






 本文详细介绍了传统图像处理技术,包括灰度转换、滤波器应用、图像平滑与梯度、直方图均衡化、形态学操作、阈值处理、特征提取、几何变换、图像压缩、图像融合以及边缘检测,展示了PythonOpenCV中的具体实现。
本文详细介绍了传统图像处理技术,包括灰度转换、滤波器应用、图像平滑与梯度、直方图均衡化、形态学操作、阈值处理、特征提取、几何变换、图像压缩、图像融合以及边缘检测,展示了PythonOpenCV中的具体实现。
前言
传统图像处理是指使用经典的图像处理技术和方法,这些方法在计算机视觉和图像处理领域的早期阶段得到广泛应用。以下是一些传统图像处理的主要方法:
一、灰度转换
将彩色图像转换为灰度图像,使每个像素只包含亮度信息而不包含颜色信息。这通常是图像处理的第一步,常结合后续的一些算法进行操作。
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('car.jpg', 1)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow('img_gray', img_gray)
cv2.waitKey(0)
cv2.destroyAllWindows()
原图:

转换后:

二、滤波器和图像梯度
使用滤波器和卷积操作对图像进行平滑、锐化、边缘检测等处理。常用的滤波器包括均值滤波、高斯滤波、Sobel滤波器等。
1、图像平滑
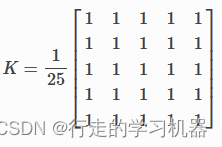
使用cv2.filter2D进行平滑操作。卷积核:
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('car.jpg', 1)
# img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
kernel = np.ones((5, 5), np.float32) / 25
dst = cv2.filter2D(img, -1, kernel)
cv2.imwrite('dst.jpg', dst)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()

图像平滑,常用于消除高频部分(例如噪声、边缘)。opencv提供4种类型的模糊方式:
(1)平均模糊:cv2.blur()或cv2.boxFilter();(2)高斯模糊: cv2.GaussianBlur();(3)中位模糊:cv2.medianBlur();(4)双边模糊:cv.bilateralFilter()。
2、图像梯度
OpenCV提供三种类型的算子,即Sobel,Scharr和Laplacian用于获取图像梯度。
Sobel算子是高斯平滑加微分的联合运算。Sobel分为x和y方向。
Laplacian 算子的每一阶导数通过Sobel算子计算。

import cv2
import matplotlib.pyplot as plt
if __name__ == '__main__':
img = cv2.imread('staff.jpeg', 0)
laplacian = cv2.Laplacian(img, cv2.CV_64F, ksize=3)
sobelx = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=5)
sobely = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=5)
plt.subplot(2, 2, 1), plt.imshow(img, cmap='gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 2), plt.imshow(laplacian, cmap='gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 3), plt.imshow(sobelx, cmap='gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 4), plt.imshow(sobely, cmap='gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])
plt.show()
三、直方图均衡化
通过调整图像的亮度分布,增强图像的对比度,使图像更容易分析和处理。一副好的图像有来自图像所有区域的像素,而不是仅仅局限于某个特定的值范围。
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('car.jpg', 0)
equ = cv2.equalizeHist(img)
res = np.hstack((img, equ)) # stacking images side-by-side
cv2.imwrite('res.jpg', res)

四、形态学处理
利用基本形态学操作,如膨胀和腐蚀,进行图像的形状和结构的处理,常用于图像分割和去噪。
腐蚀操作:原始图像中的一个像素(无论是1还是0)只有当kernel下的所有像素都是1时才被认为是1,否则它就会被腐蚀(变成0)。
膨胀操作:与腐蚀操作相反。kernel下至少有一个像素为1,就会被认为是1。该操作会增加前景对象的大小
开运算:先进行腐蚀操作再膨胀。
闭运算:先膨胀再腐蚀。
形态学梯度:膨胀后的图像减去侵蚀后的图像。
顶帽:原始图像减去开运算后的图像。
黑帽:原始图像减去闭运算后的图像。
import cv2
import numpy as np
import matplotlib.pyplot as plt
if __name__ == '__main__':
img = cv2.imread('j.png', 0)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
kernel = np.ones((5, 5), np.uint8)
erosion = cv2.erode(img, kernel, iterations=1) # 腐蚀
dilation = cv2.dilate(img, kernel, iterations=1) # 膨胀
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) # 开运算
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) # 闭运算
gradient = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel) # 梯度
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel) # 顶帽
blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel) # 黑帽
plt.figure(figsize=(10, 10))
plt.subplot(2, 4, 1), plt.imshow(img), plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(2, 4, 2), plt.imshow(erosion), plt.title('Erosion')
plt.xticks([]), plt.yticks([])
plt.subplot(2, 4, 3), plt.imshow(dilation), plt.title('Dilation')
plt.xticks([]), plt.yticks([])
plt.subplot(2, 4, 4), plt.imshow(opening), plt.title('Opening')
plt.xticks([]), plt.yticks([])
plt.subplot(2, 4, 5), plt.imshow(closing), plt.title('Closing')
plt.xticks([]), plt.yticks([])
plt.subplot(2, 4, 6), plt.imshow(gradient), plt.title('Gradient')
plt.xticks([]), plt.yticks([])
plt.subplot(2, 4, 7), plt.imshow(tophat), plt.title('Tophat')
plt.xticks([]), plt.yticks([])
plt.subplot(2, 4, 8), plt.imshow(blackhat), plt.title('Blackhat')
plt.xticks([]), plt.yticks([])
plt.show()

