






最终找到的Bug来源与解决方案:
Bug:
训练集和测试集上的准确率都很高,但是测试集始终低于5%,稳定地低于5%。
来源:
数据集文件夹命名问题导致ImageFolder加载的数据集的class_to_idx错误,因此每次输出的类别都是错的。
解决方案:
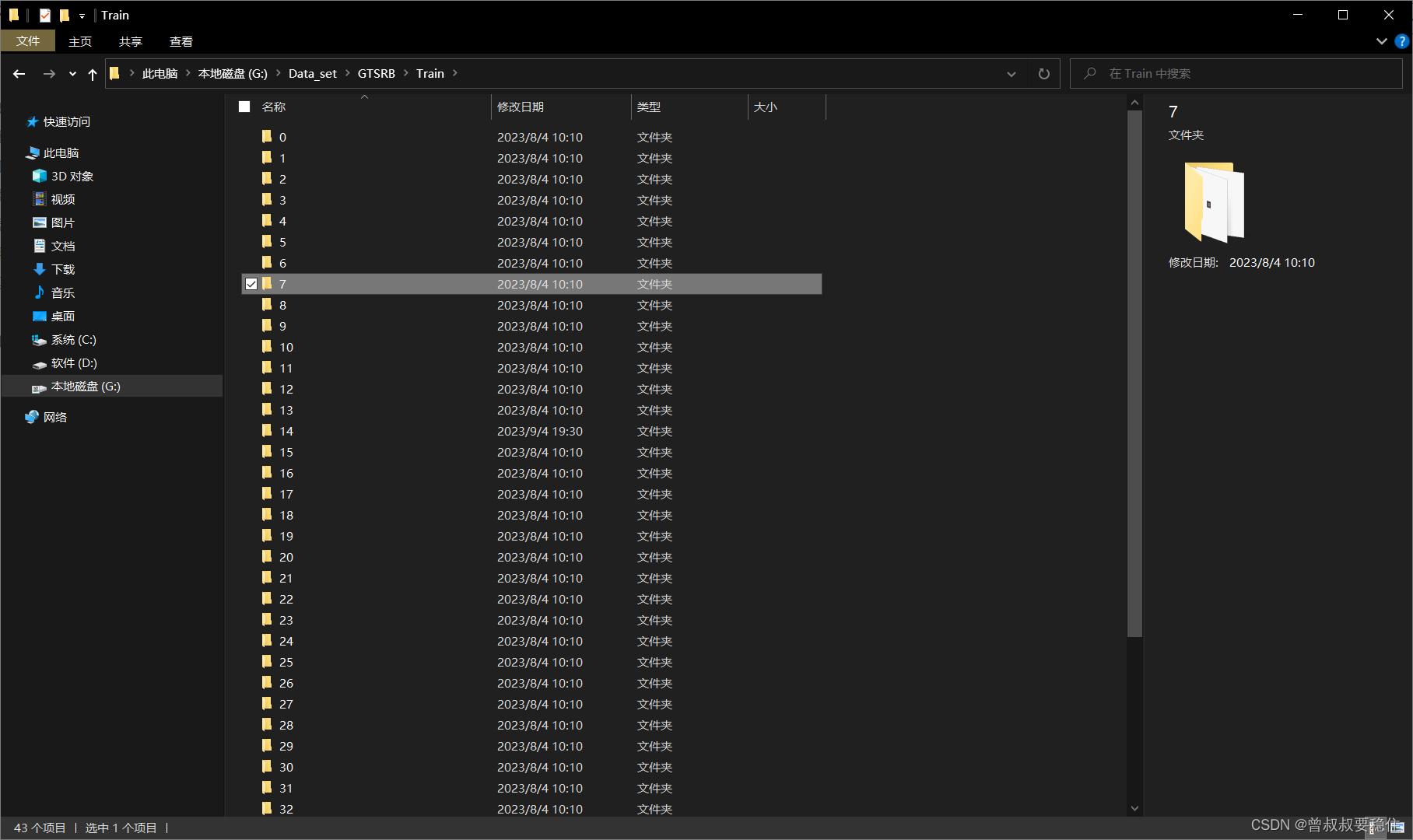
原数据集中的文件夹命名形式为:0、1、2、3......8、9、10......42;
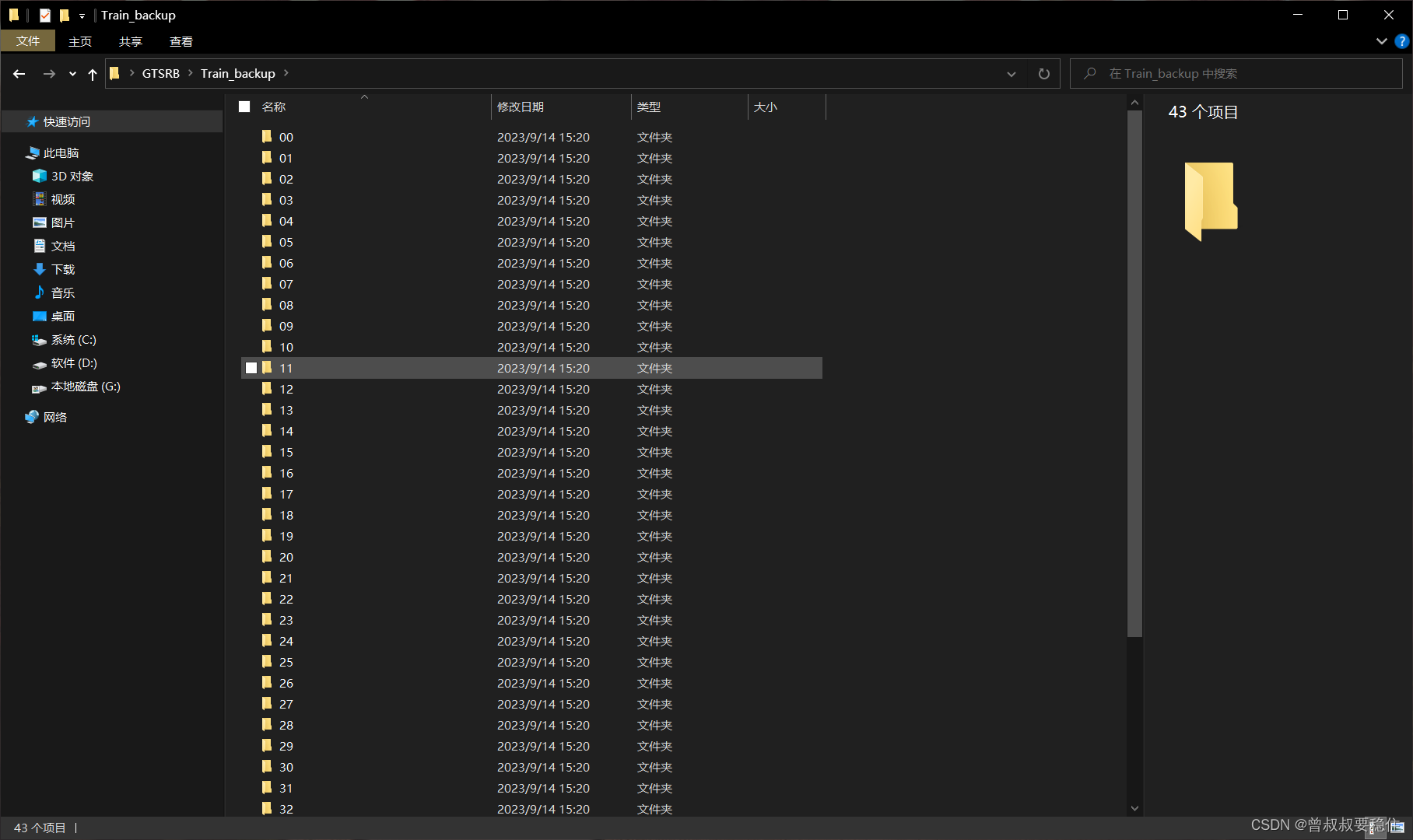
将数据集的文件夹名称改为00、01、02、03......08、09、10......42即可解决标签错乱问题;
修改前:
修改后:
如何发现Bug的:
可能的原因排查:
首先确保相关流程的代码没有写错,再从每个部分分别进行排查:
根据训练模型的流程,对以下几个部分依次进行排查;
- 训练全连接层 -> 2. 微调卷积层 -> 3. 测试集测试
- 数据集加载(datasets,数据集加载可能有问题,如乱序)
- 数据加载进模型进行训练(dataloader,输入进分类器的组织形式是否有问题,如乱序)
- 预训练模型加载(train_fc,训练代码是否有问题)
- 训练好的模型保存(torch.save,模型保存是否正常,单/多卡保存存在差异)
- 加载重新训练全连接层的模型(fine_tuning,加载模型是否正常,微调代码是否正常)
