






一、概述
- 概率分类器
在许多分类算法应用中,特征和标签之间的关系并非是决定性的。比如说,我们想预测一个人究竟是否会在泰坦尼克号海难中生存下来,那我们可以建一棵决策树来学习我们的训练集。在训练中,其中一个人的特征为:30岁,男,普通舱,他最后在泰坦尼克号海难中去世了。当我们测试的时候,我们发现有另一个⼈人的特征也为:30岁,男,普通舱。基于在训练集中的学习,我们的决策树必然会给这个人打上标签:去世。然而这个人的真实情况⼀一定是去世了吗?并非如此。
也许这个人是心脏病患者,得到了上救⽣艇的优先权。又有可能,这个人就是挤上了救⽣艇,活了下来。对分类算法来说,基于训练的经验,这个人“很有可能”是没有活下来,但算法永远也无法确定”这个人一定没有活下来“。即便这个人最后真的没有活下来,算法也⽆法确定基于训练数据给出的判断,是否真的解释了这个人没有存活下来的真实情况。这就是说,算法得出的结论,永远不是100%确定的,更多的是判断出了一种“样本的标签更更可能是某类的可能性”,⽽非一种“确定”。我们通过某些规定,⽐如说,在决策树的叶⼦子节点上占比比较多的标签,就是叶⼦子节点上所有样本的标签,来强行让算法为我们返回⼀个固定结果。但许多时候,我们也希望能够理解算法判断出的可能性本身。
2. 相关概念
生成模型:在概率统计理论中, 生成模型是指能够随机生成观测数据的模型,尤其是在给定某些隐含参数的条件下。它给观测值和标注数据序列指定一个联合概率分布。在机器学习中,生成模型可以用来直接对数据建模(例如根据某个变量的概率密度函数进行数据采样),也可以用来建立变量间的条件概率分布。条件概率分布可以由生成模型根据贝叶斯定理形成。常见的基于生成模型算法有高斯混合模型和其他混合模型、隐马尔可夫模型、随机上下文无关文法、朴素贝叶斯分类器、AODE分类器、潜在狄利克雷分配模型、受限玻尔兹曼机。
举例:要确定一个瓜是好瓜还是坏瓜,用判别模型的方法是从历史数据中学习到模型,然后通过提取这个瓜的特征来预测出这只瓜是好瓜的概率,是坏瓜的概率。
判别模型: 在机器学习领域判别模型是一种对未知数据 y 与已知数据 x 之间关系进行建模的方法。判别模型是一种基于概率理论的方法。已知输入变量 x ,判别模型通过构建条件概率分布 P(y|x) 预测 y 。常见的基于判别模型算法有逻辑回归、线性回归、支持向量机、提升方法、条件随机场、人工神经网络、随机森林、感知器。
举例:利用生成模型是根据好瓜的特征首先学习出一个好瓜的模型,然后根据坏瓜的特征学习得到一个坏瓜的模型,然后从需要预测的瓜中提取特征,放到生成好的好瓜的模型中看概率是多少,在放到生产的坏瓜模型中看概率是多少,哪个概率大就预测其为哪个。
生成模型是所有变量的全概率模型,而判别模型是在给定观测变量值前提下目标变量条件概率模型。因此生成模型能够用于模拟(即生成)模型中任意变量的分布情况,而判别模型只能根据观测变量得到目标变量的采样。判别模型不对观测变量的分布建模,因此它不能够表达观测变量与目标变量之间更复杂的关系。因此,生成模型更适用于无监督的任务,如分类和聚类。
3. 先验概率、条件概率
条件概率: 就是事件A在事件B发生的条件下发生的概率。条件概率表示为P(A|B),读作“A在B发生的条件下发生的概率”。
先验概率: 在贝叶斯统计中,某一不确定量 p 的先验概率分布是在考虑"观测数据"前,能表达 p 不确定性的概率分布。它旨在描述这个不确定量的不确定程度,而不是这个不确定量的随机性。这个不确定量可以是一个参数,或者是一个隐含变量。
后验概率: 在贝叶斯统计中,一个随机事件或者一个不确定事件的后验概率是在考虑和给出相关证据或数据后所得到的条件概率。同样,后验概率分布是一个未知量(视为随机变量)基于试验和调查后得到的概率分布。“后验”在本文中代表考虑了被测试事件的相关证据。
通过下述西瓜的数据集来看:
- 条件概率,就是在条件为瓜的颜色是青绿的情况下,瓜是好瓜的概率。
- 先验概率,就是常识、经验、统计学所透露出的“因”的概率,即瓜的颜色是青绿的概率。
- 后验概率,就是在知道“果”之后,去推测“因”的概率,也就是说,如果已经知道瓜是好瓜,那么瓜的颜色是青绿的概率是多少。后验和先验的关系就需要运用贝叶斯决策理论来求解。
