






1. Python下载地址
2. Python安装(windows)
- 下载文件

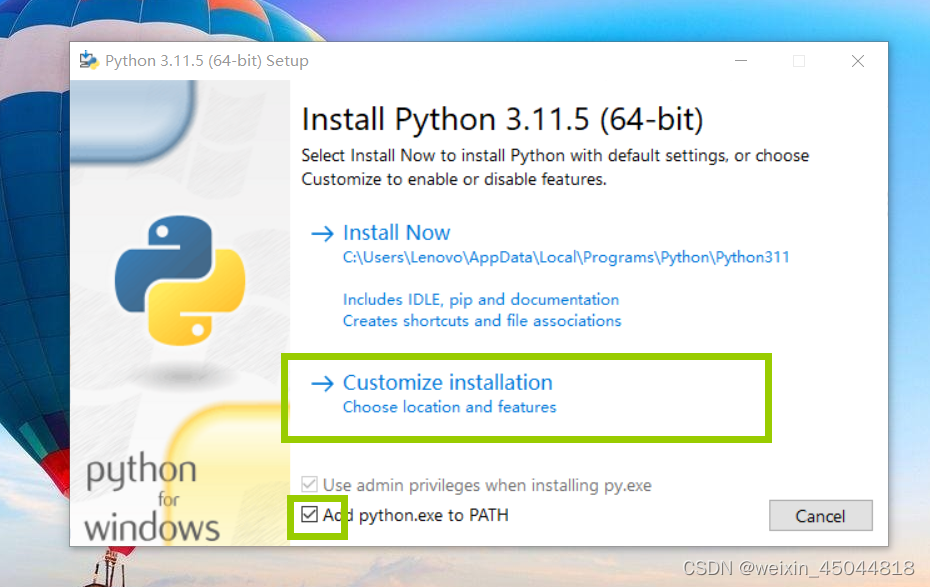
- 选择自定义安装,勾选添加python到path
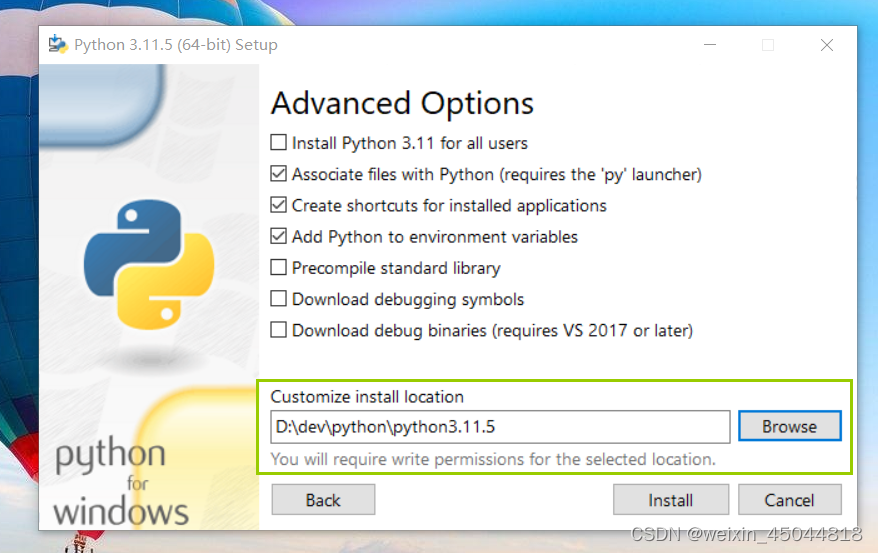
3. 自定义安装路径
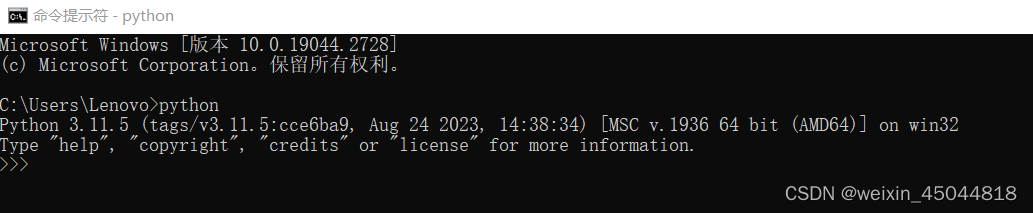
4. 校验
python
3. Python解释器
计算机是很笨的,它只认识0和1,如果我们要和它交流,那么就需要一个解释器,把我们需要的内容翻译成0和1给它。
那么python的解释器在哪里?
