






目录
链表
2024.5.8
160 相交链表


(a+c)+b=(b+c)+a 两个指针就会相遇



2024.5.9
206 反转链表
使用一个前驱节点,一直迭代将pre和cur之间的指针翻转,直到cur指向null时结束

234 回文链表
- 快慢指针,找到中点结点。
- 翻转中点结点(slow)到链表结尾的所有结点。
- 普通遍历比较翻转后的链表,和原始链表头结点到中点结点的元素是否相等。


141 环形链表
快慢指针的初始位置不一样;慢在第一个,快在第二个
!只是用来判断快慢指针是否会相遇,相遇的地方不知道 !

2024.5.10
142 环形链表 Ⅱ
条件跟上面的不一样,所以可以让fast和slow初始都在head

21 合并两个有序链表
时间复杂度:O(n+m),最多循环m+n次。每次加入一个节点;
空间复杂度:O(1),创建节点只占用常数级别的空间

2024.5.11
2 两数相加
链表倒着看是这个数的高位到低位,长度不相同还是从第一个节点开始对应相加,每次相加考虑上一个的进位,并且更新这次的进位,如果有一个为null的时候,就将其值取为0继续计算,直到两个链表都为null;最后还要考虑最高位的进位。有一个虚拟头节点保持不动

19 删除链表的倒数第N个结点
双指针,虚拟头节点

2024.5.12
24 两两交换链表中的节点
虚拟头节点;双指针
25 K个一组翻转链表
- 找到待翻转的k个节点(注意:若剩余数量小于 k 的话,则不需要反转,因此直接返回待翻转部分的头结点即可)。
- 对其进行翻转。并返回翻转后的头结点(注意:翻转为左闭右开区间,所以本轮操作的尾结点其实就是下一轮操作的头结点)。
- 对下一轮 k 个节点也进行翻转操作。
- 将上一轮翻转后的尾结点指向下一轮翻转后的头节点,即将每一轮翻转的k的节点连接起来。


2024.5.13
138 随机链表的复制
算法流程:
- 若头节点 head 为空节点,直接返回 null。
- 初始化: 哈希表 dic , 节点 cur 指向头节点。
- 复制链表:a. 建立新节点,并向 dic 添加键值对 (原 cur 节点, 新 cur 节点) 。b. cur 遍历至原链表下一节点。
- 构建新链表的引用指向:构建新节点的 next 和 random 引用指向。cur 遍历至原链表下一节点。
- 返回值: 新链表的头节点 dic[cur] 。

148 排序链表
使用归并排序,时间复杂度为O(nlogn);使用迭代法,空间复杂度为O(1)
主要是将step从1,2,4,8...,遍历全部链表每次按这个长度进行两两归并
关键是断链和合并
第一次,while循环将链表依次分为1长度的段,并两两合并,合并之后使用pre.next进行连接
得到的是长度为 2 的有序链表的连接
第二次,while循环将链表依次分为2长度的段,并两两合并,合并之后使用pre.next进行连接
得到的是长度为 4 的有序链表的连接
...直到整个有序



2024.5.14
146 LRU缓存
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
对于 get 操作,首先判断 key 是否存在:
- 如果 key 不存在,则返回 −1;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
对于 put 操作,首先判断 key 是否存在:
- 如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
- 如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
访问哈希表的时间复杂度为 O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1) 时间内完成。




二叉树
把之前做过的又做一遍,都忘记了!
94 二叉树的中序遍历
- 递归:隐式地维护栈

- 迭代:明确创建一个栈

2024.5.15
104 二叉树的最大深度
树的后序遍历 / 深度优先搜索往往利用 递归 或 栈 实现
树的层序遍历 / 广度优先搜索往往利用 队列 实现
- 递归实现(深度优先搜索 DFS)

- 层序遍历(广度优先搜索 BFS)
记录每层的长度,只要size>0,就一直将第一个节点poll出,size--,并将这个节点的左右子节点offer加入队列;直到size为0这一层结束,层数++;最终队列为空结束。
 226 翻转二叉树
226 翻转二叉树
后序遍历递归翻转

101 对称二叉树
即判断左右两个子树是否可以相互翻转。需要收集左右孩子的信息,然后返回给父节点,才能知道是否是对称二叉树,所以需要后序遍历。
一个返回值为boolean的compare函数,参数为左右两个子树。
结束条件:左空右不空,左不空右空;左右都空,左右不空但不相等,这时只剩下一种相等的情况,递归比较左的左和右的右以及左的右和右的左,最后如果两个都为true则返回true。(这时说明以这两个为节点的树是互相翻转的)