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
clf = GaussianNB().fit(X_train, y_train)
print ("Classifier Score:", clf.score(X_test, y_test))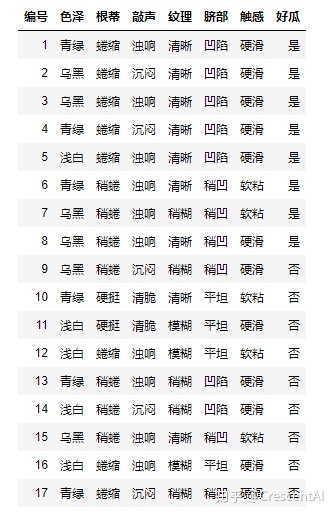
二、朴素⻉贝叶斯是如何⼯工作的
2.1 基本原理概述
在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同。对于大多数的分类算法,比如决策树、KNN、逻辑回归、支持向量量机等,他们都是判别方法,也就是直接学习出特征输出Y和特征X之间的关系,要么是决策函数
2.2 贝叶斯公式
⻉叶斯学派的思想可以概括为「先验概率+数据=后验概率」。也就是说我们在实际问题中需要得到的后验概率,可以通过先验概率和数据一起综合得到。数据大家好理解,被频率学派攻击的是先验概率,⼀般来说先验概率就是我们对于数据所在领域的历史经验,但是这个经验常常难以量化或者模型化,于是贝叶斯学派大胆的假设先验分布的模型,比如正态分布、beta分布等。这个假设一般没有特定的依据,因此一直被频率学派认为很荒谬。虽然难以从严密的数学逻辑里推出贝叶斯学派的逻辑,但是在很多实际应用中,贝叶斯理论很好用,⽐如垃圾邮件分类,⽂本分类等。
我们先看看条件独立公式,如果X和Y相互独⽴立,它们的联合概率
在概率论中,我们可以证明,两个事件的联合概率等于这两个事件任意条件概率 * 这个条件事件本身的概率。
接着看看全概率公式:
其中
⽽这个式子,就是我们一切贝叶斯算法的根源理论。我们可以把我们的特征当成是我们的条件事件,而我们要求解的标签当成是我们被满足条件后会被影响的结果,⽽两者之间的概率关系就是
所以条件概率可以理理解为:后验概率=先验概率 * 调整因子
如果可能性函数>1,意味着先验概率被增强,事件的发生的可能性变⼤大;
如果可能性函数=1,意味着 事件无助于判断事件 的可能性;
如果可能性函数<1,意味着先验概率被削弱,事件可能性变⼩小。
三、代码实现
3.1 栗子: 手写数字识别
数据是标记过的手写数字的图片,即采集足够多的手写样本,选择合适模型,进行模型训练,最后验证手写识别程序的正确性。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X, y = digits.data, digits.target
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)将数据所代表的图片显示出来
%matplotlib inline
from matplotlib import pyplot as plt
images_and_labels = list(zip(digits.images,digits.target))
plt.figure(figsize=(8,6),dpi=200) # 宽高,单位是inches, 分辨率
for index, (image,label) in enumerate(images_and_labels[:12]):
plt.subplot(3,4,index+1) # 行数,列数(从1开始),第几张图(按行数)
plt.axis("off") # 关闭坐标轴
plt.imshow(image,cmap=plt.cm.gray_r,interpolation="nearest")
# cmap设置色图到灰色 interpolation 像素间颜色连接方法
plt.title("Digit: %i" % label, fontsize=20)
- 图片数据一般使用像素点作为特征,然后由于图片的特殊性,相邻像素点间的数值(RGB三通道色)往往是接近的,故可以采用矩阵变换的方法压缩矩阵,得到相对较少的特征数
- 数据总共包含1797张图片,每张图片的尺寸是8×88×8像素大小,共有十个分类(0-9),每个分类约180个样本.