解释器的功能又是什么呢?
它的功能很简单: 1. 翻译代码 2. 提交给计算机执行
而python解释器的位置在(python的安装路径)
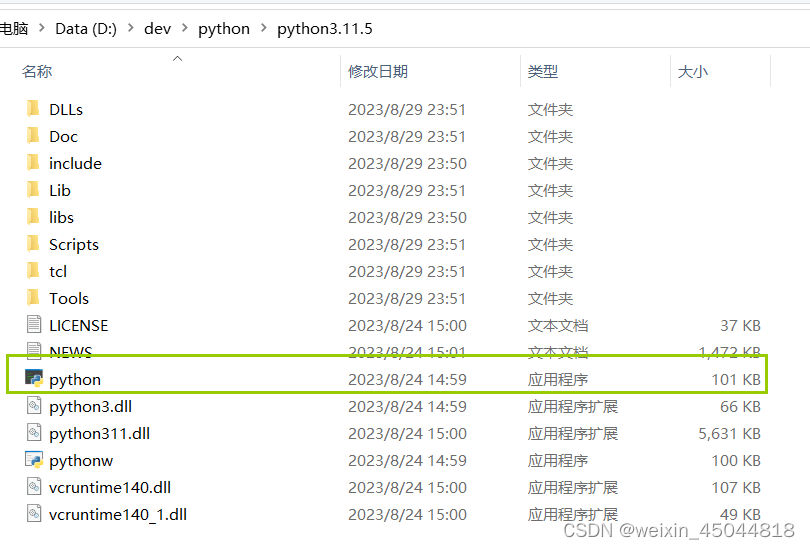
我们在cmd程序里,执行的python,就是里面的python程序
4. PyCharm
- 下载 暂时先用免费的吧(下载社区版,社区版免费)
5. 数据类型
- 数字类型
Number 整数(int) 浮点数(float) 复数(complex) 布尔(bool) - 字符串
String 描述文本的数据类型 - 列表
List 有序的可变序列 - 元组
Tuple 有序的不可变序列 - 集合
Set 无序不重复集合 - 字典
Dictionary 无需Key-Value集合
6. 注释
单行注释(# 开头)
# 这是单行注释哦
多行注释(一对三个双引号)
"""
这是多行注释哦
"""
7. 变量
name = "张三"
age = 16
money = 1378.89
print(f"这个人叫{name}, 年纪是{age},存款有{money}")
这个和js中的变量定义方式不同,js(let 和 const)
也不同与Java当中,前面有类型
python中的定义方式为: * 变量名 = 变量值 *
8. type()的使用
print(f"{type(name)}, {type(age)}, {type(money)}")

type()可以查看数据的类型
9. 常见的数据转化
int(x) 将x转化为一个整数
float(x) 将x转化为一个浮点数
str(x) 将x转化为一个字符串
如果int一个str类型,str不为数字,会报错
任何类型都可以转为字符串
字符串内必须只有数字才能转化成数字
10. 标识符
什么是标识符?
变量的名字
方法的名字
类的名字
这些名字,我们统一把它称之为标识符,用来做内容的标识。
所以,标识符:
是用户在编成的时候所使用的一系列名字,用于给变量,类,方法等命名。
Python中,标识符命名规则有3类:
内容限定(英文、中文(不推荐)、数字、下划线(_))数字不允许开头
大小写敏感
不可使用关键字
11. 字符串多种定义方法
str1 = '我是str1'
str2 = "我是str2"
str3 = """我是str3
我可以换行"""
三引号定义法: 和多行注释一样,同时支持换行操作。
使用变量接收它,它就是字符串。
不适用变量接受它,它就可以作为多行注释去使用。
注意:
单引号定义法,可以包含双引号。
多引号定义法,可以包含单引号。
可以使用转移字符()来将引号解除效用,变成普通字符串。
12. 字符串格式化
如果使用+号,无法完成不同类型变量的拼接。
那么还有其他方式吗?