- 训练好的模型保存(torch.save,模型保存是否正常,单/多卡保存存在差异)
- 加载训练好的模型进行测试(test,加载模型是否正常,计算准确率是否正确)
观察输出结果:
中途确实遇到了加载模型失败的情况,原因是单双卡保存的模型不一样,加载也存在些许差异,但这很容易解决,不是问题重点。
星期四的早上我突然发现,测试集输出的标签虽然是错的,但是错的很一致呀,2一直被输出为10,3一直被输出为11?训练了这么多次,每次都错的一样这难免让我很好奇。
于是我收集了输出结果的键值对,强行用键值对改变输出标签后,测试集准确率直接飙升至95+%;
这时候就可以锁定问题了,就是加载数据时文件与标签对应错误了,那到底是哪里对应错误了呢?
我使用datasets中的ImageFolder加载的数据集,文件组织形式是按照推荐的形式的标准数据集;随后用dataloader将数据分块进行加载,我检查了好多遍代码也发现Bug,一点头绪也没有;
然后我就想着对datasets加载的图片进行可视化,发现确实的标签和图像文件没有对应上,随后进行debug,发现ImageFolder返回的对象中包含一个属性叫:classes_to_idx,里面的类别和标签没对应上。

突然猛地想起我在某个地方看到的文件夹命名为000、001、002的样式,于是我尝试着对应地进行修改,好了,就这样解决了???















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