- 所有的图片数据保存在digits,image里.数据分析的时候需要转换成单一表格,即行为样本列为特征(类似的还有文档词矩阵),此案例中这个表格已经在digits.data里,可以通过digits.data.shape查看数据格式
print("shape of raw image data: {0}".format(digits.images.shape))
print("shape of data: {0}".format(digits.data.shape))
gnb = GaussianNB().fit(Xtrain,Ytrain)
# 查看分数
acc_score = gnb.score(Xtest,Ytest)
acc_score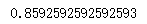
# 查看预测结果
Y_pred = gnb.predict(Xtest)
# 查看预测的概率结果
prob = gnb.predict_proba(Xtest)
prob.shape # 每一列对应一个标签下的概率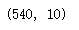
prob[1,:].sum() # 每一行的和都是一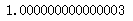
prob.sum(axis=1)
from sklearn.metrics import confusion_matrix as CM
CM(Ytest,Y_pred)
# 注意,ROC曲线是不能用于多分类的。多分类状况下最佳的模型评估指标是混淆矩阵和整体的准确度
3.2 多项式朴素贝叶斯
多项式贝叶斯可能是除了高斯之外,最为人所知的贝叶斯算法了。它也是基于原始的贝叶斯理论,但假设概率分布是服从一个简单多项式分布。多项式分布来源于统计学中的多项式实验,这种实验可以具体解释为:实验包括n次重复试验,每项试验都有不同的可能结果。在任何给定的试验中,特定结果发生的概率是不变的。
举个例子,比如说一个特征矩阵
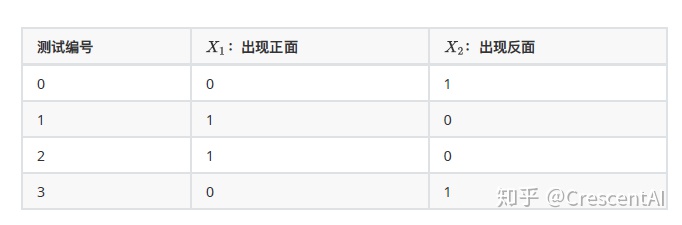
假设另一个特征
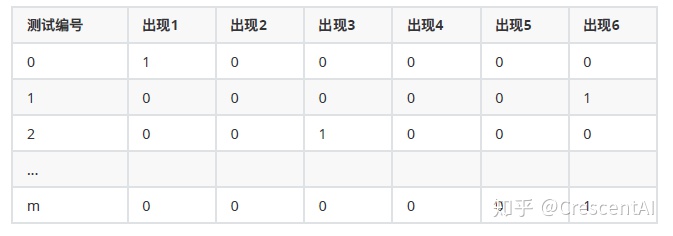
可以看出:
- 多项式分布擅长的是分类型变量,在其原假设中,
的概率是离散的,并且不同
下的
- 多项式实验中的实验结果都很具体,它所涉及的特征往往是次数,频率,计数,出现与否这样的概念,这些概念都是离散的正整数,因此sklearn中的多项式朴素贝叶斯不接受负值的输入。
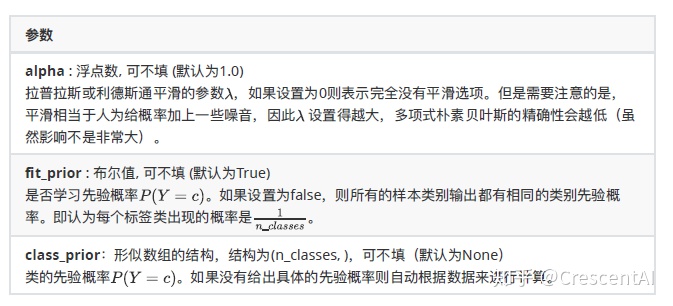
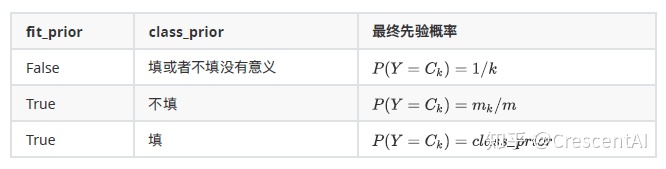
布尔参数fit_prior表示是否要考虑先验概率,如果是False,则所有的样本类别输出都有相同的类别先验概率。否则,可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB⾃己从训练集样本来计算先验概率,此时的先验概率为