占位符方式
str = "%d 变量 %5.2f" % (1, 3.67890)
print(str)
字符格式化-字符精度控制:
m,n 来控制数据的宽度和精度 例如%5.2f
m是5,n是2
m,控制宽度,要求是数字(很少使用),设置的宽度小于数字本身,不生效。如果大小数字本身,用空格补齐
n,控制小数点精度,要求是数字,会进行数字的四舍五入。
字符串格式化–快速写法
str1 = '我是str1'
str2 = "我是str2"
num = 100
print(f"{str1} --- {str2} --- {num}")
这种类型:
不理会类型
不做精度控制
支持表达式
13. input语句
使用input语句可以从键盘上获取其输入
name = input("请告诉我你的名字")
print(name)
注意:无论输入什么类型,获取到的都是字符串。
14. 布尔类型
True表示真
False表示假
True本质上是一个数字,记为1, False记作0
可以通过比较运算符得到布尔类型的数据
15. if判断
age = 18
if age < 18:
print("未成年")
elif age >= 18 & age < 30:
print("青年")
else:
print("成年")
归属于if语句的代码块,需在前方填充4个空格缩进
elif可以有多个
python中空格决定归属,比较重要
16. random随机数
import random
num = random.randint(0, 10)
print(num)
0到10之间的随机数
17. 循环
while
i = 0
while i < 10:
print(f"我今天做的第 {i+1} 件事情")
i += 1
小技巧:
使用
print(f"我今天做的第 {i+1} 件事情", end="")
end参数,可以将输出内容不换行
例子,九九乘法表:
i = 1
while i < 10:
j = 1
while j <= i:
print(f"{j} * {i} = {j*i} \t", end="")
j += 1
print("")
i += 1
for循环
for循环是一种轮询机制,逐个处理。
for i in [1, 2, 5, 8, 9]:
print(i)
字符串可以通过for,把每个字符打印出来
可以使用for的序列类型:
字符串
列表
元组
等
18. range
range(num)
获取一个从0到num结束的数字序列(不含num本身)
如:range(5) 的数据结果是[0, 1, 2, 3, 4]
for x in range(10):
print(x)
range(num1, num2)
从num1开始,num2结束(不含num2本身)
for x in range(3, 10):
print(x)
range(num1, num2, step)
从num1开始,num2结束,step为步长
for x in range(3, 10, 2):
print(x)
19. 跳过循环
continue:
跳过本次循环
for i in [1, 2, 5, 8, 9]:
if i % 2 == 0:
continue
print(i)
# 1 5 9
break:
结束循环
for i in [1, 2, 5, 8, 9]:
if i % 2 == 0:
break
print(i)
# 1
20. 函数
函数是组织好的,可重复使用的,用来实现某特定功能的代码。
def fun(a, b):
print(a + b)
fun(1, 2)
注意:
函数,必须先定义,后使用
参数不需要,可以省略
返回值不需要,可以省略
如果函数没有retutn语句,那么函数有返回值吗?
有的
Python中有个特殊的字面量:None。
无返回值的函数,实际上就是返回了: None这个字面量。
在if判断上,None相当于False
也可以用在定义变量上
name = None
21. 列表List
基础语法:
names = ["zhangsan", "lisi", "wangwu", 1, 2, 3]
支持不同类型,也支持嵌套
索引:
names = ["zhangsan", "lisi", "wangwu"]
print(names[0], names[-1])
支持正向索引,也支持反向索引,从-1开始
列表的常见操作方法
1. append
names = ["zhangsan", "lisi", "wangwu"]
names.append("yangxin")
print(names)
2. extend
names = ["zhangsan", "lisi", "wangwu"]
names.extend(["name1", "name2"])
print(names)
3. insert
names = ["zhangsan", "lisi", "wangwu"]
names.insert(1, "hhha")
print(names)
4. del
names = ["zhangsan", "lisi", "wangwu"]
del names[1]
print(names)
5. pop
names = ["zhangsan", "lisi", "wangwu"]
names.pop(1)
print(names)
6. remove
names = ["zhangsan", "lisi", "wangwu"]
names.remove("lisi")
print(names)
7. clear
names = ["zhangsan", "lisi", "wangwu"]
names.clear()
print(names)
8. index
names = ["zhangsan", "lisi", "wangwu"]
print(names.index("zhangsan"))
找不到报错
9. count
names = ["zhangsan", "lisi", "wangwu"]
print(names.count("zhangsan"))
10. len
names = ["zhangsan", "lisi", "wangwu"]
print(len(names))
列表特点
可以容纳多个元素(2**63 - 1)
有序存储
允许数据重复
可以修改
可以容纳不同类型元素
22. 元组
为什么需要元组?
