






Python中有三个去除头尾字符、空白符的函数,它们依次为:
- strip: 用来去除头尾字符、空白符(包括\n、\r、\t、‘ ‘,即:换行、回车、制表符、空格)
- lstrip:这里的l代表left, 用来去除开头字符、空白符(包括\n、\r、\t、‘ ‘,即:换行、回车、制表符、空格)
- rstrip:这里的r代表right, 用来去除结尾字符、空白符(包括\n、\r、\t、‘ ‘,即:换行、回车、制表符、空格)
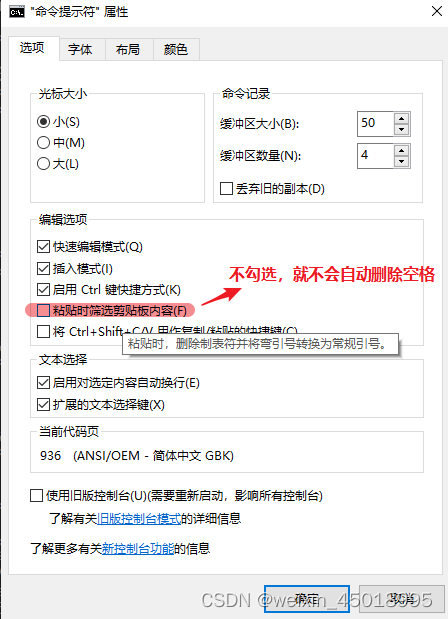
拷贝Python代码到命令行会发现空格被自动移除,会出现“IndentationError: unexpected indent”
解决方法很简单,只需在以下命令提示符的属性窗口中不要勾选粘贴时筛选剪贴板内容即可。
import re
pattern=r"<td>[a-zA-Z0-9]{9,10}</td>"
source=r"ewrwer<td>J060123</td>werwer<td>N08698697</td>dgfdsgsdf"
#search 返回第一个发现的匹配,然后结束,返回的result并不是一个list,不能使用len(result)来计算长度
#因为没有意义,最多只会返回了一个匹配
result=re.search(pattern, source)
result.group() #使用group()方法返回第一个匹配
#使用findall可以返回所有匹配,这里的result是一个包含了所有匹配的list
#可以用len(result)来计算成员数量
result=re.findall(pattern, source)
thefile=open("1234.htm", "r", encoding="utf8")
#read all data into the string oject thecontent
thecontent=thefile.read()
#include hypen(-), letter and digit, the length ranges from 5 to 15
pattern=r"<td>[-a-zA-Z0-9]{5,15}</td>"
#begin with SZ, followd by 3 digits
pattern1=r"<td>SZ\d{3}</td>"
#include hypen(-), letter and digit, the length ranges from 9 to 10
pattern2=r"<td>[-a-zA-Z0-9]{9,10}</td>"
#include hypen(-), letter and digit, the length must be 15
pattern3=r"<td>[-a-zA-Z0-9]{15}</td>"














 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









