







Wine数据集分类——贝叶斯分类算法(MATLAB实现)
一、Wine数据集的介绍
1.1 实验目的
该实验的Wine数据集来自于UCI机器学习数据库中,数据集中的数据则是产自意大利同一地区但来自三个不同品种的葡萄酒进行化学分析的结果,分析确定了三种酒中每种所含13种不同成分的数量。
实验的目的就是利用分类算法实现Wine数据集中三种不同品种的葡萄酒分类。通过学习贝叶斯分类相关的知识,我们决定使用贝叶斯分类算法对Wine数据集进行分类。Wine数据集含有178个样本,我们将采用k折交叉验证的方法选取训练集和测试集,并采用朴素贝叶斯分类算法实现Wine数据集的分类。实验过程所使用的编程软件为MATLAB仿真软件,利用MATLAB实现算法及分类。
1.2 数据介绍
下表是Wine数据集的相关信息。
| Data Set Characteristics: | Multivariate | Number of Instances: | 178 | Area: | Physical |
|---|---|---|---|---|---|
| Attribute Characteristics: | Integer, Real | Number of Attributes: | 13 | Date Donated: | 1991-07-01 |
| Associated Tasks: | Classification | Missing Values? | No | Number of Web Hits: | 1509517 |
这些数据包括了三种酒中13中不同成分的数量。13种成分分别是:Alcohol、Malic acid、Ash、 Alkalinity of ash、Magnesium、Total phenols、Flavanoids 、Nonflavanoid phenols、Proanthocyanins、Color intensity、Hue、OD280/OD315 of diluted wines、Proline。在‘Wine.data’文件中,每一行代表一种酒的样本,共有178个样本;一共14列,其中第一列为类别标志属性,共有3类,分别标记为‘1’、‘2’、‘3’,对于三种不同的葡萄酒;后面13列为每一个样本对应属性的属性值;类别‘1’共有59个样本,类别‘2’共有71个样本,类别‘3’共有48个样本。
由于数据集中每个样本的数据都是完整的,没有空缺值,所以没有对该数据集进行必要的数据清洗工作。
1.3 数据来源
http://archive.ics.uci.edu/ml/datasets/Wine
二、贝叶斯算法理论
2.1 贝叶斯分类
贝叶斯分类是指通过训练集(已分类的数据子集)训练来归纳出分类器,并利用分类器对未分类的数据(可以看作是测试集)进行分类。其基本思想是依据先验概率、类条件概率的信息,并按照某种准则使分类结果从统计上讲是最佳的。它是一种有监督学习的分类方法。
2.2 贝叶斯公式
若已知总共有M类样品,以及各类在n维特征空间的统计分布,根据概率知识可以通过样品库得知各类别 w i ( i = 1 , 2 , . . . , M ) w_i(i=1,2,...,M) wi(i=1,2,...,M)的先验概率 p ( w i ) p(w_i) p(wi)以及类条件概率 p ( X / w i ) p(X/w_i) p(X/wi)。对于待测样品,贝叶斯公式可以计算出该样品分属各类别的概率,叫做后验概率 p ( w i / X ) p(w_i/X) p(wi/X) 。比较各个后验概率,把X归于后验概率最大的那一个类。
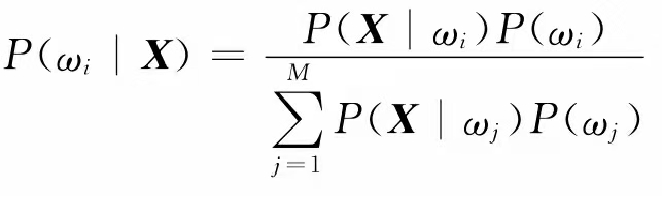
2.3 朴素贝叶斯分类器的设计流程
首先,朴素贝叶斯分类其实就是基于最小错误率的贝叶斯分类,同时也称最大后验概率的贝叶斯分类。
朴素贝叶斯分类的整个流程如下图所示:可以看到,整个朴素贝叶斯分类分为三个阶段:
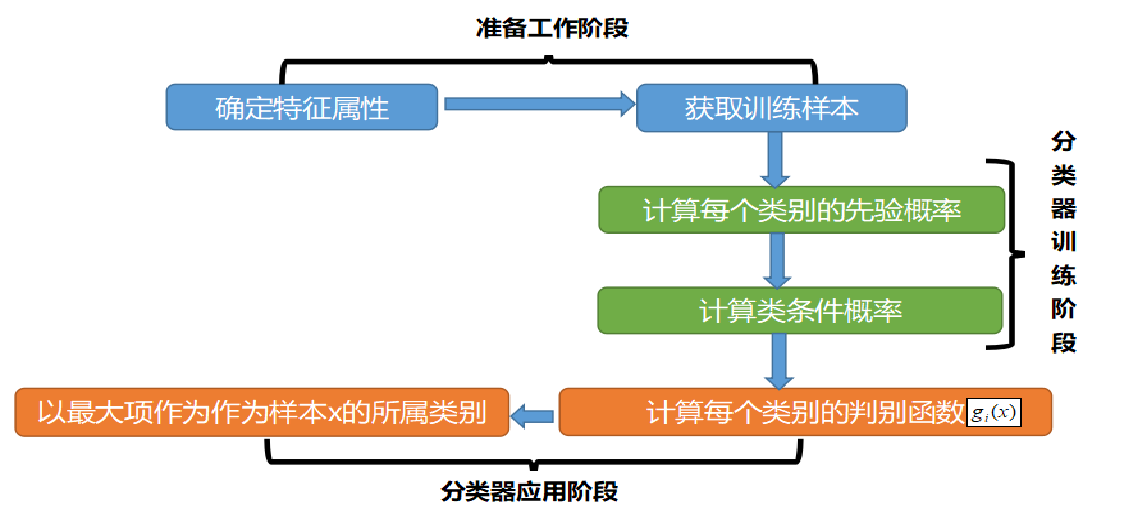
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
2.3 朴素贝叶斯分类器的数学原理
本实验中所采用的贝叶斯分类算法是朴素贝叶斯分类算法。朴素贝叶斯算法又叫做基于最小错误率的贝叶斯分类算法,也可称为基于最大后验概率的贝叶斯分类算法。它的原理就是利用贝叶斯公式将样本划分到后验概率最大的那一类中。因此可以定义每一类的判别函数为:
由于在同一个模式识别问题中,对于不同的类,贝叶斯公式中的全概率是相同的,所以,各类的判别函数也可以定义为: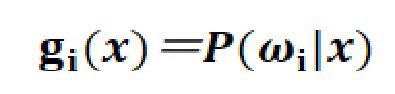
假设样本空间被划分成c个类别决策区域,则分类判决规则为: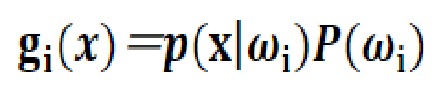
此时,任意两个类别之间的决策边界由下述方程决定: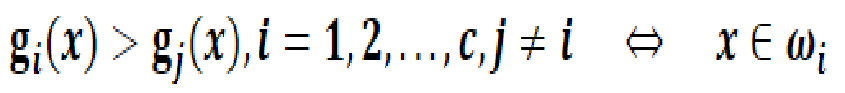
先分析一下判别函数。在判别函数中,先验概率是一个与特征向量无关的常量,类条件概率密度则满足一定的概率分布。因为类条件概率与我们要识别的样本x有关。可以说,类条件概率是x的函数。对于一个类别的所有样本,x的取值会呈现出某种概率分布,如果我们知道这个概率分布,也就知道了类条件概率密度,那么贝叶斯分类的分类决策规则也就确定下来了。类条件概率具有不同的概率分布,相应贝叶斯分类的分类决策规则就会有不同的形式。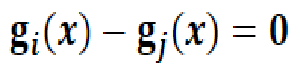
常见的类条件概率分布有:均匀分布、指数分布、正态分布等。
对于连续变量,在大多数情况下,采用的是正态分布(高斯分布)。也就是说,类条件概率密度可以采用多维变量的正态密度函数来模拟,得到的贝叶斯分类也叫做高斯朴素贝叶斯分类
插讲:多维正态分布是样本在更高维度上的正态分布,它的基本形式与一维正态分布是相同的。只是在方差项上由一个协方差矩阵代替了方差,反映了各个维度之间存在的关联。

因此,我们假设类条件概率符合多维正态分布,则判别函数可以写成:
由于该判别函数含有指数,不方便计算。故取对数得到新的判别函数: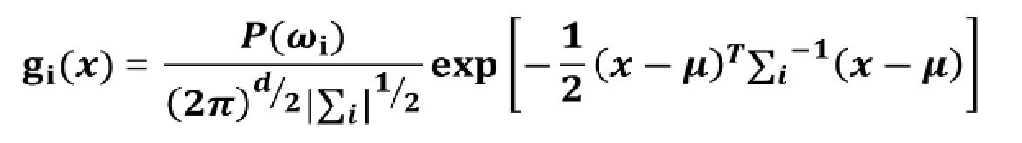
将其化简为: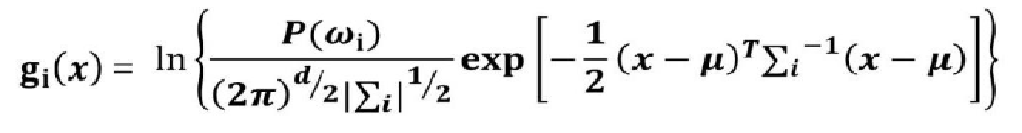
由于 d 2 ln ( 2 π ) \frac{d}{2}\ln (2π) 2dln(2π)与类别无关,所以判别函数可以进一步简化为: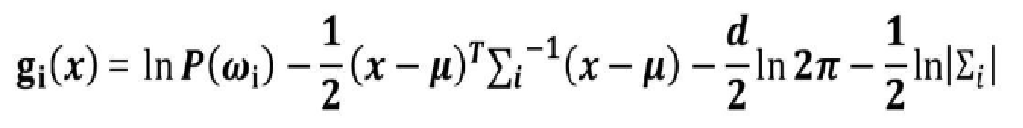
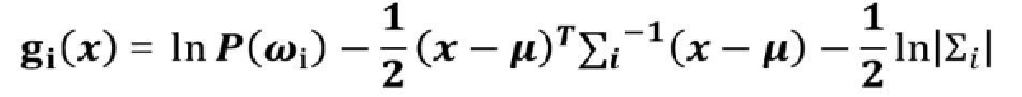
我们后面的实验过程就是根据此判别函数作为样本区分的依据。
三、MATLAB仿真实现
方案一:利用MATLAB自带的贝叶斯分类工具
clear
clc
load wine.data
wine_class = wine;
%训练集与测试集的划分
data_train = [wine_class(1:35,:);wine_class(55:115,:);wine_class(131:163,:)];
data_test = [wine_class(36:54,:);wine_class(116:130,:);wine_class(164:178,:)];
train_num = length(data_train);
test_num = length(data_test);
train_labels1 = data_train(:,1);
test_labels1 = data_test(:,1);
% 这里对数据进行一次处理。贝叶斯分类器要求输入数据中同类别中一个特征的方差不能为0
% 由公式我们可以知道,计算后验概率时,如果某一列特征全部相同,那么后验概率计算时分母会变为0,
% 为了避免该种情况,需要对数据进行提前处理
[data_train,position] = data_proc(data_train,train_labels1(1:train_num)');
% 对训练数据进行处理后,同时也要对测试数据进行同样的处理
for rows = 1:10
data_test(:,position{1,rows})=[];
end
%模型部分
% 超参数全部取了默认值,比较重要的,如类别的先验概率,如果不进行修改,则计算输入数据中类别的频率
% 查看nb_model即可确认所使用的超参数
nb_model = fitcnb(data_train,train_labels1(1:train_num));
%训练模型
%测试结果
result = predict(nb_model,data_test);
