







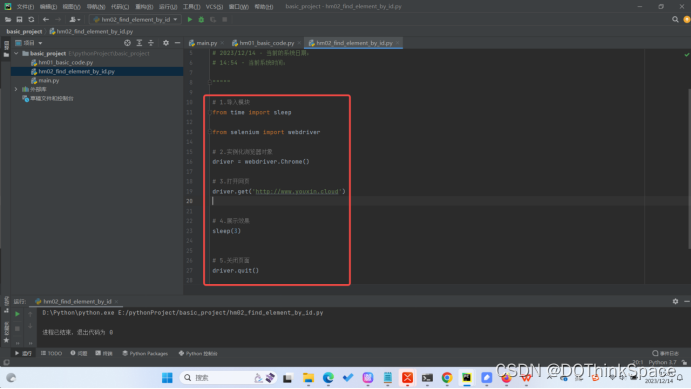
Q1:Web自动化基本代码实现
1.导入模块
from selenium import webdriver
2.实例化浏览器对象:类名()
driver = webdriver.Chrome()
3.打开网页:必须包含协议头
driver.get('http://www.baidu.com')
4.观察结果
sleep(3)
tips:注意导入sleep
5.关闭页面
driver.quit()
Q2:id方法
1、先跑一下,观察是否跑通,如果可以跑通再实现需求
2、测试跑通后,再实现需求
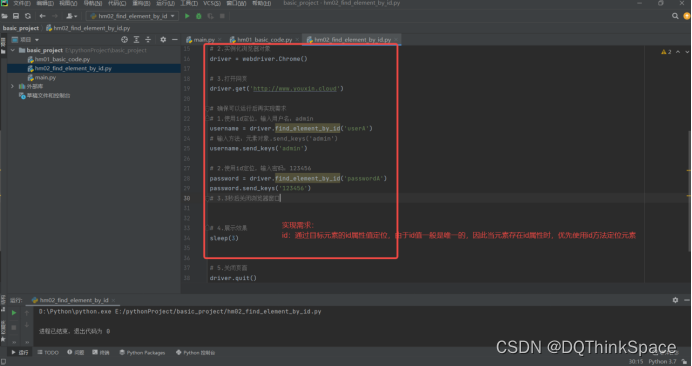
总结
id方法:通过目标元素的id属性值定位,由于id值一般是唯一的,因此当元素存在id属性值时,优先使用id方法定位元素。
Q3:name方法
实现需求:
在3-4之间实现需求。
3.打开网页:必须包含协议头
driver.get('http://www.baidu.com')
4.观察结果
sleep(3)
案例:name方法
需求:打开注册A.html页面,完成以下操作
1)使用name定位用户名,输入:admin
username = driver.find_element_by_name('userA')
username.send_keys('admin')
2)使用name定位密码,输入:123456
password = driver.find_element_by_name('passwordA')
password.send_keys('123456')
3)3秒后关闭浏览器窗口
总结
由于元素的name属性值可能存在重复,必须确定其能够代表目标元素唯一性之后,方可使用
tips:
注意当页面内有多个元素的特征是相同的时候,定位元素的方法执行时,默认只会获取第一个符合要求的特征对应的元素,
因此,定义元素时需要尽量保证使用的特征值能够代表目标元素在当前页面内的唯一性
Q4:class_name定位
说明:class_name定位就是根据元素class属性值来定位元素。HTML通过使用class来定义元素的样式。
前提:元素有class属性
注意:如果class有多个属性值,只能使用其中的一个
方法:element = driver.find_element_by_class_name(class_name)
Q5:tag_name定位
如图所示:
Q6:link_text定位
element = driver.find_element_by_link_text(link_text)
link_text:为超链接的全部文本内容。
Q7:partial_link_text定位
常用业务场景:
虽然只是传入部分文本信息,但是需要确定其唯一性,方可使用。
今日任务
- 实现2分钟内完成Web自动化基本代码
- 总结今日内容:思维导图
- 预习后续内容:截止到所有元素定位方法















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









