







本篇博客会介绍如何使用python在excel和csv里实现vlookup函数的功能,首先需要简单了解一下python如何操作excel
1. python处理excel
1.1 删除excel中指定行
在文件夹里创建了一个excel文件,可以看到里面放的是三国人物的数据
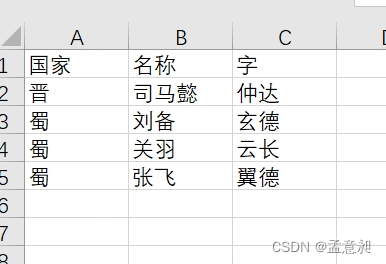
会发现在【蜀】里,多了一个【晋】,所以此时我们先实现删掉这条数据
import pandas as pd
import openpyxl
import os
shu = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/蜀.xlsx'
#删除指定行
df_shu = pd.read_excel(shu)
selected_rows = df_shu.loc[df_shu["国家"] == "晋"]
print(selected_rows)
这时我们就已经将需要删除的数据找了出来

此时可以使用数据框的drop()方法来删除选定的行
df_shu = df_shu.drop(selected_rows.index)
print(df_shu)

现在只需要将结果存回excel就完成了这个需求
#保存至excel
df_shu.to_excel(shu, index=False)
此时再打开文件夹内的excel就会发现已经删掉了【晋】的数据
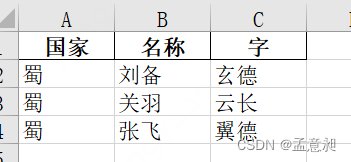
1.2 获取excel的最大行数
在不打开一个excel的前提下,可以通过openpyxl来直接获取这个文件的最大行数,方便对这个文件大小有个初步的理解
import pandas as pd
import openpyxl
import os
shu = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/蜀.xlsx'
wei = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/魏.xlsx'
wu = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/吴.xlsx'
#删除指定行
df_shu = pd.read_excel(shu)
df_wei = pd.read_excel(wei)
df_wu = pd.read_excel(wu)
#查看最大行数
workbook = openpyxl.load_workbook(wei)
worksheet = workbook['Sheet1']
max_row = worksheet.max_row
print(max_row)
这样就可以直接获取最大行数为4

1.3 将excel表进行上下拼接
在当前的示例中,魏蜀吴三个势力的数据是分开存放的,现在想要汇总出整个三国的数据,就可以先提取表头,再将剩下的内容合并在一起,这时可以通过concat函数进行实现
import pandas as pd
import openpyxl
import os
shu = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/蜀.xlsx'
wei = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/魏.xlsx'
wu = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/吴.xlsx'
#删除指定行
df_shu = pd.read_excel(shu)
df_wei = pd.read_excel(wei)
df_wu = pd.read_excel(wu)
#两张表进行上下拼接
df = pd.concat([df_shu, df_wei, df_wu])
# 将合并后的数据写入新的Excel文件
df.to_excel(r"D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/三国.xlsx", index=False)
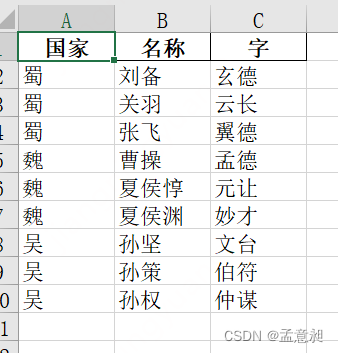
运行之后就会发现在当前文件夹里多出来了一个新文件

而里面的内容也确实是几个文件的内容拼接
1.4 实现excel中的vlookup函数
平时在工作中,会需要将两份excel进行vlookup操作,如果数据量比较大,则程序会运行的比较慢,这时候就可以用merge函数进行实现
import pandas as pd
import openpyxl
import os
#两张表进行vlookup
sanguo = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/三国.xlsx'
wuqi = r'D:/Python_Project/data_analysis/csdn/pandas/pandas合并excel/源文件/武器.xlsx'
df_sanguo = pd.read_excel(sanguo)
df_wuqi = pd.read_excel(wuqi)
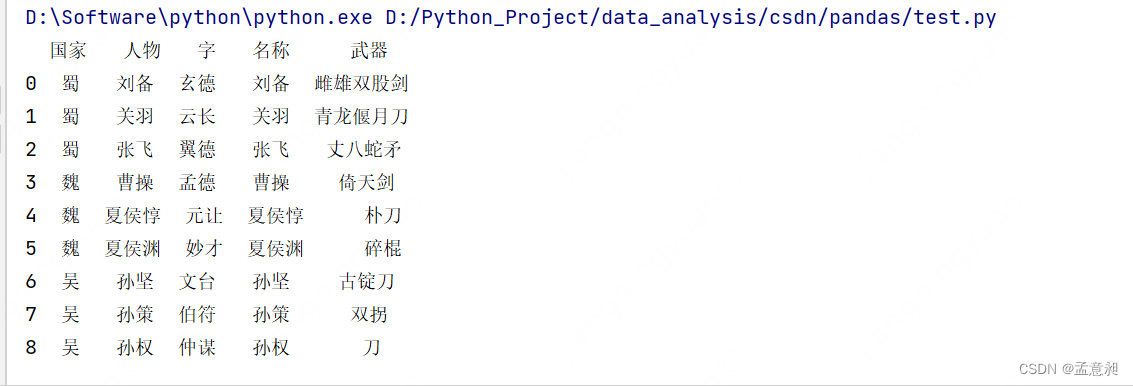
df=pd.merge(df_sanguo, df_wuqi, how= 'left',left_on = '人物', right_on = '名称')
print(df)
其中how参数是连接方式,这里使用的是左连接,left_on 和right_on 参数是两张表关联所使用的字段名称,运行程序后会直接看到关联后的结果
2. python处理csv
经过实测,对csv文件进行vlookup操作和对excel是一样的,都可以直接使用merge函数
















 5113
5113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











