游戏)下是不可能发生的,但现在却真真切切的发生了,于是,我们就有理由怀疑假设的真实性。
在这个例子中,我们就会怀疑色子可能不是均匀的,或者被人为操控了。所以,假设检验的基本逻辑就是:我们为了解决一个疑问,就先做一个假设,然后在这个假设的基础上推测已经发生了的事情的概率(在这个例子里面就是“小金猜中4次或少于4次的概率”),如果这个概率低于我们设定的参考值(如0.05),则我们就拒绝假设;而如果这个概率大于0.05,则我们就没有理由来拒绝原假设。
2. 第一类错误的概率为什么是α
统计学上把原假设H0为真而拒绝原假设称为犯了第一类错误。回到小金的例子,因为他只买中4把,根据推测,他是有理由拒绝色子是均匀的这个原假设,但事后通过专业人员检验发现:色子没有问题,纯粹是小金的运气太背了,那么这时,小金就犯错了,这便是第一类错误的由来,接着我们会问,犯这个错误的概率是多少呢?
为了便于理解,我们可以看另外一个计算简单的例子。比如,某公司生产的100台手机里有5台是次品,所以次品率就是5%。但质检团队事先不知道这个信息,于是他们需要通过假设检验来验证。首先,质检团队假设次品率不超过5%,那么他们认为一次抽样是抽不到次品的(统计学中小概率事件的定义:概率小于5%的事件被认为在一次试验中不会发生)。然而,当他们随机抽取一个手机来验证假设时,由于里面确实存在次品,谁也无法保证绝对就抽不到次品。所以,如果现实中他们恰好抽中了一个次品(抽中的概率是5%),然后他们就会下决定说:“在只有5个次品的情况下,一次抽样我们认为是抽不到次品的,但现在我们真实地就抽到了次品,于是,我们拒绝次品率不超过5%的假设,怀疑这100台手机里的次品超过5台。”
很明显,他们犯错了,而犯错的概率就是那5个次品所占的比例:在原假设为真的情况下,他们仍有5%的可能性抽中次品,所以犯错的概率也就是5%。因为抽中次品我们就会拒绝原假设,拒绝原假设,我们就犯错了(第一类错误:H0实际为真而拒绝H0),所以,此时犯错的概率就等于抽中次品的概率。类似的,如果我们人为地规定低于5%的事件是小概率事件,在一次试验中不会发生,那么我们就注定了会有5%的可能性犯错,因为人为规定的那些小概率事件在现实中是可能发生的,而发生的概率就是我们规定的5%,即犯错的概率便等于小概率事件发生的概率。
犯错的概率是P还是 α ?来源
对第一类错误进行的一个分析和补充,检验水准 α 是犯第一类错误的最大概率,当我们得出的P值小于 α 时,我们就会拒绝 H0 ,此时,犯错的真实概率是P值;而当P值大于 α 时,我们不会拒绝 H0 ,所以理论上讲,不存在犯第一类错误的说法
3. 第二类错误的理解
100个手机中实际有10个次品,即同样的H0假设(次品率不超过5%)现在变成假了。于是,质检团队仍先假设这100台手机中次品小于5个(H0),一次抽样,他们获得了一个正品,然后他们就说现在还不能拒绝H0,可以默认里面的次品数低于5个(统计学上不说接受H0)。同样地,他们又犯错了,因为实际上的次品有10个,即H0是假的,他们需要拒绝H0可他们没有。
那他们犯这个错误的概率是多大呢?90%。没错就是这么大,你可能会感到惊讶。但这其中的逻辑是,在这个检验中,他们要做出正确的判断就需要拒绝H0,而拒绝H0需要他们一次抽样就抽中次品,因为次品个数是10个,正品是90个,所以,只要他们抽中正品,他们就会犯错,因而他们犯错的概率就是抽中正品的概率,即90%。直觉上也是这样,比如,你去检验一批样品时,只做一次抽样就判断是否存在次品,显然会很不保险。在这个例子中,他们只有10%(次品率)的可能性不犯第二类错误,常称为检验功效。结合这个例子,“检验功效”也就很好理解,就是防止犯第二类错误的概率,即这个检验有效的概率:在H0为假拒绝H0的可能性。
4. 两类错误的联系
我们用假设检验进行判断时用的是第一个总体,即依据第一个总体的均数来计算检验统计量并判断是否要拒绝原假设,因为我们假设所获得的这个样本是来自于第一个总体的。但我们计算犯错概率时,用的是第二个实际总体,即我们这个样本并不是来自第一个总体,而是来自第二个实际的总体,在这个实际的总体中,会有多少样本点导致在前一步计算检验统计量时不拒绝H0。这一点理清之后,你可能就会豁然开朗。
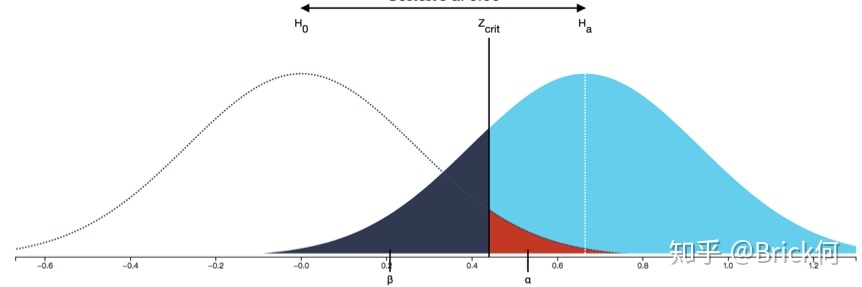
类似刚才的思路,我们有可能在实际均数为1.85的总体中抽出一些样本(上图黑色阴影部分所代表),而通过这些样本计算的样本均数与1.8差异不大,从而让我们不拒绝H0(因为这些样本不处于拒绝域,即红色阴影所代表的部分),进而导致第二类错误的发生。而计算错误发生概率大小,就是在实际1.85的总体中那些与1.8距离较近的样本点所组成的集合所占的比例(上图黑色阴影部分面积在实际总体所占的比例),正是这些集合的存在会让我们不拒绝H0而犯错。
通过上述说明,对照图你可能就能理解,为什么我们会说减少第一类错误的发生概率就会增加第二类错误的概率,因为,第一类错误的概率是我们根据检验水准人为设定的,当我们把检验水准从0.05提高到0.01时,我们减少了图中红色阴影的面积,但增大了图中黑色阴影的面积,该面积即为第二类错误发生概率。另一个常见的问题是为什么只有增加样本量才能同时减少这两类错误的犯错概率,简单理解,就是由于样本量的增加会降低标准误的大小(标准误=S/根号N,样本本量N越大,标准误越小,反映在图形中就是两个总体(假设总体和实际总体)变得更“细瘦”,所以重合的部分越少,由此代表犯错概率的图形的面积也会变小。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









