







ETL
hive分区表(presto不支持)
分区表创建
CREATE EXTERNAL TABLE IF NOT EXISTS <你的表名>(
res bigint COMMENT '注释',/*字段*/
hadoop_owner string COMMENT '注释',/*字段*/
data_type string COMMENT '注释'/*字段*/
)partitioned by(ymd STRING)/*通过什么字段进行分区*/
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001';/*间隔符格式*/
分区表插入
insert OVERWRITE table <你的表名> PARTITION(ymd =<要进行分区的字段>)
/*overwrite是覆写*/
hive与hdfs地址映射(presto不支持)
首先在建表时映射
/*与正常建分区表一致,只是需要添加最后一行映射关系*/
CREATE EXTERNAL TABLE IF NOT EXISTS log_basedata_hadoop.bigdata_core_indicator_monitor(
sum_result bigint COMMENT '治理后减少量',
hadoop_owner string COMMENT '租户'
)partitioned by(ymd STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001'
location '<hdfs地址>';
在对表进行操作时还要进行映射
alter table <你的hive表名> add if not exists partition(ymd=<分区划分的字段>) location '<hdfs地址>';
所谓分区就是在hdfs下按照分区字段建多个目录,所以location映射的地址只需要映射到分区上一层即可,不需要映射到每一个分区里
hive、presto的union all、group by
union和union all都用于联合多个select语句的结果集,合并为一个独立的结果集。
区别是union是会对结果集去重的,而union all不会去重,现在hive只支持union all
需要注意的是,hive中每个被union all联合起来的select语句的返回值必须一致,不然会报语法错误,而presto则不需要一样,因为presto会默认将第一条语句的返回值名字应用于联合出的结果集
例子如下
SELECT SUM(len) as sum1 ,owner FROM <表名> where ymd = 20210907 group by owner
union all
SELECT SUM(len) as sum1 ,owner FROM <表名> where ymd = 20210906 group by owner
在hive中跑一下,结果如下:
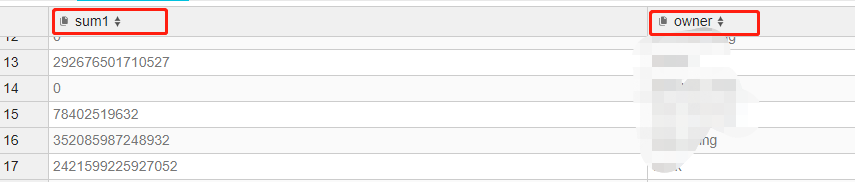
那么改为
SELECT SUM(len) as sum1 ,owner FROM <表名> where ymd = 20210907 group by owner
union all
SELECT SUM(len) as sum2 ,owner FROM <表名> where ymd = 20210906 group by owner
返回名不一致 发现会报语法错误

在presto中跑一次
SELECT SUM(len) as sum1 ,owner FROM <表名> where ymd = 20210907 group by owner
union all
SELECT SUM(len) as sum2 ,owner FROM <表名> where ymd = 20210906 group by owner
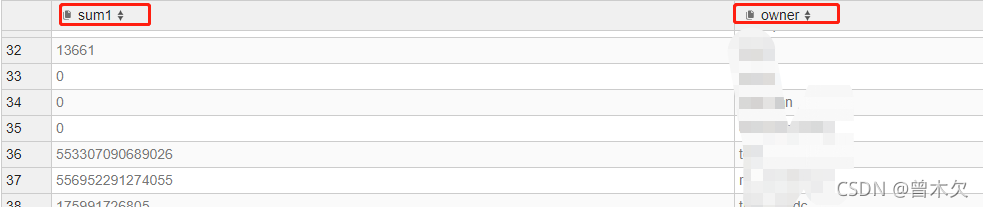
发现成功,presto会默认选择第一条的返回值应用于结果集返回名字
hive、presto的group by
group by是对检索结果的保留行进行单纯分组,一般总爱和聚合函数一块用例如AVG(),COUNT(),max(),main()等一块用
例子:
select MAX(sum1)-MIN(sum1) as result1,owner from(
SELECT SUM(len) as sum1 ,owner FROM <表名> where ymd = 20210907 group by owner
union all
SELECT SUM(len) as sum1 ,owner FROM <表名> where ymd = 20210906 group by owner
)e group by owner
这里就是按照owner进行分组:把所有owner的len进行相加然后分组查出来
注意被group by的字段必须在select中 如上面代码的owner 必须select
- 可能会出现网络负载过重的问题
- 可能出现数据倾斜(可以通过
hive.groupby.skewindata参数来优化数据倾斜的问题)



















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