result = result.';
fprintf('预测结果:');
result(1:test_num)
%取30个打印出来对比
fprintf('真实分布:');
test_labels1(1:test_num)'
% 整体正确率
acc = 0.;
for i = 1:test_num
if result(i)==test_labels1(i)
acc = acc+1;
end
end
fprintf('精确度为:%5.2f%%\n',(acc/test_num)*100);
% data_proc.m
% 函数功能:删除同类数据特征中方差为0的特征列
% 输入:行向量数据及标签
% 输出:删除列之后的数据以及删除的列标
function [output,position] = data_proc(data,label)
position = cell(1,10);
%创建cell存储每类中删除的列标
for i = 0:9
temp = [];
pos = [];
for rows = 1:size(data,1)
if label(rows)==i
temp = [temp;data(rows,:)];
end
end
for cols = 1:size(temp,2)
var_data = var(temp(:,cols));
if var_data==0
pos = [pos,cols];
end
end
position{i+1} = pos;
data(:,pos)=[];
end
output = data;
end
分类精确度是一个固定值,为:97.96%
说明:
(1)此代码采用的MATLAB自带的函数工具,分别为训练模型函数fitcnb()与预测模型函数predict()。两个函数的用法可以参考MATLAB软件:【帮助】,里面有相关函数的解释。
(2)此代码中的训练集与测试集的划分完全是根据自己的设置调整的,不是十分地严谨。
(3)代码中没有对数据进行归一化处理。在实际中,数据集中每个属性对应的值可能相差很大,此时就需要归一化处理,将不同类型的特征数值大小变为一致,方便数据处理。
方案二:自编函数实现贝叶斯分类算法
clear
clc
load wine.data
wine_class = wine;
% mapminmax为MATLAB自带的归一化函数
[wine_class,ps] = mapminmax(wine_class(:,2:size(wine_class,2))',0,1); %归一化要先转至
wine_class = [wine(:,1),wine_class'];
% 训练集和测试集的划分
% K-折交叉验证(k-fold crossValidation)
[wine_class_r, wine_class_c] = size(wine_class);
K=10;
sum_accuracy = 0;
%将数据样本随机分割为10部分
indices = crossvalind('Kfold', wine_class_r,K);
for i = 1 :K
% 获取第i份测试数据的索引逻辑值
test = (indices == i);
% 取反,获取第i份训练数据的索引逻辑值
train = ~test;
%1份测试,9份训练
test_data = wine_class(test, 2 : wine_class_c);
test_label = wine_class(test, 1);
train_data = wine_class(train, 2 : wine_class_c );
train_label = wine_class(train, 1);
%模型的训练以及预测结果
train_model = Naive_Bayesian( train_data,train_label);
result = predict_BN(train_model,test_data,test_label);
accuracy_test = sum(result == test_label) / length(test_label)*100;
sum_accuracy = sum_accuracy + accuracy_test;
end
%求平均准确率
mean_accuracy = sum_accuracy / K;
disp('平均准确率:');