2024.5.16
543 二叉树的直径
二叉树的 直径 是指树中任意两个节点之间最长路径的 长度

102 二叉树的层序遍历
二级列表,队列实现

108 将有序数组转化为二叉搜索树
取根节点之后,如果左右子树长度是偶数的话,取最中间的左边还是右边作为根节点都是可以的,可以构造不同的二叉树;明确递归的左右区间定义

98 验证二叉搜索树
引入前驱节点pre,中序遍历递归

2024.5.17
230 二叉树中第k小的元素
采用中序遍历,用栈存储节点,后进先出,root不为空或者栈不为空的时候进行循环,如果root不为空,就要将root进栈,一直向左遍历;然后将栈顶元素给pop,这时候pop出的就是比较小的节点,k--,判断k是否等于0,若等于 break结束循环,若不等,将root赋值为其右节点(相当于有个回溯的过程,pop出这个节点,就要把其右孩子进栈,进行循环判断)

199 二叉树的右视图
层序遍历记录每层的最后一个节点的值即可

114 二叉树展开为链表

2024.5.18
105 从前序与中序遍历构造二叉树

2024.5.19
437 路径总和
定义节点的前缀和为:由根结点到当前结点的路径上所有节点的和。curr-targetSum能在HashMap中找到,说明从找到的那个节点的下一个节点到当前节点的路经总和为targetSum。
使用HashMap存储,key为节点的前缀和,value为和出现的次数。
节点的值-10^9 <= Node.val <= 10^9,总和curr可能会很大,因此用Long

236 二叉树的最近公共祖先
要想从下往上找,并向上返回,可以使用后序遍历递归
因为题目中说每个节点的值都不一样,并且p!=q,因此有两种情况:
- p和q分别在一个子树的左右子树中,那么左和右遍历结果都不为空(左和右中必分别有p和q),则可以返回该root
- 如果这个root就是p或q,那么就返回root,不用管该节点的下面是不是有另一个值;如果有就是向上传递root;如果没有,就又成为了第一种情况。

124 二叉树中的最大路径和
节点的最大贡献值:在以该节点为根节点的子树中寻找以该节点为起点的一条路径,使得该路径上的节点值之和最大。
- 空节点的最大贡献值等于0。
- 非空节点的最大贡献值等于节点值与其子节点中的最大贡献值之和(对于叶节点而言,最大贡献值等于节点值)。
后序遍历,先看左右子树再考虑加不加入当前节点的最大路径和中
每次更新最大路径和的值,返回的是每个节点的最大贡献值以便上层计算

图论
递归,深度优先搜索 dfs(深搜三部曲)
- 确认递归函数,参数
- 确认终止条件
- 处理目前搜索节点出发的路径
队列,广度优先搜索 bfs(层序遍历)
2024.5.20
200 岛屿数量
DFS,BFS,并查集,基础题目
- 目标是找到矩阵中 “岛屿的数量” ,上下左右相连的 1 都被认为是连续岛屿。
- dfs方法: 设目前指针指向一个岛屿中的某一点 (i, j),寻找包括此点的岛屿边界。
- 从 (i, j) 向此点的上下左右 (i+1,j),(i-1,j),(i,j+1),(i,j-1) 做深度搜索。
- 终止条件:
- (i, j) 越过矩阵边界;
- grid[i][j] == 0,代表此分支已越过岛屿边界。
- 搜索岛屿的同时,执行 grid[i][j] = '0',即将岛屿所有节点删除,以免之后重复搜索相同岛屿。
- 主循环:
- 遍历整个矩阵,当遇到 grid[i][j] == '1' 时,从此点开始做深度优先搜索 dfs,岛屿数 count + 1 且在深度优先搜索中删除此岛屿。
- 最终返回岛屿数 count 即可。

2024.5.21
994 腐烂的橘子
就是求腐烂橘子到所有新鲜橘子的最短路径 采用层序遍历 bfs,一层一层进行污染



2024.5.24
207 课程表





208 实现Trie(前缀树)


回溯
回溯三部曲:
- 递归函数参数
- 递归函数终止条件
- 单层搜索的逻辑
46 全排列
回溯法:一种通过探索所有可能的候选解来找出所有的解的算法。如果候选解被确认不是一个解(或者至少不是最后一个解),回溯算法会通过在上一步进行一些变化抛弃该解,即回溯并且再次尝试。

