










ImageNet竞赛自2010年以来,一直是计算机视觉中监督学习进展的指向标。
这些模型包括:
-
AlexNet。它是第一个在大规模视觉竞赛中击败传统计算机视觉模型的大型神经网络;
-
使用重复块的网络(VGG)。它利用许多重复的神经网络块;
-
网络中的网络(NiN)。它重复使用由卷积层和1x1卷积层(用来代替全连接层)来构建深层网络;
-
含并行连结的网络(GoogLeNet)。它使用并行连结的网络,通过不同窗口大小的卷积层和最大汇聚层来并行抽取信息;
-
残差网络(ResNet)。它通过残差块构建跨层的数据通道,是计算机视觉中最流行的体系架构;
-
稠密连接网络(DenseNet)。它的计算成本很高,但给我们带来了更好的效果。
7.1. 深度卷积神经网络(AlexNet)
经典机器学习的流水线:
-
获取一个有趣的数据集。在早期,收集这些数据集需要昂贵的传感器(在当时最先进的图像也就100万像素)。
-
根据光学、几何学、其他知识以及偶然的发现,手工对特征数据集进行预处理。
-
通过标准的特征提取算法,如SIFT(尺度不变特征变换)和SURF(加速鲁棒特征)或其他手动调整的流水线来输入数据。
-
将提取的特征送入最喜欢的分类器中(例如线性模型或其它核方法),以训练分类器。
7.1.1. 学习表征
特征本身应该被学习,在合理地复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数.
在机器视觉中,最底层可能检测边缘、颜色和纹理。
事实上,Alex Krizhevsky、Ilya Sutskever和Geoff Hinton提出了一种新的卷积神经网络变体AlexNet。
在2012年ImageNet挑战赛中取得了轰动一时的成绩
AlexNet的更高层建立在这些底层表示的基础上,以表示更大的特征,如眼睛、鼻子、草叶等等。
而更高的层可以检测整个物体,如人、飞机、狗或飞盘。最终的隐藏神经元可以学习图像的综合表示,从而使属于不同类别的数据易于区分。
- 缺少的成分:数据
- 图片分辨率
- 数据集
- 存储等
- 缺少的成分:硬件
- CPu
- GPu
7.1.2. AlexNet
AlexNet首次证明了学习到的特征可以超越手工设计的特征。
它一举打破了计算机视觉研究的现状。
从LeNet(左)到AlexNet(右)
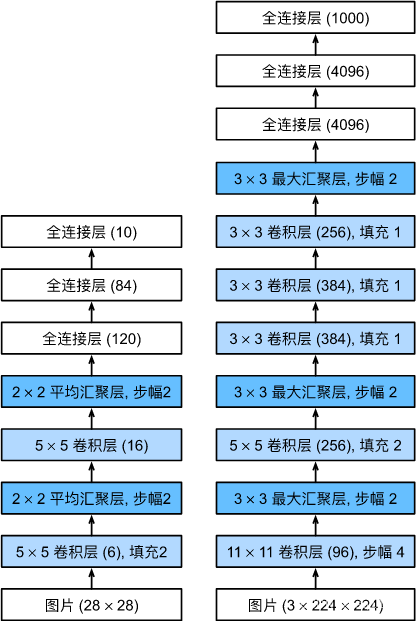
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。 首先,AlexNet比相对较小的LeNet5要深得多。
AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
其次,AlexNet使用ReLU而不是sigmoid作为其激活函数
- 模型设计
- 激活函数:ReLU
- 容量控制和预处理
lexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减。 为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
# 构造一个高度和宽度都为224的单通道数据,来观察每一层输出的形状
X = torch.randn(1, 1, 224, 224)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
#result
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
7.1.3. 读取数据集
使用的是Fashion-MNIST数据集,
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
7.1.4. 训练AlexNet
使用更小的学习速率训练,这是因为网络更深更广、图像分辨率更高,训练卷积神经网络就更昂贵。
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
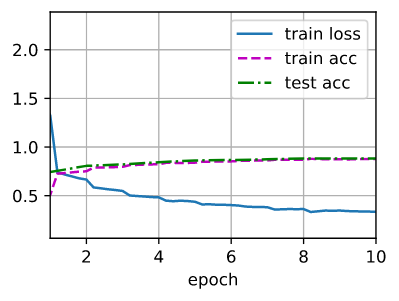
# result
loss 0.327, train acc 0.881, test acc 0.885
4149.6 examples/sec on cuda:0
7.1.5. 小结
-
AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
-
今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
-
尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
-
Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤
















 1963
1963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