# 1 导入需要的模块和库
from sklearn.preprocessing import MinMaxScaler
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
# 2 建立数据集
class_1 = 500
class_2 = 500 # 两个类别分别设定500个样本
centers = [[0.0, 0.0], [2.0, 2.0]] # 设定两个类别的中心
clusters_std = [0.5, 0.5] # 设定两个类别的方差
X, y = make_blobs(n_samples=[class_1, class_2],
centers=centers,
cluster_std=clusters_std,
random_state=0, shuffle=False)
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y
,test_size=0.3
,random_state=420)
np.unique(Ytrain)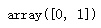
(Ytrain == 1).sum()/Ytrain.shape[0]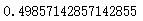
# 3 先归一化,保证输入多项式朴素贝叶斯的特征矩阵中不带有负数
mms = MinMaxScaler().fit(Xtrain)
Xtrain_ = mms.transform(Xtrain)
Xtest_ = mms.transform(Xtest)
# 4 建立一个多项式朴素贝叶斯分类器器
mnb = MultinomialNB().fit(Xtrain_, Ytrain)
# 重要属性:调用根据数据获取的,每个标签类的对数先验概率log(P(Y))
# 由于概率永远是在[0,1]之间,因此对数先验概率返回的永远是负值
mnb.class_log_prior_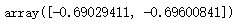
mnb.class_log_prior_.shape# 可以使用np.exp来查看真正的概率值
np.exp(mnb.class_log_prior_)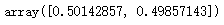
# 重要属性:返回一个固定标签类别下的每个特征的对数概率log(P(Xi|y))
mnb.feature_log_prob_
mnb.feature_log_prob_.shape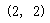
# 重要属性:在fit时每个标签类别下包含的样本数
# 当fit接口中的sample_weight被设置时,该接口返回的值也会受到加权的影响
mnb.class_count_
mnb.class_count_.shape# 5 那分类效果如何呢?