列表是可以修改的
如果需要传递的信息,不可修改,列表就不合适了
元组和列表一样,但是最大的不同点就在于:
列表可以修改
元组一旦定义完成,不可修改
基础使用:
names = ("zhangsan", "lisi", "wangwu")
元组的常见操作方法
1. index
names = ("zhangsan", "lisi", "wangwu") print(names.index("zhangsan"))### 13. 文件
2. count
names = ("zhangsan", "lisi", "wangwu")
print(names.count("zhangsan"))
3. len
names = ("zhangsan", "lisi", "wangwu")
print(len(names))
4. 不可以修改元组的内容。否则会直接报错
Traceback (most recent call last):
File "D:\a_projects\python-test\my_package\test1.py", line 56, in <module>
names[0] = "11"
~~~~~^^^
TypeError: 'tuple' object does not support item assignment
元组的特点:
和list基本相同(有序、任意数量元素、允许重复元素)
在于不可修改
直接for循环
23. 字符串的相关操作
1. replace
str = "hello world hello zhangsan hello lisi"
print(str.replace("hello", "hi"))
替换字符串中全部的
不修改字符串本身,得到了一个新的字符串
2. split
str = "hello world hello zhangsan hello lisi"
print(str.split(" "))
不修改字符串本身,而是得到了一个新的列表对象
3. strip
去前后空格
str = " hello world hello zhangsan hello lisi "
print(str.strip())
去前后指定字符串
str = "iphello world hello zhangsan hello lisi pi"
print(str.strip("ip"))
# hello world hello zhangsan hello lisi
4. index、count、len等方法
字符串有如下特点:
长度任意
支持下标索引
允许重复字符串存在
不可以修改(增加或删除元素等)
支持for循环
24. 序列
序列是指: 内容连续、有序,可使用下标的一类数据容器。
列表、元组、字符串,均可以视为序列。
切片
序列支持切片
语法:序列[起始下标:结束下标:步长]
起始下标表示从何处开始,可以留空,留空视为从头开始
结束下标(不含):表示何处结束,可以留空,留空视为截取到结尾
步长:依次取元素的间隔
基础语法:
# 步长默认为1
list1 = [1, 2, 3, 4, 5, 6, 7, 8]
print(list1[1:5])
# [2, 3, 4, 5]
# 步长为2,从开始到结束
tuple2 = (1, 5, 8, 9, 10, 6, 8)
print(tuple2[::2])
# (1, 8, 10, 8)
# 从3开始,到1结束(不包含1)
list3 = [1, 2, 3, 4, 5, 6, 7, 8]
print(list3[3:1:-1])
# [4, 3]
25. 集合
集合:
不支持重复,无序。
基础语法:
set1 = {1, 2, 3, 6, 7, 5, 3, 1}
print(set1)
#{1, 2, 3, 5, 6, 7}
集合的常见操作
1. add
集合是没有下标的,不支持下标访问
set1 = {1, 2, 3, 6, 7, 5, 3, 1}
set1.add(10)
print(set1)
2. remove
set1 = {1, 2, 3, 6, 7, 5, 3, 1}
set1.remove(2)
print(set1)
####### 3. pop
从集合中随机取出一个元素, 同时集合被修改,元素被移除
set1 = {"hello", "world", "!", 1, 2}
print(set1.pop(), set1)
# ! {2, 1, 'world', 'hello'}
4. clear
清空集合
set1 = {"hello", "world", "!", 1, 2}
print(set1.clear(), set1)
# None set()
5. difference(集合1有,集合2没有)
set1 = {"hello", "world", "!", 1, 2}
set2 = {"hello", "xiaoming", 2}
print(set1.difference(set2))
# {1, '!', 'world'}
结果: 得到一个新集合,集合1和集合2不变
6. difference_update
set1 = {"hello", "world", "!", 1, 2}
set2 = {"hello", "xiaoming", 2}
print(set1.difference_update(set2), set1, set2)
# None {1, 'world', '!'} {2, 'hello', 'xiaoming'}
结果: 集合1改变,集合2不变
7.union
两个集合合并,不会改变集合1和集合2
set1 = {"hello", "world", "!", 1, 2}
set2 = {"hello", "xiaoming", 2}
print(set1.union(set2), set1, set2)
集合的特点:
可以容纳多个元素
可以容纳不同类型的元素
数据是无序存储的
不允许数据重复
可以修改(增加或删除元素等)
支持for循环
26. 字典
字典的定义,同样使用{},不过存储的元素是一个个:键值对
不可以使用下标
基础使用:
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
print(dict1)
字典的常见操作
1. 增加
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
dict1['hh'] = 66
print(dict1)
2. 更新
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
dict1['zhangsan'] = 66
print(dict1)
# {'zhangsan': 66, 'lisi': 20, 'wangwu': 88}
3. 删除pop
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