2025.5.25
78 子集
- 时间复杂度:O(n×2^n)。一共 2^n个状态,每种状态需要 O(n)的时间来构造子集。
- 空间复杂度:O(n)。临时数组 t 的空间代价是 O(n),递归时栈空间的代价为 O(n)。

17 电话号码的字母组合
首先创建一个字符串列表作为输出,用哈希表存储每个数字对应的字母,创建StringBuffer类型的字符串不断加入字母;从下标为0开始,找到对应的数字,从哈希表中取出对应的字母字符串,并记录字符串长度,对于每个字母依次进行加入操作,并在这个情况下继续下一个位置;递归之后进行回溯删去这个字母;当索引等于digits数字字符串的长度时,完成一个字符串组合,并加入列表中。


2024.6.3
39 组合总和
画树形图,深度优先遍历,完加入这个数遍历后再移除进行回溯
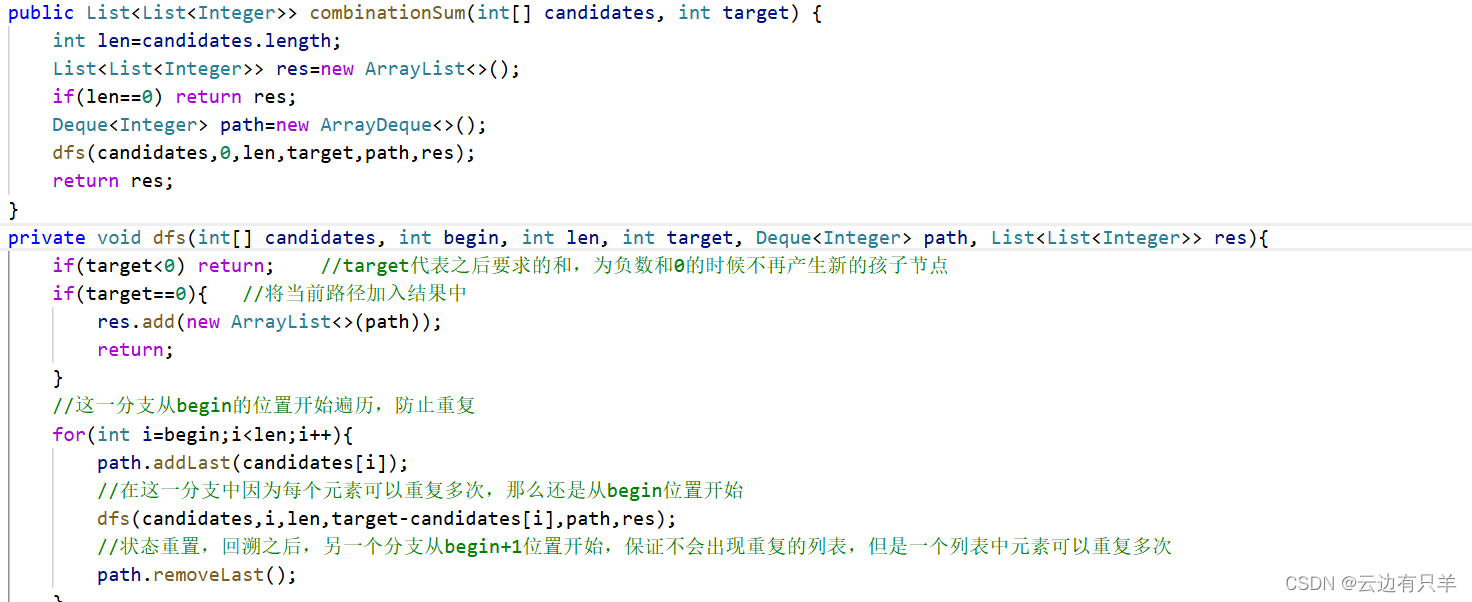
22 括号生成