# 一些传统的接口
mnb.predict(Xtest_)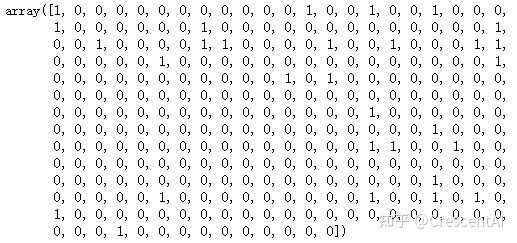
mnb.predict_proba(Xtest_)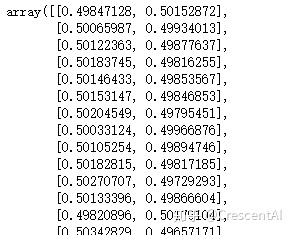
mnb.score(Xtest_,Ytest)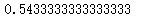
# 6 效果不不太理理想,思考⼀一下多项式⻉贝叶斯的性质,我们能够做点什什么呢?
# 来试试看把Xtiain转换成分类型数据吧
# 注意我们的Xtrain没有经过归一化,因为做哑变量之后自然所有的数据就不会又负数了
from sklearn.preprocessing import KBinsDiscretizer
kbs = KBinsDiscretizer(n_bins=10, encode='onehot').fit(Xtrain)
Xtrain_ = kbs.transform(Xtrain)
Xtest_ = kbs.transform(Xtest)
mnb = MultinomialNB().fit(Xtrain_, Ytrain)
mnb.score(Xtest_,Ytest)
3.3 伯努利朴素贝叶斯
多项式朴素贝叶斯可同时处理二项分布(抛硬币)和多项分布(掷骰子),其中二项分布又叫做伯努利分布,它是一种现实中常见,并且拥有很多优越数学性质的分布。因此,既然有着多项式朴素贝叶斯,我们自然也就又专门用来处理二项分布的朴素贝叶斯:伯努利朴素贝叶斯。
伯努利⻉叶斯类BernoulliN假设数据服从多元伯努利分布,并在此基础上应用朴素贝叶斯的训练和分类过程。多元伯努利分布简单来说,就是数据集中可以存在多个特征,但每个特征都是二分类的,可以以布尔变量表示,也可以表示为{0,1}或者{-1,1}等任意二分类组合。因此,这个类要求将样本转换为二分类特征向量量,如果数据本身不是二分类的,那可以使用类中专门用来二值化的参数binarize来改变数据。
伯努利朴素贝叶斯与多项式朴素贝叶斯非常相似,都常用于处理文本分类数据。但由于伯努利朴素贝叶斯是处理理二项分布,所以它更加在意的是“存在与否”,而不是“出现多少次”这样的次数或频率,这是伯努利贝叶斯与多项式贝叶斯的根本性不不同。在文本分类的情况下,伯努利朴素贝叶斯可以使用单词出现向量(⽽不是单词计数向量)来训练分类器。⽂档较短的数据集上,伯努利利朴素贝叶斯的效果会更加好。如果时间允许,建议两种模型都试试看。
来看看伯努利利朴素⻉贝叶斯类的参数:

from sklearn.naive_bayes import BernoulliNB
# 普通来说我们应该使用二值化的类sklearn.preprocessing.Binarizer来将特征一个个二值化
# 然而这样效率过低,因此我们选择归一化之后直接设置一个阈值
mms = MinMaxScaler().fit(Xtrain)
Xtrain_ = mms.transform(Xtrain)
Xtest_ = mms.transform(Xtest)
# 不设置二值化
bnl_ = BernoulliNB().fit(Xtrain_, Ytrain)
bnl_.score(Xtest_,Ytest)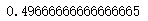
# 设置二值化阈值为0.5
bnl = BernoulliNB(binarize=0.5).fit(Xtrain_, Ytrain)
bnl.score(Xtest_,Ytest)
3.4 ROC曲线
该曲线的横坐标为假正率(False Positive Rate, FPR),N是真实负样本的个数,FP是N个负样本中被分类器器预测为正样本的个数。

纵坐标为真正率(True Positive Rate, TPR):
P是真实正样本的个数,TP是P个正样本中被分类器器预测为正样本的个数。
# 设置二值化阈值为0.5
bnl = BernoulliNB(binarize=0.5).fit(Xtrain_, Ytrain)
y_pred = bnl.predict(Xtest_)
y_pred
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from sklearn.metrics import roc_curve, auc # 计算roc和auc
fpr,tpr,threshold = roc_curve(Ytest,y_pred) # 计算真正率和假正率
roc_auc = auc(fpr,tpr) # 计算auc的值
plt.figure()
lw = 2
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc) # 假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()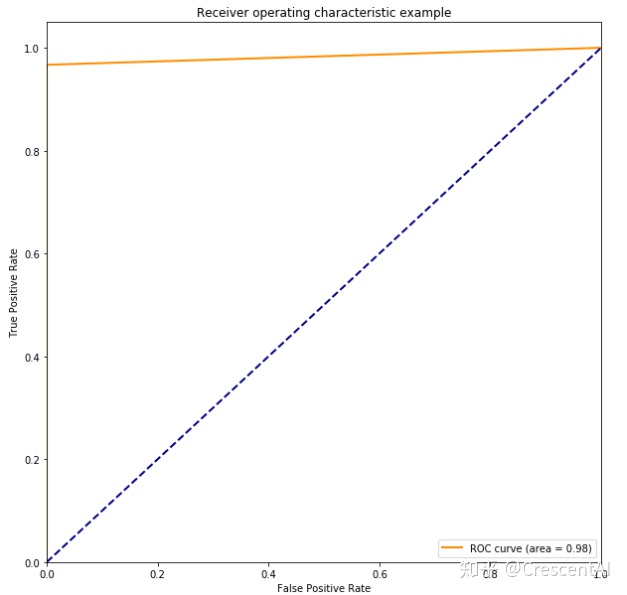