dict1.pop("zhangsan")
print(dict1)
# {'lisi': 20, 'wangwu': 88}
4. 清空clear
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
dict1.clear()
print(dict1)
# {}
5. 获取
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
print(dict1["zhangsan"])
# 100
6. 获取全部的key
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
print(dict1.keys())
# dict_keys(['zhangsan', 'lisi', 'wangwu'])
7. len
dict1 = {"zhangsan": 100, "lisi": 20, "wangwu": 88}
print(len(dict1))
# 3
字典的特点:
可以容纳多个数据
可以容纳不同类型的数据
每一份数据都是KeyValue键值对
可以通过Key获取到Value,Key不可重复
不支持下标索引
可以修改(增加或删除更新元素)
支持for,不支持while
27.数据容器的通用操作
1. len
print(len("hello world"), len([1, 2, "hello"]), len((1, 2, "hello", 5, 9)), len({1, 2, 3}), len({"hello": 1, "world": 2}))
# 11 3 5 3 2
2. max/min
print(max("hello world"), max([1, 2, 3]), max((1, 2, 3, 5, 9)), max({1, 2, 3}), max({"hello": 1, "world": 2}))
# w 3 9 3 world
注意:
print(max[1, 2, "hello"])
# 报错
Traceback (most recent call last):
File "D:\a_projects\python-test\my_package\test1.py", line 77, in <module>
print(max[1, 2, "hello"])
~~~^^^^^^^^^^^^^^^
TypeError: 'builtin_function_or_method' object is not subscriptable
3. list(), tuple(), str(), set()方法
28. 函数返回值、参数
1. 多返回值
根据返回值的顺序,写对应顺序的多个变量接收即可
def fun1():
return "hello", "world", 1
str1, str2, num = fun1()
print(str1, str2, num)
变量之间用逗号隔开
支持不同类型的数据return
2.位置参数
def user_info(name, age, sex):
print(f"名字为{name}, 年龄是{age}, 性别{sex}")
user_info("zhangsan", 26, "男")
传递的参数和定义的参数的顺序以及个数必须一致
3. 关键字参数
def user_info(name, age, sex):
print(f"名字为{name}, 年龄是{age}, 性别{sex}")
user_info(age=19, name="li", sex="男")
# 可以混用
user_info("aa", age=109, sex="男")
注意:
函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
4. 缺省参数
缺省参数:也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值。
注意:
所有位置参数必须出现在默认参数的前面,包括函数定义和调用
def user_info(name, age, sex = "无"):
print(f"名字为{name}, 年龄是{age}, 性别{sex}")
user_info("aa", age=109)
# 名字为aa, 年龄是109, 性别无
5. 位置不定长
def user_info(*args):
print(args)
user_info(1, 2, 7, 0, 10)
# (1, 2, 7, 0, 10)
传递的所有参数都被会变量args变量收集,它会根据传进参数的位置合并成一个元组,args是元组类型,这就是位置传递
6. 位置不定长
def user_info(**kwargs):
print(kwargs)
user_info(name="zhangsan", age=25, sex="男")
# {'name': 'zhangsan', 'age': 25, 'sex': '男'}
参数是"键=值"形式的情况下,所有的"键=值"都会被kwargs接受,同时会根据"键=值"组成字典。
29. 文件
1. 文件编码
计算机中许多可用的编码:
UTF-8
GBK
Big5
等
2. 查看编码
可以使用windows自带的记事本功能,右下角可以看到文件编码

UFT-8是目前全国通用的编码格式,
3. 文件的读取操作
对于文件的操作,基础分为三步骤:
- 打开
- 读写文件
- 关闭文件
打开文件:
f = open('python.txt', 'r', encoding='UTF-8')
name: 是要打开的目标文件名的字符串(可以包含文件的具体路径)
mode:设置打开文件的模式(访问模式): 只读(r)、写入(w)、追加(a)等。w、a文件不存在,会创建新文件。
encoding:编码格式(推荐使用UTF-8)
另一种打开文件方式: with open语法
with open('python.txt', 'r', encoding='UTF-8') as f:
print(f"{f.readlines()}")
通过在with open的语句块中对文件进行操作
可以在操作完成后自动关闭close文件,避免遗忘掉close方法
读操作相关方法:
-
read())方法
文件对象.read(num)
num表示从文件读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
-
readlines()方法
readlines可以按照行的方式把整个文件的内容进行一次性的读取,并且返回的是一个列表,其中每一行的数据为一个元素。
-
readline()方法
每次读取一行
-
循环读取
使用for循环每次读取一行
读取方法调用多次,会记住你上一次的读取位置,接着后面去读,很特别哈哈哈!!!
