







爬取京东所有有关ipad的商品信息, 在搜索栏中输入iPad 点击搜索来到以下页面
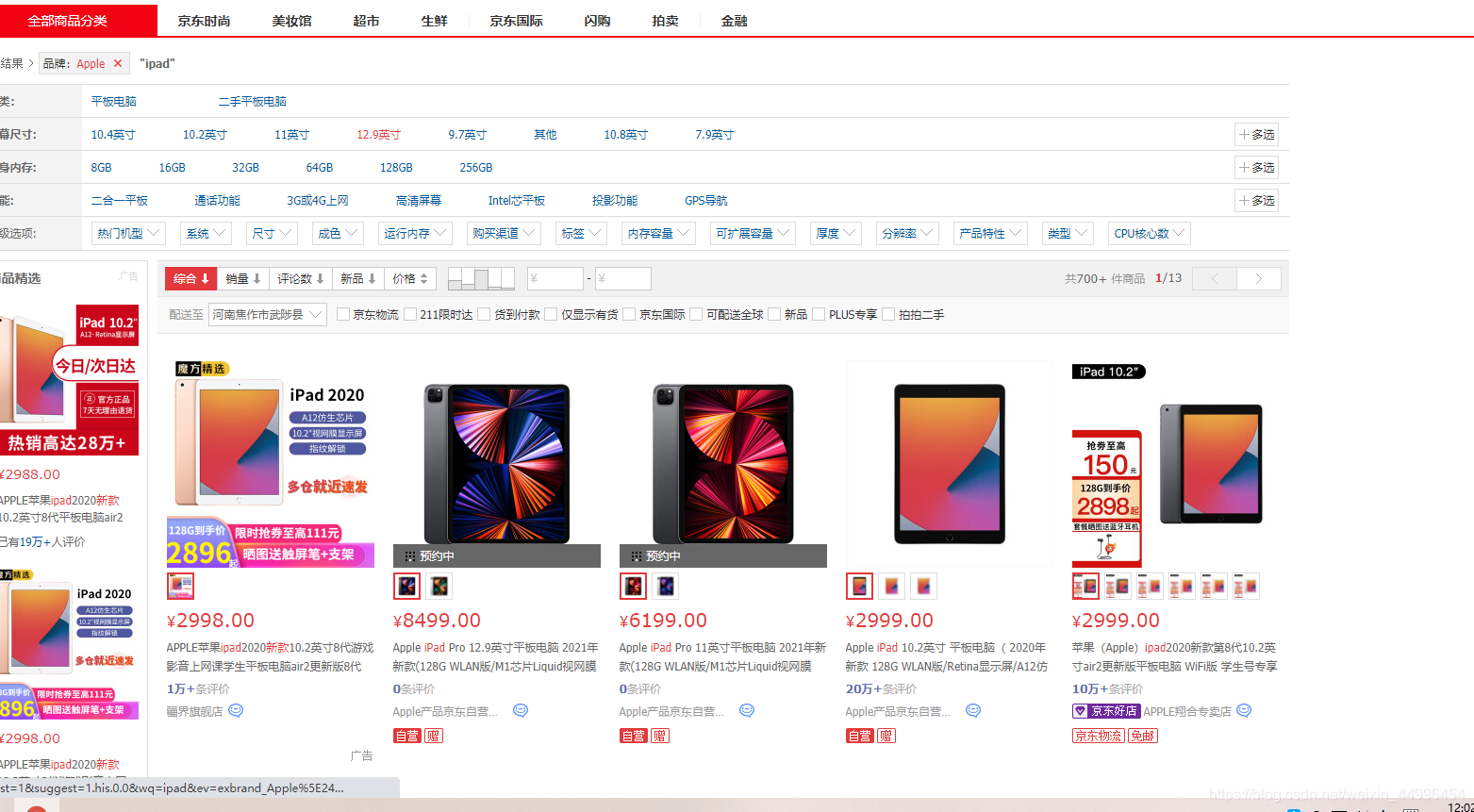
接下来我们分析商品每页的url
这是第二页的url : https://search.jd.com/Searchkeyword=ipad&qrst=1&suggest=1.his.0.0&wq=ipad&ev=exbrand_Apple%5E&page=3&s=56&click=0
我们把多余的参数去掉 换成如下的格式:
https://search.jd.com/Searchkeyword=ipad&page=3 也能访问该页面,接下来就简单了只需要改变参数page的值就可以得到所有页面的url, 然后用selenium模拟浏览器发送请求就可以得到商品的各种信息再调用parse函数解析我们想要的信息。
代码实现:
spiders.py
import scrapy
from TaobaoPro.items import TaobaoproItem
class TaobaoSpider(scrapy.Spider):
name = 'taobao'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://search.jd.com/Search?keyword=ipad']
for i in range(1,13):
url = 'https://search.jd.com/Search?keyword=ipad&page={}'.format(2*i-1)#把我们要爬取的页面添加到start_urls中
start_urls.append(url)
def parse(self, response):
print(response.url)#打印出我们所要爬取的页面
# href = 'https:' + response.xpath('//div[@id="J_goodsList"]/ul/li[1]/div/div/a/@href').extract_first()
# print(href)
li_list = response 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2833
2833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