3.5 样本不均衡问题下的对比
# 1 导⼊入需要的模块,建⽴立样本不不平衡的数据集
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.metrics import recall_score,roc_auc_score as AUC
class_1 = 50000 #多数类为50000个样本
class_2 = 500 #少数类为500个样本
centers = [[0.0, 0.0], [5.0, 5.0]] #设定两个类别的中心
clusters_std = [3, 1] #设定两个类别的方差
X, y = make_blobs(n_samples=[class_1, class_2],
centers=centers,
cluster_std=clusters_std,
random_state=0, shuffle=False)
X.shape
np.unique(y)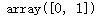
# 2 查看所有⻉贝叶斯在样本不不平衡数据集上的表现
name = ["Multinomial","Gaussian","Bernoulli"]
models = [MultinomialNB(),GaussianNB(),BernoulliNB()]
for name,clf in zip(name,models):
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y
,test_size=0.3
,random_state=420)
if name != "Gaussian":
kbs = KBinsDiscretizer(n_bins=10, encode='onehot').fit(Xtrain)
Xtrain = kbs.transform(Xtrain)
Xtest = kbs.transform(Xtest)
clf.fit(Xtrain,Ytrain)
y_pred = clf.predict(Xtest)
proba = clf.predict_proba(Xtest)[:,1]
score = clf.score(Xtest,Ytest)
print(name)
print("\tAccuracy:{:.3f}".format(score))
print("\tRecall:{:.3f}".format(recall_score(Ytest,y_pred)))
print("\tAUC:{:.3f}".format(AUC(Ytest,proba)))
从结果上来看,多项式朴素贝叶斯判断出了所有的多数类样本,但放弃了全部的少数类样本,受到样本不均衡问题影响最严重。高斯比多项式在少数类的判断上更加成功一些,至少得到了43.8%的recall。伯努利贝叶斯虽然整体的准确度不如多项式和高斯朴素贝叶斯,但至少成功捕捉出了77.1%的少数类。可见,伯努利贝叶斯最能够忍受样本不不均衡问题。
可是,伯努利⻉叶斯只能用于处理二项分布数据,在现实中,强行将所有的数据都二值化不会永远得到好结果,在我们有多个特征的时候,我们更需要一个个去判断究竟二值化的阈值该取多少才能够让算法的效果优秀。这样做无疑是非常低效的。那如果我们的目标是捕捉少数类,我们应该怎么办呢?高斯朴素贝叶斯的效果虽然比多项式好,但是也没有好到可以用来帮助我们捕捉少数类的程度43.8%,还不如抛硬币的结果。因此,孜孜不不倦的统计学家们改进了朴素⻉贝叶斯算法,修正了包括无法处理样本不平衡在内的传统朴素贝叶斯的众多缺点,得到了一些新兴贝叶斯算法,比如补集朴素贝叶斯等。
四、 优缺点
优点
- 朴素贝叶斯模型有稳定的分类效率。
- 对小规模的数据表现很好,能处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
- 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
- 需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
- 由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
- 对输入数据的表达形式很敏感。
五、 参考文献
西瓜书
https://samanthachen.github.io/2016/08/05/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0_%E5%91%A8%E5%BF%97%E5%8D%8E_%E7%AC%94%E8%AE%B07/














 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