关闭文件:
close()关闭文件对象
如果不调用close方法,也不停止程序,程序会对这个文件一直进行调用
文件的写入/追加(a)操作:
# 1. 打开文件
f = open('python.txt', 'w')
# 2. 写入文件
f.write('hello world')
# 3. 内容刷新
f.flush()
注意:
-
直接调用write,内容并未真正写入文件,而是会积累在程序的内存中,称之为缓冲区
-
当调用flush的时候,内容会真正写入文件
-
这样做是为了避免频繁的操作硬盘,导致效率下降(积攒一堆,一次性写入硬盘)
-
close()内置了flush()功能
30. 类
class Student:
name = None
age = None
def sayhello(self):
print(f"我叫{self.name}, 年龄{self.age}, 你好")
stu = Student()
stu.name = "zhangsan"
stu.age = 25
stu.sayhello()
类中定义的属性,我们称为成员变量
类中定义的方法,我们称为成员方法
注意:
self出现在形参列表中,但是不占用参数位置,无需理会
只有通过self,成员方法才能访问类的成员变量
1. 构造方法
class Student:
name = None
age = None
def __init__(self, name, age):
self.name = name
self.age = age
print(f"我叫{self.name}, 年龄{self.age}, 你好")
stu = Student("zhangsan", 19)
注意:
在创建类对象(构建类)的时候,会自动执行。
在创建类对象(构造类)的时候,将传入参数自动传递给__init__方法使用
2. 魔术方法
1. __ str __
class Student:
name = None
age = None
def __init__(self, name, age):
self.name = name
self.age = age
print(f"我叫{self.name}, 年龄{self.age}, 你好")
def __str__(self):
return f"{self.name} -- {self.age}"
stu = Student("zhangsan", 19)
print(stu)
# zhangsan -- 19
如果不重写这个魔术方法,会输出内存地址
内存地址没多大作用, 我们可以通过__str__方法,控制类转化为字符串的行为。
2. __ lt __(小于或大于)
class Student:
name = None
age = None
def __init__(self, name, age):
self.name = name
self.age = age
print(f"我叫{self.name}, 年龄{self.age}, 你好")
def __lt__(self, other):
return self.age < other.age
stu1 = Student("zhangsan", 19)
stu2 = Student("zhangsan", 20)
print(stu1 < stu2)
# True
小于符号比较方法
3. __ le __(小于等于或大于等于)
4. __ eq __(等于)
31. 封装
封装表示的是,将现实事物的:
属性
行为
封装到类中,描述为:
成员变量
成员方法
从而完成程序对现实世界事务的描述。
类的私有成员
class Phone:
IMERI = None
__current_voltage = None
def __call_by_5G(self):
print('使用5G通话')
phone = Phone()
print(phone.__current_voltage)
phone.__call_by_5G()
私有成员: 变量以__开头
私有方法:方法以__开头
私有方法无法直接被类对象使用
私有变量无法获取值
伪私有属性:
https://blog.csdn.net/weixin_44226181/article/details/128782105
32. 继承
单继承
class Phone:
IMEI = None
producer = None
def call_by_4g(self):
print("4G童话")
def Phone2023(Phone):
face_id = True