fprintf('%15.2f%%\n',mean_accuracy)
function [model]= Naive_Bayesian(X, Y)
% 朴素贝叶斯分类器的实现
m=size(X,1);%记录训练集样本总数
n=size(X,2);%记录训练集特征属性数目
%记录类别数及每个类别编号
yy=Y(:);
yy=sort(yy);
d=diff([yy;max(yy)+1]);%差分计算
count = diff(find([1;d]));%记录每个类别出现次数//find返回非零元素的索引位置
class_num=yy(find(d));%记录类别编号[1;2;3]
%计算每个类别的先验概率 p(W)
for i=1:length(class_num)
pW(i) = count(i)/m;
end
x1 = X(1:count(1),:); %第一类样本
x2 = X(count(1)+1:count(1)+count(2),:); %第二类样本
x3 = X(count(1)+count(2)+1:count(1)+count(2)+count(3),:); %第三类样本
x = {x1;x2;x3};
for i = 1:length(class_num)
smean{i} = mean(cell2mat(x(i))); %求各类别的均值
scov{i} = cov(cell2mat(x(i))); %求各类别的协方差矩阵
end
for i = 1:length(class_num)
sinv{i} = pinv(cell2mat(scov(i))); %求各类别协方差矩阵的逆矩阵
sdet{i} = det(cell2mat(scov(i))); %求各类别协方差矩阵的行列式
end
model.ssmean = smean;
model.sscov = scov;
model.ssinv = sinv;
model.ssdet = sdet;
model.pW = pW;
end
function result = predict_BN(model,X,Y)
%朴素贝叶斯分类器的预测
ssmean = model.ssmean ;
sscov = model.sscov ;
ssinv = model.ssinv ;
ssdet = model.ssdet ;
pW = model.pW;
m = size(X,1);%记录测试样本总数
n = size(X,2);%记录测试样本特征数13
%记录每个类别编号
yy=Y(:);
yy=sort(yy);
d=diff([yy;max(yy)+1]);%差分计算
class_num=yy(find(d));%记录类别编号
%求判别函数gi(x)
for i = 1:length(class_num)
for j = 1:length(X)
gi(j,i) =log(pW(i))-(1/2)*(X(j,:)'-cell2mat(ssmean(i))')'*(cell2mat(ssinv(i)))*(X(j,:)'-cell2mat(ssmean(i))')-(1/2)*log(cell2mat(ssdet(i)));
end
end
for i=1:m
[max_Pro(i,1), index] = max(gi(i,:));%输出处于最大概率的概率值以及其对应的索引位置
result(i,1)=class_num(index);%待测样本的预测类别
end
end
每次运行的分类精确度不同:大致在98%~100%
说明:
(1)代码中数据的归一化函数采用的是mapminmax()。
(2)训练集与测试集划分不是随意划分的,也不是根据准确率的高低来调整训练集与测试集,而是采用k折交叉验证(K=10),k-折交叉验证的相关知识请大家咨询一下其他博客,本文不一一赘述。
(3)后面朴素贝叶斯分类训练模型Naive_Bayesian()与预测模型predict_BN()是自己根据上面讲述的判别函数自编的。
(4)在10折交叉验证中,每次运行都有10次分类结果,将10次分类结果取平均值,就可以得到比较准确的分类精度。
写到这里很不易,感谢大家大家滴观看!
有错误敬请指正,看到尽量根据水平改。















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