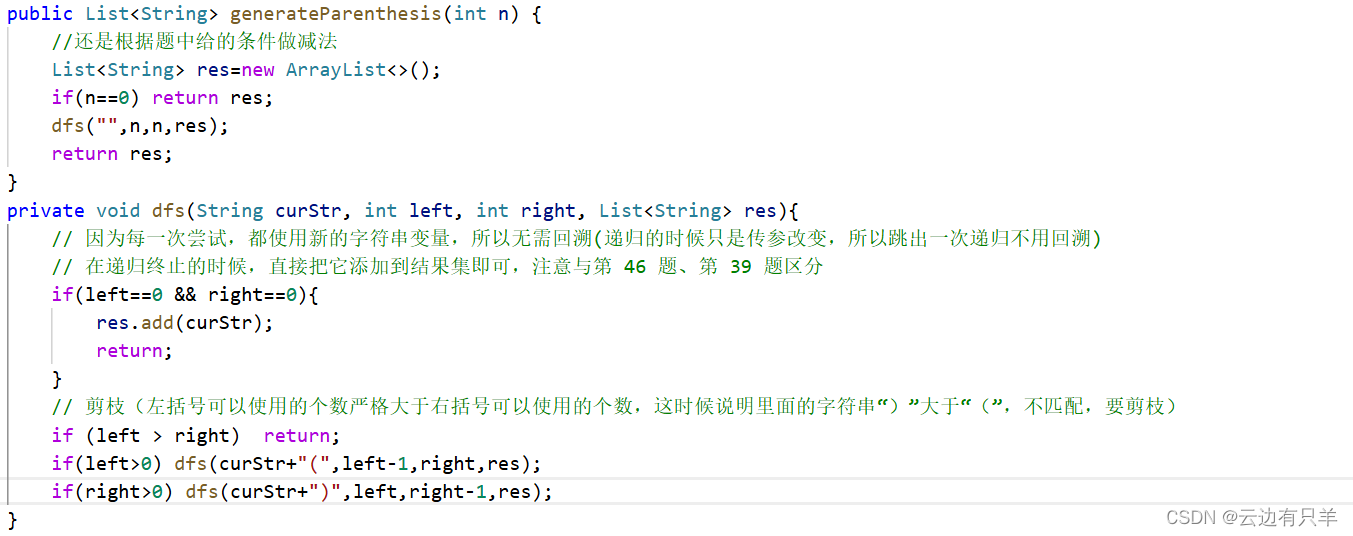
2024.6.4
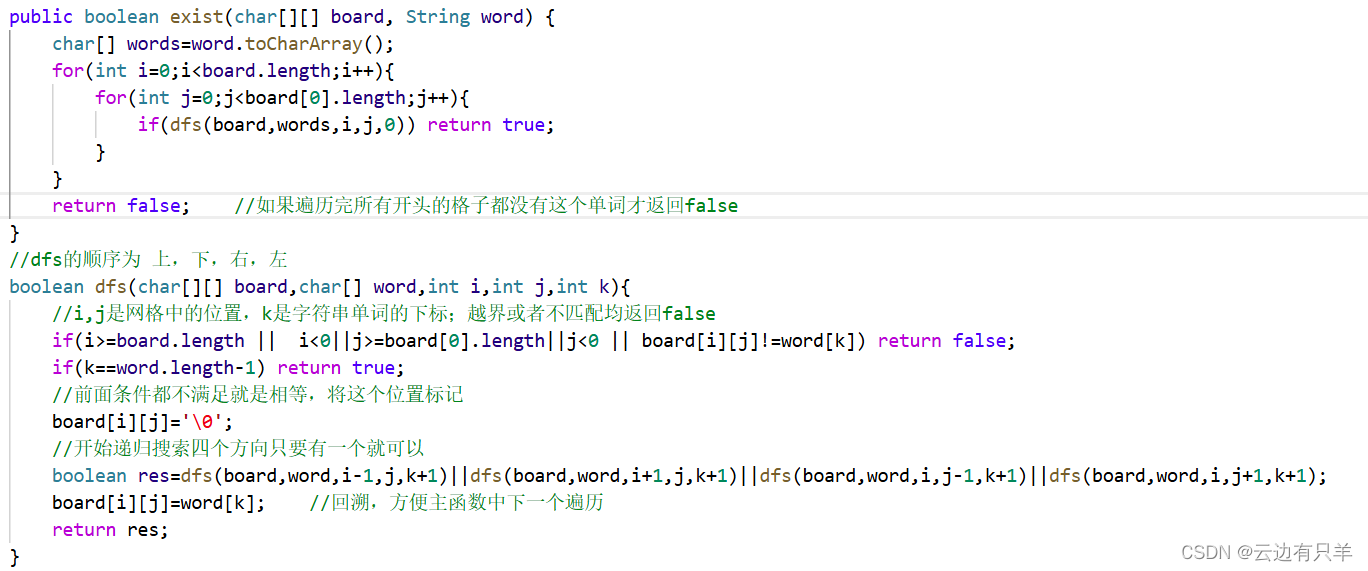
79 单词搜索
深度优先搜索+剪枝
131 分割回文串
切割问题和组合问题的回溯过程差不多



N皇后困难题先不写了,之后再补。















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