def call_by_5G(self):
print("5G通话")
多继承在类后继承多个类,
class 类名(父类1, 父类2, … 父类N):
类内容体
多个父类中,如果有相同的成员,那么默认以继承顺序(从左到右)为优先级
即:先继承的保留,后继承的覆盖
复写
子类继承父类的成员属性和成员方法后,如果对其“不满意”,那么可以进行复写。
即:在子类中重新定义同名的属性或方法。
class MobilePhone: #基类
def touch(self):
print('我能提供屏幕触控操作的功能')
class HTC(MobilePhone): #派生类
def touch(self):
MobilePhone.touch(self)
print('我也能提供多点触控的操作方式')
#产生子类对象
u11 = HTC()
u11.touch()
调用父类同名方法
MobilePhone.touch(self)
super().touch()
一:
父类名.成员变量
父类名.成员方法()
二:
super().成员变量
super().成员方法()
33. 类型注解
Python3.5版本引入了类型注解,以方便静态类型检查工具,IDE等第三方工具。
类型注解:在代码中涉及数据交互的地方,提供数据类型的注解(显式的说明)。
主要功能:
- 帮助第三方IDE工具(如PyCharm)对代码进行类型判断,协助做代码提示
- 帮助开发者自身对变量进行类型注解
1. 基础类型注解
name: str = "zhangsan"
2. 类的类型注解
phone: MobilePhone = MobilePhone()
3. 容器类型注解
list1: list[int] = [1, 2]
tuple1: tuple[int, str] = [1, "hh"]
set1: set[int] = {1, 2}
dict1: dict[str, int] = { "key": 10 }
4. 注释中注解
var_1 = random.randint(1, 10) # type: int
5. 类型注解的限制
并不会做真正的对类型做验证和判断
也就是,类型注解仅仅是提示性的,不是决定性的
var_1: str = 11
这样也不会报错的
6. 函数的类型注解
def fun1(name: str, age: int) -> str:
return f"名字是{name}, 年龄是{age}"
print(fun1("zhangaan", 15))
34. 异常
1. 捕获异常(全部)
try:
f = open('test1.txt', 'r')
except:
f = open('test1.txt', 'w')
print('出现异常了,以w模式去打开,这样就没有异常了')
try:
f = open('test1.txt', 'r')
except Exception as e:
2. 捕获指定的异常
except NameError as e:
3. 捕获多个异常
except (NameError, IsADirectoryError):
异常还有else和finally语句
并且异常是具有传递性的,可以在调用的最顶层去捕获异常
4. Python的模块
模块就是一个python文件,里面有类、函数、变量,我们可以拿来用。
基础使用:
import random
random.randint(1, 10)
from random import randint
randint(1, 10)
from random import *
randint(1, 10)
还可以起别名as
5. 自定义模块
可以新建立一个python文件,在里面定义自己的函数
module_test1.py
def add(a, b):
return a + b
main.py
import module_test1
print(f'{module_test1.add(1, 2)}')
自定义模块测试语句(只有在运行这个模块文件的时候才会调用执行):
if __name__ == '__main__':
print(f'{add(1, 20)}')
# 还有个__all__ 限制*的问题,了解
6. Python包
从物理上看,python包就是一个文件夹,在文件夹下包含了一个__init__.py文件。该文件夹用于包含多个模块文件。
从本质上看,包的本质仍然是模块。
通过PyCharm建包,跟普通文件夹的区分是有__init__.py文件。
安装第三方包:
就是其他人写完的,可以提高你程序效率的包。