五、图像阈值
对图像进行二值化处理,凸显自己感兴趣的区域。阈值化处理常常是图像处理的前序步骤。
import cv2 as cv
from matplotlib import pyplot as plt
if __name__ == '__main__':
img = cv.imread('car.jpg', 0)
ret, thresh1 = cv.threshold(img, 127, 255, cv.THRESH_BINARY)
ret, thresh2 = cv.threshold(img, 127, 255, cv.THRESH_BINARY_INV)
ret, thresh3 = cv.threshold(img, 127, 255, cv.THRESH_TRUNC)
ret, thresh4 = cv.threshold(img, 127, 255, cv.THRESH_TOZERO)
ret, thresh5 = cv.threshold(img, 127, 255, cv.THRESH_TOZERO_INV)
titles = ['Original Image', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()

六、特征提取
从图像中提取出具有代表性的特征,如纹理、形状、颜色等,用于图像识别和分类。
常见的算法有:哈里斯角点检测、霍夫直线变换、SIFT算法等。
import numpy as np
import cv2 as cv
filename = 'chessboard.png'
img = cv.imread(filename)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv.cornerHarris(gray,2,3,0.04)
#result用于标记角点,并不重要
dst = cv.dilate(dst,None)
#最佳值的阈值,它可能因图像而异。
img[dst>0.01*dst.max()]=[0,0,255]
cv.imshow('dst',img)
if cv.waitKey(0) & 0xff == 27:
cv.destroyAllWindows()
七、几何变换
包括平移、旋转、缩放等基本的几何变换,用于调整图像的大小和位置。
1、缩放
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg')
res = cv.resize(img,None,fx=2, fy=2, interpolation = cv.INTER_CUBIC)
#或者
height, width = img.shape[:2]
res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
2、平移

import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
3、旋转

img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
# cols-1 和 rows-1 是坐标限制
M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)
dst = cv.warpAffine(img,M,(cols,rows))
4、仿射变换
在仿射变换中,原始图像中的所有平行线在输出图像中仍将平行。为了找到变换矩阵,我们需要输入图像中的三个点及其在输出图像中的对应位置。然后cv.getAffineTransform将创建一个2x3矩阵,该矩阵将传递给cv.warpAffine。
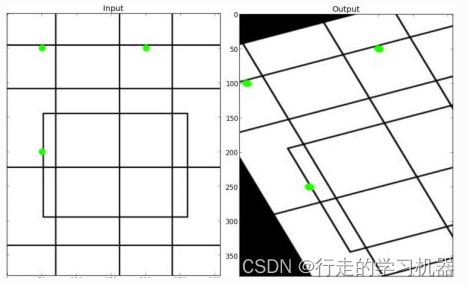
img = cv.imread('drawing.png')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
5、透视变换
对于透视变换,您需要3x3变换矩阵。即使在转换后,直线也将保持直线。要找到此变换矩阵,您需要在输入图像上有4个点,在输出图像上需要相应的点。在这四个点中,其中三个不应共线。然后可以通过函数cv.getPerspectiveTransform找到变换矩阵。然后将cv.warpPerspective应用于此3x3转换矩阵。
img = cv.imread('sudoku.png')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv.getPerspectiveTransform(pts1,pts2)
dst = cv.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()

八、图像压缩
使用各种压缩算法减小图像文件的大小,而尽量保持图像质量。JPEG、PNG等是常见的图像压缩格式。
九、图像融合
将多个图像或图像的不同部分合并成一个图像,常用于医学图像处理和计算机视觉领域。
import cv2 as cv
img1 = cv.imread('ml.png')
img2 = cv.imread('opencv-logo.png')
dst = cv.addWeighted(img1,0.7,img2,0.3,0)
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()
十、边缘检测
识别图像中物体之间的边缘,常用于图像分割和目标检测,常用算法有:Canny角点检测。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
edges = cv.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()
总结
以上是对常用的传统图像处理方式的总结。
参考链接


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









