






Pascal VOC转COCO格式亲测有效
Pascal VOC数据集下载
1、这三个网址就是数据集的下载网址。
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
2、复制其中一条到迅雷下载中,左上角加号出现如图画面,将链接复制进去就开始下载了。
4、迅雷不限速,下载速度非常快,结果展示
原文链接:https://blog.csdn.net/xuechenxing/article/details/90736328
检查VOC数据集并转换为COCO格式
CheckVOC
# https://blog.csdn.net/weixin_40756000/article/details/124462871
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import cv2
import matplotlib.pyplot as plt
from math import sqrt as sqrt
print(os.getcwd())
# 需要检查的数据
sets = [('2007', 'train'), ('2007', 'val')]
# 需要检查的类别
classes = ['face', 'face_mask']
if __name__ == '__main__':
# GT框宽高统计
width = []
height = []
for year, image_set in sets:
# 图片ID不带后缀
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
for image_id in image_ids:
# 图片的路径
img_path = 'VOC%s/JPEGImages/%s.jpg'%(year, image_id)
# 这张图片的XML标注路径
label_file = open('VOC%s/Annotations/%s.xml' % (year, image_id))
tree = ET.parse(label_file)
root = tree.getroot()
try:
size = root.find('size') # 图像的size
img_w = int(size.find('width').text) # 宽
img_h = int(size.find('height').text) # 高
img = cv2.imread(img_path)
except:
print(image_id)
continue
for obj in root.iter('object'): # 解析object字段
difficult = obj.find('difficult').text
cls = obj.find('name').text #
if cls not in classes or int(difficult) == 2:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
xmin = int(xmlbox.find('xmin').text)
ymin = int(xmlbox.find('ymin').text)
xmax = int(xmlbox.find('xmax').text)
ymax = int(xmlbox.find('ymax').text)
obj_w = xmax - xmin
obj_h = ymax - ymin
# width.append(w)
# height.append(h)
img = cv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 255, 0), 3) # 对应目标上画框
# resize图和目标框到固定值
try:
w_change = (obj_w / img_w) * 416
except:
print(image_id)
h_change = (obj_h / img_h) * 416
# width.append(w_change)
# height.append(h_change)
s = w_change * h_change
width.append(sqrt(s))
height.append(w_change / h_change)
# print(img_path)
img = cv2.resize(img, (608, 608))
cv2.imshow('result', img)
cv2.waitKey()
plt.plot(width, height, 'ro')
plt.show()
VOC2COCO
# https://blog.csdn.net/weixin_40756000/article/details/124462871
# 有改动!注意:img_id不能是str类型,必须转为int,否则在用pycocotools时会出现不能读取的错误
# coding:utf-8
# pip install lxml
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"info": ['none'], "license": ['none'], "images": [], "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
image_id = filename.split('.')[0]
image_id = int(image_id)
# print('filename is {}'.format(image_id))
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert (xmax > xmin), "xmax <= xmin, {}".format(line)
assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
# xml标注文件夹
xml_dir = './Annotations'
# 训练数据的josn文件
save_json_train = './train.json'
# 验证数据的josn文件
save_json_val = './val.json'
# 验证数据的test文件
save_json_test = './test.json'
# 类别,如果是多个类别,往classes中添加类别名字即可,比如['dog', 'person', 'cat']
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
only_care_pre_define_categories = True
# 训练数据集比例
train_ratio = 0.8
val_ratio = 0.1
print('xml_dir is {}'.format(xml_dir))
xml_list = glob.glob(xml_dir + "/*.xml")
xml_list = np.sort(xml_list)
# print('xml_list is {}'.format(xml_list))
np.random.seed(100)
np.random.shuffle(xml_list)
train_num = int(len(xml_list) * train_ratio)
val_num = int(len(xml_list) * val_ratio)
print('训练样本数目是 {}'.format(train_num))
print('验证样本数目是 {}'.format(val_num))
print('测试样本数目是 {}'.format(len(xml_list) - train_num - val_num))
xml_list_val = xml_list[:val_num]
xml_list_train = xml_list[val_num:train_num + val_num]
xml_list_test = xml_list[train_num + val_num:]
# 对训练数据集对应的xml进行coco转换
convert(xml_list_train, save_json_train)
# 对验证数据集的xml进行coco转换
convert(xml_list_val, save_json_val)
# 对测试数据集的xml进行coco转换
convert(xml_list_test, save_json_test)
记录一下这里出现的问题,在使用pycocotools检验coco格式是否正确时出现的bug:
imgIds只能是int array,在原来的代码中,直接使用图片名作为imgId,是str格式,检验时会出现错误
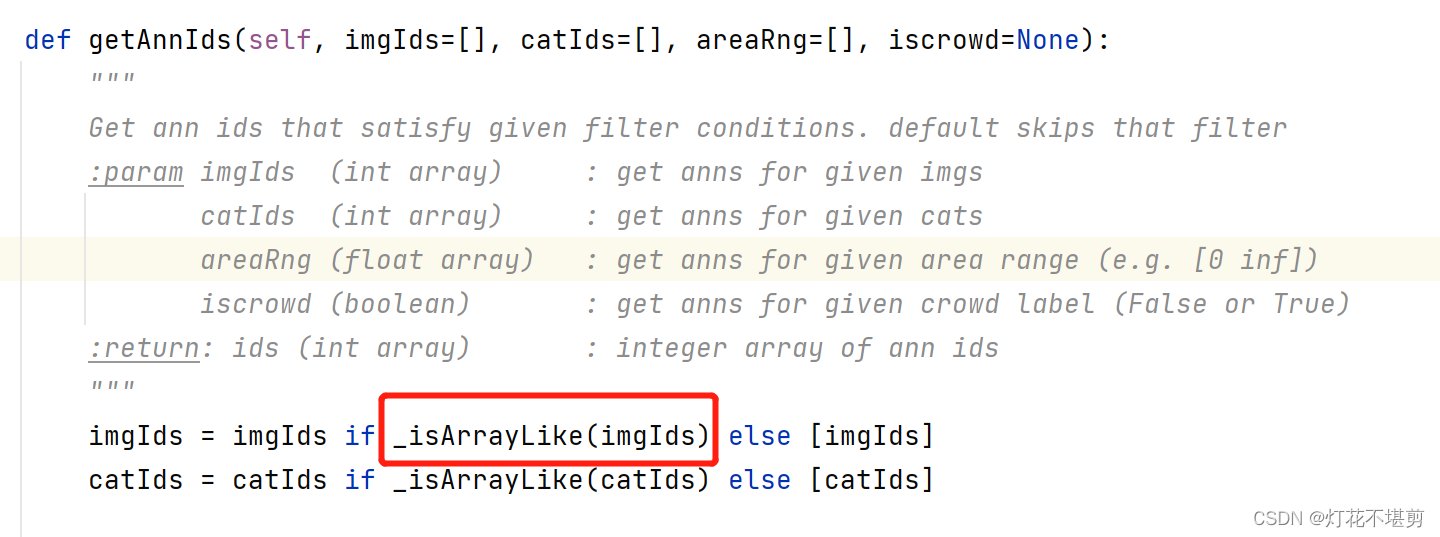

检验COCO格式是否正确
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "VOC2007/train.json"
img_path = "VOC2007/train"
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# draw box to image
for target in targets:
x, y, w, h = target["bbox"]
x1, y1, x2, y2 = x, y, int(x + w), int(y + h)
draw.rectangle((x1, y1, x2, y2))
draw.text((x1, y1), coco_classes[target["category_id"]])
# show image
plt.imshow(img)
plt.show()















 3693
3693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