pip install numpy
如果感觉速度太慢,可以使用国内的源:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
同时在PyCharm中也可以下载
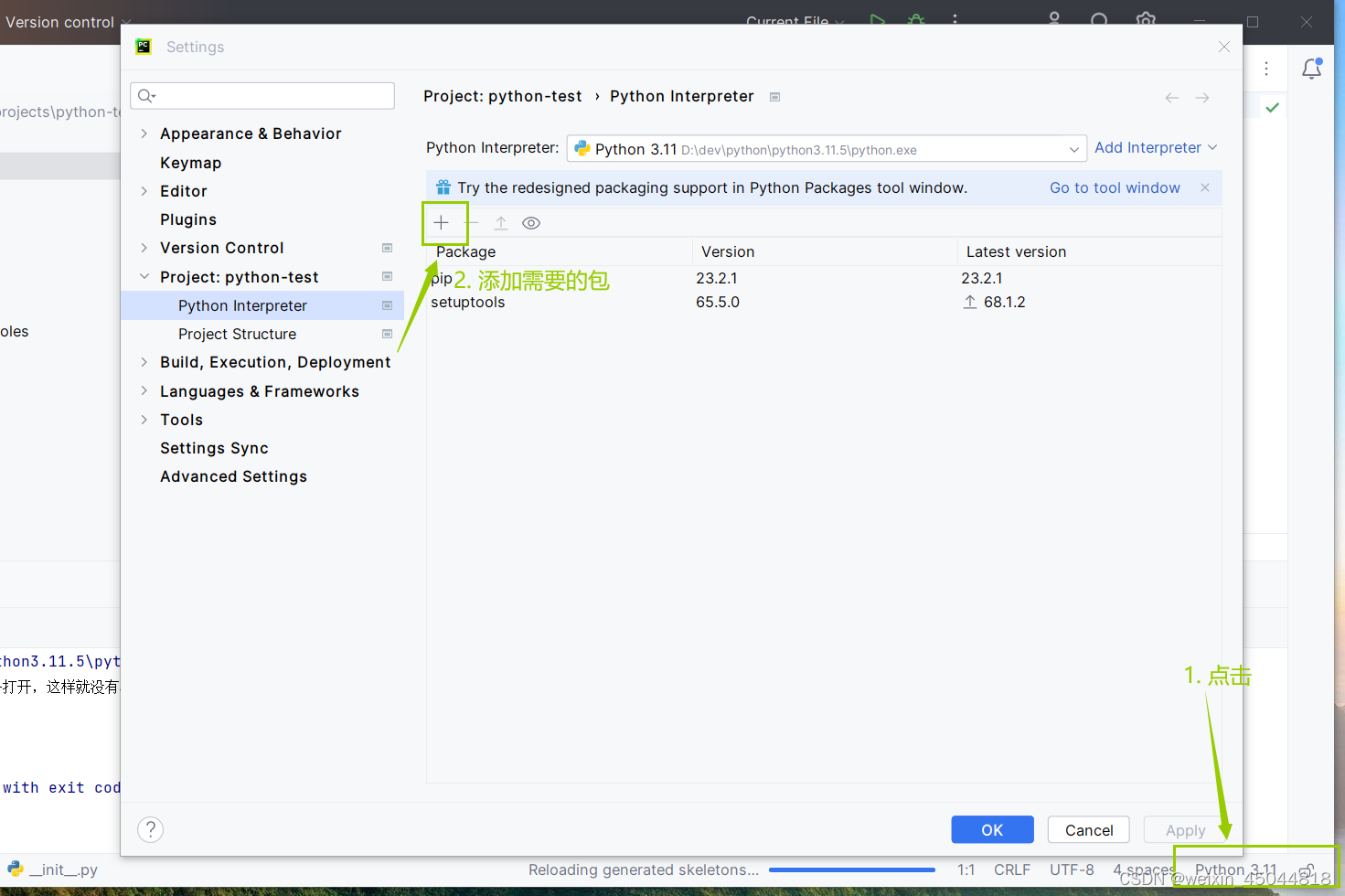
35. PySpark
1. spark是什么
是一款分布式的计算器,用于调度成百上千的服务器集群,计算机TB、PB及至EB级别的海量数据。
2. 构造PySpark执行环境入口对象
# 1. 导包
from pyspark import SparkConf, SparkContext
# 2. 创建sparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
# 3. 基于sparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
# 4. 打印pyspark运行版本
print(sc.version)
# 5. 停止运行
sc.stop()
注意:运行此程序需要提前安装jdk
3. PySpark的编程模型
主要分为三大步骤:
- 数据输入
通过SpartContext类对象的成员方法,完成数据的读取操作,读取后得到RDD(弹性分布式数据集)类对象 - 数据处理计算
通过RDD类对象的成员方法,完成各种数据计算的需求 - 数据输出
将处理完成RDD对象,调用各种成员方法完成写出文件,转化为list等操作
4. Python数据容器转为RDD对象
# 3. 基于sparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["111", "222"])
# 输出RDD内容
print(type(rdd), rdd.collect())
也支持读取文件转化为RDD对象
rdd = sc.textFile("文件路径")
5. 数据计算部分
- map
map算子是将RDB的数据一条条处理,返回新的RDD。
# 找不到python解释器,不写会报错
import os
os.environ["PYSPARK_PYTHON"] = "D:\dev\python\python3.11.5/python.exe"
... # 省略代码
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd = rdd.map(x: x * 10)
... # 省略代码
- faltMap
和map一样,多了一个解除嵌套功能
rdd = sc.parallelize(["hello world", "hhha hhh", "1 2 3"])
rdd = rdd.flatMap(lambda x: x.split(" "))
- reduceByKey
针对kv型(二元元组)RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内的聚合操作
rdd = sc.parallelize([("a", 1), ("b", 3), ("a", 1)])
rdd = rdd.reduceByKey(lambda a, b: a + b)
- filter
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd = rdd.filter(lambda x: x % 2 == 1)
- distinct
去重操作
rdd = sc.parallelize([1, 2, 3, 4, 5, 1, 3, 7, 9])
rdd = rdd.distinct()
6. 数据输出部分
- collect
将RDD全部数据转化为list - reduct
对RDD进行两两聚合
rdd = sc.parallelize(range(1, 10))
print(rdd.reduce(lambda a,b : a+ b))
- take
rdd = sc.parallelize(range(1, 10))
print(rdd.take(3))
- count
rdd = sc.parallelize(range(1, 10))
print(rdd.count())
- 输出到文件中
saveAsTextFile,设置分区为1
需要配置Hadoop环境















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









